“When there’s something we think could be better, we must make an
effort to try and make it better.”
– John Coltrane
Ever since Max Mathews made his first sound on a computer in 1957 at Bell Telephone Laboratories, there has been an increasing appeal and effort for using machines in the disciplines that involve music, whether composing, performing, or listening. This thesis is an attempt at bringing together all three facets by closing the loop that can make a musical system entirely autonomous (Figure 1-2). A complete survey of precedents in each field goes well beyond the scope of this dissertation. This chapter only reviews some of the most related and inspirational works for the goals of this thesis, and finally presents the framework that ties the rest of the document together.
Musical composition has historically been considered at a symbolic, or conventional level, where score information (i.e., pitch, duration, dynamic material, and instrument, as defined in the MIDI specifications) is the output of the compositional act. The formalism of music, including the system of musical sounds, intervals, and rhythms, goes as far back as ancient Greeks, to Pythagoras, Ptolemy, and Plato, who thought of music as inseparable from numbers. The automation of composing through formal instructions comes later with the canonic composition of the 15th century, and leads to what is now referred to as algorithmic composition. Although it is not restricted to computers1, using algorithmic programming methods as pioneered by Hiller and Isaacson in “Illiac Suite” (1957), or Xenakis in “Atrées” (1962), has “opened the door to new vistas in the expansion of the computer’s development as a unique instrument with significant potential” [31].
Computer-generated, automated composition can be organized into three main categories: stochastic methods, which use sequences of jointly distributed random variables to control specific decisions (Aleatoric movement); rule-based systems, which use a strict grammar and set of rules (Serialism movement); and artificial intelligence approaches, which differ from rule-based approaches mostly by their capacity to define their own rules: in essence, to “learn.” The latter is the approach that is most significant to our work, as it aims at creating music through unbiased techniques, though with intermediary MIDI representation.
Probably the most popular example is David Cope’s system called “Experiments in Musical Intelligence” (EMI). EMI analyzes the score structure of a MIDI sequence in terms of recurring patterns (a signature), creates a database of the meaningful segments, and “learns the style” of a composer, given a certain number of pieces [32]. His system can generate compositions with surprising stylistic similarities to the originals. It is, however, unclear how automated the whole process really is, and if the system is able to extrapolate from what it learns.
A more recent system by Francois Pachet, named “Continuator” [122], is capable of learning live the improvisation style of a musician who plays on a polyphonic MIDI instrument. The machine can “continue” the improvisation on the fly, and performs autonomously, or under user guidance, yet in the style of its teacher. A particular parameter controls the “closeness” of the generated music, and allows for challenging interactions with the human performer.
George Lewis, trombone improviser and composer, is a pioneer in building computer programs that create music by interacting with a live performer through acoustics. The so-called “Voyager” software listens via a microphone to his trombone improvisation, and comes to quick conclusions about what was played. It generates a complex response that attempts to make appropriate decisions about melody, harmony, orchestration, ornamentation, rhythm, and silence [103]. In Lewis’ own words, “the idea is to get the machine to pay attention to the performer as it composes.” As the performer engages in a dialogue, the machine may also demonstrate an independent behavior that arises from its own internal processes.
The so-called “Hyperviolin” developed at MIT [108] uses multichannel audio input and perceptually-driven processes (i.e., pitch, loudness, brightness, noisiness, timbre), as well as gestural data input (bow position, speed, acceleration, angle, pressure, height). The relevant but high dimensional data stream unfortunately comes together with the complex issue of mapping that data to meaningful synthesis parameters. Its latest iteration, however, features an unbiased and unsupervised learning strategy for mapping timbre to intuitive and perceptual control input (section 2.3).
The piece “Sparkler” (composed by Tod Machover) exploits similar techniques, but for a symphony orchestra [82]. Unlike many previous works where only solo instruments are considered, in this piece a few microphones capture the entire orchestral sound, which is analyzed into perceptual data streams expressing variations in dynamics, spatialization, and timbre. These instrumental sound masses, performed with a certain freedom by players and conductor, drive a MIDI-based generative algorithm developed by the author. It interprets and synthesizes complex electronic textures, sometimes blending, and sometimes contrasting with the acoustic input, turning the ensemble into a kind of “Hyperorchestra.”
