
The regular Hough Transform for extraction of parametric curves involves an $O(n^2)$ time complexity for an $n\times n$ image. If we divide the image into blocks of size $m\times m$ each, we can reduce this time complexity to $O(m^2)$. For an image of reasonable size, $m$ can be a full order of magnitude smaller than $n$. Thus, in theory, we can expect AHT to perform at least two orders of magnitude faster than the regular Hough Transform.
In our paper titled "Additive Hough Transform on Embedded Computing Platforms" presented at MWSCAS 2013, we explored this theorized performance gain on a wide variety of architecture. We found that with a block size of $8\times8$ and an image of size $256\times256$ pixels, while, in theory, we expect AHT to be a full 1024$\times$ faster than the regular HT, in practice, we could achieve only 35$\times$ in hardware.
This drop in performance is primarily due to compulsory atomic access to the final Hough Space. That is, even though we can compute the local Hough Transforms of all the individual blocks in parallel, they must finally be serially summed. This serial summation, in practice, takes longer than actual computation of the local Hough Transforms.
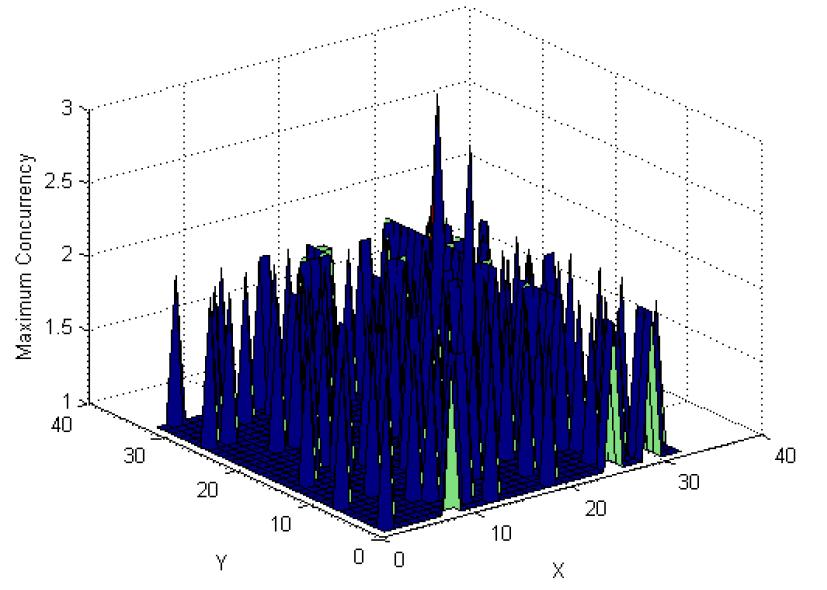
We decided to tackle this problem by analyzing the distribution of edge pixels in images. We plotted the concurrency of edge pixels at a particular location with respect to the local origins across all blocks. This is equal to the number of blocks of the image that have edge pixels at the same local location $(X, Y)$ simultaneously in the same image. Additionally, it can be shown that it is necessary to only compute the Hough Transform along directions perpendicular to the gradient direction at the edge to get a reasonably similar final Hough Space (O'Gorman and Clowes Transform). Thus, we can further reduce this concurrency by generating a different distribution for each angle, only taking into account the edge pixels which have a gradient perpendicular to that angle. We plotted this data for a huge dataset of ~2000 images and found the maximum concurrency at each local location. These distributions are shown below for $256\times256$ images. $k$ represents the grid size and $m$ the number of pixels along one dimension of each block. Thus $m$ = $256/k$.




Using this data, we can set an upper limit on the concurrency our architecture supports and store local Hough Transform values in buffers of length equal to this maximum supported concurrency. We would then need to sum only the values in these buffers to generate the final Hough Space, and would not have to go through all the local Hough Spaces.
Since this work is still underway and has not yet been published, technical aspects of our architecture cannot be described here. For more details, contact me.