“The secret to creativity is knowing how to hide your sources.”
– Albert Einstein
Can computers be creative? The question drives an old philosophical debate that goes back to Alan Turing’s claim that “a computational system can possess all important elements of human thinking or understanding” (1950). Creativity is one of those things that makes humans special, and is a key issue for artificial intelligence (AI) and cognitive sciences: if computers cannot be creative, then 1) they cannot be intelligent, and 2) people are not machines [35].
The standard argument against computers’ ability to create is that they merely follow instructions. Lady Lovelace states that “they have no pretensions to originate anything.” A distinction, is proposed by Boden between psychological creativity (P-creativity) and historical creativity (H-creativity) [14]. Something is P-creative if it is fundamentally novel for the individual, whereas it is H-creative if it is fundamentally novel with respect to the whole of human history. A work is therefore granted H-creative only in respect to its context. There seems to be no evidence whether there is a continuum between P-creativity and H-creativity.
Despite the lack of conceptual and theoretical consensus, there have been several attempts at building creative machines. Harold Cohen’s AARON [29] is a painting program that produces both abstract and lifelike works (Figure 1-1). The program is built upon a knowledge base full of information about the morphology of people, and painting techniques. It plays randomly with thousands of interrelated variables to create works of art. It is arguable that the creator in this case is Cohen himself, since he provided the rules to the program, but more so because AARON is not able to analyze its own work.
|
|
Composing music is creating by putting sounds together. Although it is known that humans compose, it turns out that only few of them actually do it. Composition is still regarded as an elitist, almost mysterious ability that requires years of training. And of those people who compose, one might wonder how many of them really innovate. Not so many, if we believe Lester Young, who is considered one of the most important tenor saxophonists of all time:
“The trouble with most musicians today is that they are copycats. Of course you have to start out playing like someone else. You have a model, or a teacher, and you learn all that he can show you. But then you start playing for yourself. Show them that you’re an individual. And I can count those who are doing that today on the fingers of one hand.”
If truly creative music is rare, then what can be said about the rest? Perhaps, it is not fair to expect from a computer program to either become the next Arnold Schönberg, or not to be creative at all. In fact, if the machine brings into existence a piece of music by assembling sounds together, doesn’t it compose music? We may argue that the programmer who dictates the rules and the constraint space is the composer, like in the case of AARON. The computer remains an instrument, yet a sophisticated one.
The last century has been particularly rich in movements that consisted of breaking the rules of previous music, from “serialists” like Schönberg and Stockhausen, to “aleatorists” like Cage. The realm of composition principles today is so disputed and complex, that it would not be practical to try and define a set of rules that fits them all. Perhaps a better strategy is a generic modeling tool that can accommodate specific rules from a corpus of examples. This is the approach that, as modelers of musical intelligence, we wish to take. Our goal is more specifically to build a machine that defines its own creative rules by listening to and learning from musical examples.
Humans naturally acquire knowledge, and comprehend music from listening. They automatically hear collections of auditory objects and recognize patterns. With experience they can predict, classify, and make immediate judgments about genre, style, beat, composer, performer, etc. In fact, every composer was once ignorant, musically inept, and learned certain skills essentially from listening and training. The act of composing music is an act of bringing personal experiences together, or “influences.” In the case of a computer program, that personal experience is obviously quite non-existent. Though, it is reasonable to believe that the musical experience is the most essential, and it is already accessible to machines in a digital form.
There is a fairly high degree of abstraction between the digital representation of an audio file (WAV, AIFF, MP3, AAC, etc.) in the computer, and its mental representation in the human’s brain. Our task is to make that connection by modeling the way humans perceive, learn, and finally represent music. The latter, a form of memory, is assumed to be the most critical ingredient in their ability to compose new music. Now, if the machine is able to perceive music much like humans, learn from the experience, and combine the knowledge into creating new compositions, is the composer: 1) the programmer who conceives the machine; 2) the user who provides the machine with examples; or 3) the machine that makes music, influenced by these examples?
Such ambiguity is also found on the synthesis front. While composition (the creative act) and performance (the executive act) are traditionally distinguishable notions—except with improvised music where both occur simultaneously—with new technologies the distinction can disappear, and the two notions merge. With machines generating sounds, the composition, which is typically represented in a symbolic form (a score), can be executed instantly to become a performance. It is common in electronic music that a computer program synthesizes music live, while the musician interacts with the parameters of the synthesizer, by turning knobs, selecting rhythmic patterns, note sequences, sounds, filters, etc. When the sounds are “stolen” (sampled) from already existing music, the authorship question is also supplemented with an ownership issue. Undoubtedly, the more technical sophistication is brought to computer music tools, the more the musical artifact gets disconnected from its creative source.