These audio-driven systems employ rule-based generative principles for synthesizing music [173][139]. Yet, they differ greatly from score-following strategies in their creative approach, as they do not rely on aligning pre-composed material to an input. Instead, the computer program is the score, since it describes everything about the musical output, including notes and sounds to play. In such a case, the created music is the result of a compositional act by the programmer. Pushing even further, Lewis contends that:
“[...] notions about the nature and function of music are embedded in the structure of software-based music systems, and interactions with these systems tend to reveal characteristics of the community of thought and culture that produced them. Thus, Voyager is considered as a kind of computer music-making embodying African-American aesthetics and musical practices.” [103]
Analyzing the musical content in audio signals rather than symbolic signals is an attractive idea that requires some sort of perceptual models of listening. Perhaps an even more difficult problem is being able to synthesize meaningful audio signals without intermediary MIDI notation. Most works—often driven by a particular synthesis technique—do not really make a distinction between sound and music.
CNMAT’s Additive Synthesis Tools (CAST) are flexible and generic real-time analysis/resynthesis routines based on sinusoidal decomposition, “Sound Description Interchange Format” (SDIF) content description format [174], and “Open Sound Control” (OSC) communication protocol [175]. The system can analyze, modify, and resynthesize a live acoustic instrument or voice, encouraging a dialogue with the “acoustic” performer. Nonetheless, the synthesized music is controlled by the “electronic” performer who manipulates the interface. As a result, performers remain in charge of the music, while the software generates the sound.
The Spectral Modeling Synthesis (SMS) technique initiated in 1989 by Xavier Serra is a powerful platform for the analysis and resynthesis of monophonic and polyphonic audio [149][150]. Through decomposition into its deterministic and stochastic components, the software enables several applications, including time scaling, pitch shifting, compression, content analysis, sound source separation, instrument modeling, and timbre morphing.
The Perceptual Synthesis Engine (PSE), developed by the author, is an extension of SMS for monophonic sounds [79][83]. It first decomposes the audio recording into a set of streaming signal coefficients (frequencies and amplitudes of sinusoidal functions) and their corresponding perceptual correlates (instantaneous pitch, loudness, and brightness). It then learns the relationship between the two data sets: the high-dimensional signal description, and the low-dimensional perceptual equivalent. The resulting timbre model allows for greater control over the sound than previous methods by removing the time dependency from the original file2. The learning is based on a mixture of Gaussians with local linear models and converges to a unique solution through the Expectation-Maximization (EM) algorithm. The outcome is a highly compact and unbiased synthesizer that enables the same applications as SMS, with intuitive control and no time-structure limitation. The system runs in real time and is driven by audio, such as the acoustic or electric signal of traditional instruments. The work presented in this dissertation is, in a sense, a step towards extending this monophonic timbre model to polyphonic structured music.
Methods based on data-driven concatenative synthesis typically discard the notion of analytical transcription, but instead, they aim at generating a musical surface (i.e., what is perceived) through a set of compact audio descriptors, and the concatenation of sound samples. The task consists of searching through a sound database for the most relevant segments, and of sequencing the small units granularly, so as to best match the overall target data stream. The method was first developed as part of a text-to-speech (TTS) system, which exploits large databases of speech phonemes in order to reconstruct entire sentences [73].
Schwarz’s “Caterpillar” system [147] aims at synthesizing monophonic musical phrases via the concatenation of instrumental sounds characterized through a bank of descriptors, including: unit descriptors (location, duration, type); source descriptors (sound source, style); score descriptors (MIDI note, polypho-ny, lyrics); signal descriptors (energy, fundamental frequency, zero crossing rate, cutoff frequency); perceptual descriptors (loudness, sharpness, timbral width); spectral descriptors (centroid, tilt, spread, dissymmetry); and harmonic descriptors (energy ratio, parity, tristimulus, deviation). The appropriate segments are selected through constraint-solving techniques, and aligned into a continuous audio stream.
Zils and Pachet’s “Musical Mosaicing” [181] aims at generating music from arbitrary audio segments. A first application uses a probabilistic generative algorithm to compose the music, and an overlap-add technique for synthesizing the sound. An overall measure of concatenation quality and a constraint-solving strategy for sample selection insures a certain continuity in the stream of audio descriptors. A second application uses a target song as the overall set of constraints instead. In this case, the goal is to replicate an existing audio surface through granular concatenation, hopefully preserving the underlying musical structures (section 6.5).
Lazier and Cook’s “MoSievius” system [98] takes up the same idea, and allows for real-time interactive control over the mosaicing technique by fast sound sieving: a process of isolating sub-spaces as inspired by [161]. The user can choose input and output signal specifications in real time in order to generate an interactive audio mosaic. Fast time-stretching, pitch shifting, and k-nearest neighbor search is provided. An (optionally pitch-synchronous) overlap-add technique is used for synthesis. Only few or no audio examples for Schwarz's, Zils's, and Lazier’s systems are available.
The current proliferation of compressed digital formats, peer-2-peer networks, and online music services is transforming the way we handle music, and increases the need for automatic management technologies. Music Information Retrieval (MIR) is looking into describing the bits of the digital music in ways that facilitate searching through this abundant world without structure. The signal is typically tagged with additional information called metadata (data about the data). This is the endeavor of the MPEG-7 file format, of which the goal is to enable content-based search and novel applications. Still, no commercial use of the format has yet been proposed. In the following paragraphs, we briefly describe some of the most popular MIR topics.
The “Music Browser,” developed by Sony CSL, IRCAM, UPF, Fraunhofer, and others, as part of a European effort (Cuidado, Semantic Hi-Fi) is the “first entirely automatic chain for extracting and exploiting musical metadata for browsing music” [124]. It incorporates several techniques for music description and data mining, and allows for a variety of queries based on editorial (i.e., entered manually by an editor) or acoustic metadata (i.e., the sound of the sound), as well as providing browsing tools and sharing capabilities among users.
Although this thesis deals exclusively with the extraction and use of acoustic metadata, music as a whole cannot be solely characterized by its “objective” content. Music, as experienced by listeners, carries much “subjective” value that evolves in time through communities. Cultural metadata attached to music can be extracted online in a textual form through web crawling and natural-language processing [125][170]. Only a combination of these different types of metadata (i.e., acoustic, cultural, editorial) can lead to viable music management and retrieval systems [11][123][169].
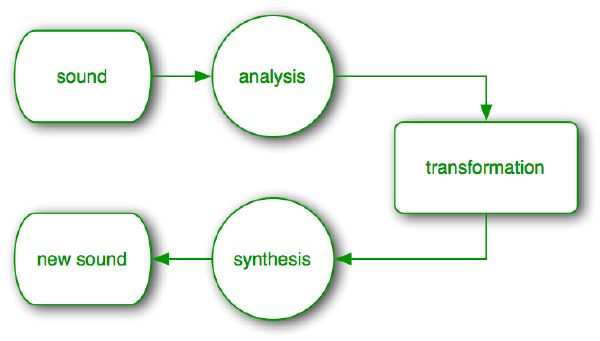
Much work has already been done under the general paradigm of analysis/resyn-thesis. As depicted in Figure 2-1, the idea is first to break down a sound into some essential, quantifiable components, e.g., amplitude and phase partial coefficients. These are usually altered in some way for applications including time stretching, pitch shifting, timbre morphing, or compression. Finally, the transformed parameters are reassembled into a new sound through a synthesis procedure, e.g., additive synthesis. The phase vocoder [40] is an obvious example of this procedure where the new sound is directly an artifact of the old sound via some describable transformation.
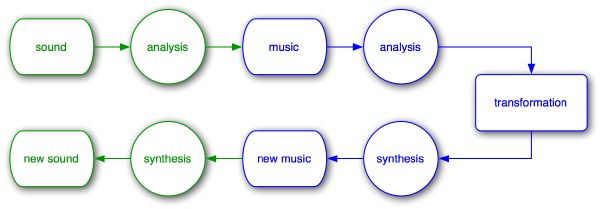
The mechanism applies well to the modification of audio signals in general, but is generally blind3 regarding the embedded musical content. We introduce an extension of the sound analysis/resynthesis principle for music (Figure 2-2). Readily, our music-aware analysis/resynthesis approach enables higher-level transformations independently of the sound content, including beat matching, music morphing, music cross-synthesis, music similarities.
The analysis framework characterizing this thesis work is the driving force of the synthesis focus of section 6, and it can be summarized concisely by the following quote:
”Everything should be made as simple as possible but not simpler.”
– Albert Einstein
We seek to simplify the information of interest to its minimal form. Depending on the application, we can choose to approximate or discard some of that information, consequently degrading our ability to resynthesize. Reconstructing the original signal as it reaches the ear is a signal modeling problem. If the source is available though, the task consists of labeling the audio as it is being perceived: a perception modeling problem. Optimizing the amount of information required to describe a signal of given complexity is the endeavor of information theory [34]: here suitably perceptual information theory.
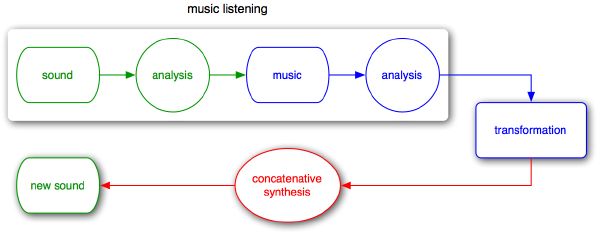
Our current implementation uses concatenative synthesis for resynthesizing rich sounds without having to deal with signal modeling (Figure 2-3). Given the inherent granularity of concatenative synthesis, we safely reduce the description further, resulting into our final acoustic metadata, or music characterization.
|
|
We extend the traditional music listening scheme as described in [142] with a learning extension to it. Indeed, listening cannot be disassociated from learning. Certain problems such as, for example, downbeat prediction, cannot be fully solved without this part of the framework (section 5.3).
Understanding the mechanisms of the brain, in particular the auditory path, is the ideal basis for building perceptual models of music cognition. Although particular models have great promises [24][25], it is still a great challenge to make these models work in real-world applications today. However, we can attempt to mimic some of the most basic functionalities of music perception, and build a virtual listener that will process, interpret, and describe music signals much as humans do; that is, primarily, from the ground-up.
The model depicted below, inspired by some empirical research on human listening and learning, may be considered the first practical attempt at implementing a “music cognition machine.” Although we implement most of the music listening through deterministic signal processing algorithms, we believe that the whole process may eventually be solved via statistical learning approaches [151]. But, since our goal is to make music, we favor practicality over a truly uniform approach.
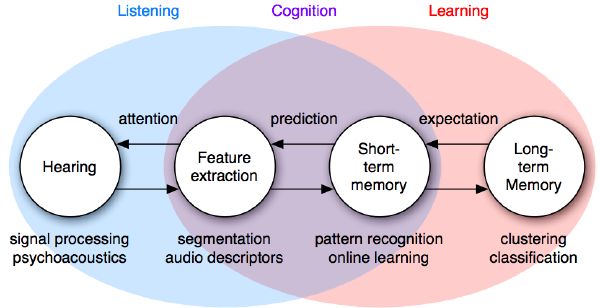
We propose a four-building-block diagram, where each block represents a signal reduction stage of another. Information flows from left to right between each stage and always corresponds to a simpler, more abstract, and slower-rate signal (Figure 2-4). Each of these four successive stages—hearing, feature extraction, short-term memory, and long-term memory—embodies a different concept, respectively: filtering, symbolic representation, time dependency, and storage. The knowledge is re-injected to some degree through all stages via a top-down feedback loop.
The first three blocks roughly represent what is often referred to as listening, whereas the last three blocks represent what is often referred to as learning. The interaction between music listening and music learning (the overlapping area of our framework schematic) is what we call music cognition, where most of the “interesting” musical phenomena occur. Obviously, the boundaries of music cognition are not very well defined and the term should be used with great caution. Note that there is more to music cognition than the signal path itself. Additional external influences may act upon the music cognition experience, including vision, culture, emotions, etc., but these are not represented here.
This is a filtering stage, where the output signal only carries what we hear. The ear being physiologically limited, only a portion of the original signal is actually heard (in terms of coding, this represents less than 10% of the incoming signal). The resulting signal is presented in the form of an auditory spectrogram, where what appears in the time-frequency display corresponds strictly to what is being heard in the audio. This is where we implement psychoacoustics as in [183][116][17]. The analysis period here is on the order of 10 ms.
This second stage converts the auditory signal into a symbolic representation. The output is a stream of symbols describing the music (a sort of “musical-DNA” sequence). This is where we could implement sound source separation. Here we may extract perceptual features (more generally audio descriptors) or we describe the signal in the form of a musical surface. In all cases, the output of this stage is a much more compact characterization of the musical content. The analysis period is on the order of 100 ms.
The streaming music DNA is analyzed in the time-domain during this third stage. The goal here is to detect patterns and redundant information that may lead to certain expectations, and to enable prediction. Algorithms with a built-in temporal component, such as symbolic learning, pattern matching, dynamic programming or hidden Markov models are especially applicable here [137][89][48]. The analysis period is on the order of 1 sec.
Finally, this last stage clusters the macro information, and classifies the analysis results for long-term learning, i.e., storage memory. All clustering techniques may apply here, as well as regression and classification algorithms, including mixture of Gaussians, artificial neural networks, or support vector machines [42][22][76]. The analysis period is on the order of several seconds or more.
For completeness, all stages must feedback to each other. Indeed, our prior knowledge of the world (memories and previous experiences) alters our listening experience and general musical perception. Similarly, our short-term memory (pattern recognition, beat) drives our future prediction, and finally these may direct our attention (section 5.2).
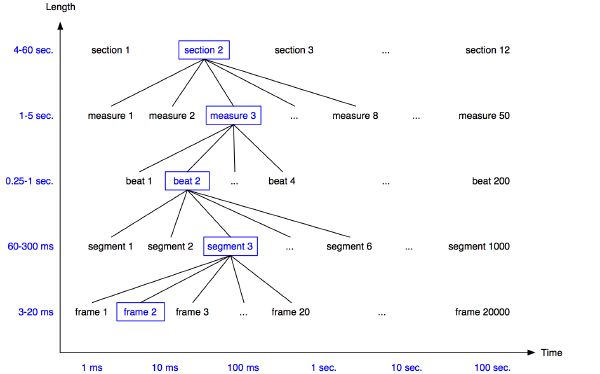
Interestingly, this framework applies nicely to the metrical analysis of a piece of music. By analogy, we can describe the music locally by its instantaneous sound, and go up in the hierarchy through metrical grouping of sound segments, beats, patterns, and finally larger sections. Note that the length of these audio fragments coincides roughly with the analysis period of our framework (Figure 2-5).
Structural hierarchies [112], which have been studied in the frequency domain (relationship between notes, chords, or keys) and the time domain (beat, rhythmic grouping, patterns, macrostructures), reveal the intricate complexity and interrelationship between the various components that make up music. Deliège [36] showed that listeners tend to prefer grouping rules based on attack and timbre over other rules (i.e., melodic and temporal). Lerdahl [101] stated that music structures could not only be derived from pitch and rhythm hierarchies, but also from timbre hierarchies. In auditory scene analysis, by which humans build mental descriptions of complex auditory environments, abrupt events represent important sound source-separation cues [19][20]. We choose to first detect sound events and segment the audio in order to facilitate its analysis, and refine the description of music. This is going to be the recurrent theme throughout this document.
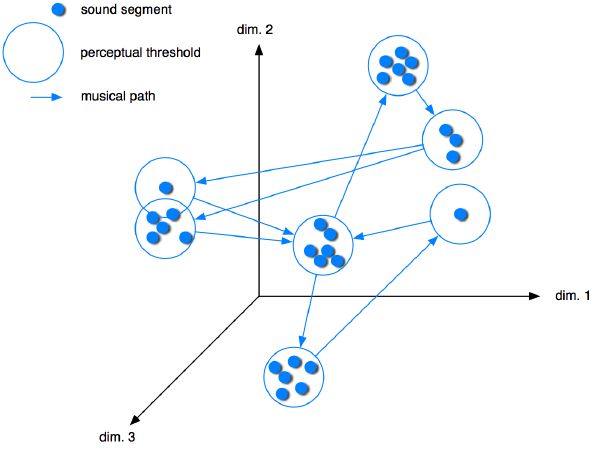
Multidimensional scaling (MDS) is a set of data analysis techniques that display the structure of distance-like data as a geometrical picture, typically into a low dimensional space. For example, it was shown that instruments of the orchestra could be organized in a timbral space of three main dimensions [66][168] loosely correlated to brightness, the “bite” of the attack, and the spectral energy distribution. Our goal is to extend this principle to all possible sounds, including polyphonic and multitimbral.
Sound segments extracted from a piece of music may be represented by data points scattered around a multidimensional space. The music structure appears as a path in the space (Figure 2-6). Consequently, musical patterns materialize literally into geometrical loops. The concept is simple, but the outcome may turn out to be powerful if one describes a complete music catalogue within that common space. Indeed, the boundaries of the space and the dynamics within it determine the extent of knowledge the computer may acquire: in a sense, its influences. Our goal is to learn what that space looks like, and find meaningful ways to navigate through it.
|
|
Obviously, the main difficulty is to define the similarity of sounds in the first place. This is developed in section 4.4. We also extend the MDS idea to other scales of analysis, i.e., beat, pattern, section, and song. We propose a three-way hierarchical description, in terms of pitch, timbre, and rhythm. This is the main topic of chapter 4. Depending on the application, one may project the data onto one of these musical dimensions, or combine them by their significance.
The ultimate goal of this thesis is to characterize a musical space given a large corpus of music titles by only considering the acoustic signal, and to propose novel “active” listening strategies through the automatic generation of new music, i.e., a way to navigate freely through the space. For the listener, the system is the “creator” of personalized music that is derived from his/her own song library. For the machine, the system is a synthesis algorithm that manipulates and combines similarity metrics of a highly constrained sound space.
By only providing machine listening (chapter 3) and machine learning (chapter 5) primitive technologies, it is our goal to build a bias-free system that learns the structure of particular music by only listening to song examples. By considering the structural content of music, our framework enables novel transformations, or music processing, which goes beyond traditional audio processing.
So far, music-listening systems have been implemented essentially to query music information [123]. Much can be done on the generative side of music management through acoustic analysis. In a way, our framework elevates “audio” signals to the rank of “music” signals, leveraging music cognition, and enabling various applications as described in section 6 .