The work presented in this document is merely focused on composing new music automatically by recycling a preexisting one. We are not concerned with the question of transcription, or separating sources, and we prefer to work directly with rich and complex, polyphonic sounds. This sound collage procedure has recently gotten popular, defining the term “mash-up” music: the practice of making new music out of previously existing recordings. One of the most popular composers of this genre is probably John Oswald, best known for his project “Plunderphonics” [121].
The number of digital music titles available is currently estimated at about 10 million in the western world. This is a large quantity of material to recycle and potentially to add back to the space in a new form. Nonetheless, the space of all possible music is finite in its digital form. There are 12,039,300 16-bit audio samples at CD quality in a 4-minute and 33-second song1, which account for 65,53612,039,300 options. This is a large amount of music! However, due to limitations of our perception, only a tiny fraction of that space makes any sense to us. The large majority of it sounds essentially like random noise2. From the space that makes any musical sense, an even smaller fraction of it is perceived as unique (just-noticeably different from others).
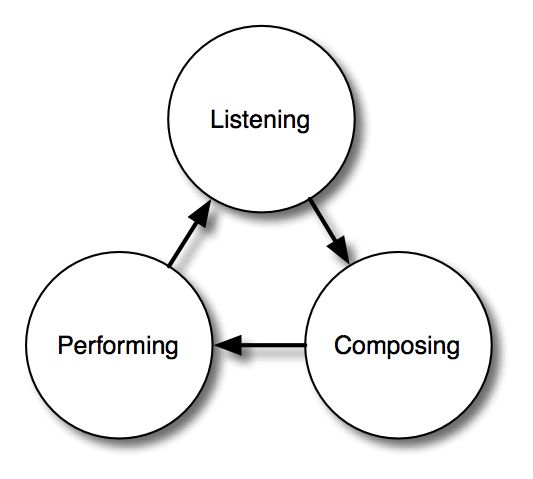
In a sense, by recycling both musical experience and sound material, we can more intelligently search through this large musical space and find more efficiently some of what is left to be discovered. This thesis aims to computationally model the process of creating music using experience from listening to examples. By recycling a database of existing songs, our model aims to compose and perform new songs with “similar” characteristics, potentially expanding the space to yet unexplored frontiers. Because it is purely based on the signal content, the system is not able to make qualitative judgments of its own work, but can listen to the results and analyze them in relation to others, as well as recycle that new music again. This unbiased solution models the life cycle of listening, composing, and performing, turning the machine into an active musician, instead of simply an instrument (Figure 1-2).
In this work, we claim the following hypothesis:
Analysis and synthesis of musical audio can share a minimal data representation of the signal, acquired through a uniform approach based on perceptual listening and learning.
In other words, the analysis task, which consists of describing a music signal, is equivalent to a structured compression task. Because we are dealing with a perceived signal, the compression is perceptually grounded in order to give the most compact and most meaningful description. Such specific representation is analogous to a music cognition modeling task. The same description is suitable for synthesis as well: by reciprocity of the process, and redeployment of the data into the signal domain, we can resynthesize the music in the form of a waveform. We say that the model is lossy as it removes information that is not perceptually relevant, but “optimal” in terms of data reduction. Creating new music is a matter of combining multiple representations before resynthesis.
The motivation behind this work is to personalize the music experience by seamlessly merging together listening, composing, and performing. Recorded music is a relatively recent technology, which already has found a successor: synthesized music, in a sense, will enable a more intimate listening experience by potentially providing the listeners with precisely the music they want, whenever they want it. Through this process, it is potentially possible for our “metacomposer” to turn listeners—who induce the music—into composers themselves. Music will flow and be live again. The machine will have the capability of monitoring and improving its prediction continually, and of working in communion with millions of other connected music fans.
The next chapter reviews some related works and introduces our framework. Chapters 3 and 4 deal with the machine listening and structure description aspects of the framework. Chapter 5 is concerned with machine learning, generalization, and clustering techniques. Finally, music synthesis is presented through a series of applications including song alignment, music restoration, cross-synthesis, song morphing, and the synthesis of new pieces. This research was implemented within a stand-alone environment called “Skeleton” developed by the author, as described in appendix A. The interested readers may refer to the supporting website of this thesis, and listen to the audio examples that are analyzed or synthesized throughout the document: