Next: Video Finger: Software Up: Synthetic Movies Previous: Basic Components of
Next: Video Finger: Software
Up: Synthetic Movies
Previous: Basic Components of
This thesis presents an example implementation of a synthetic movie, Video Finger. Video Finger is an application which uses a synthetic movie to convey information about the state of the computer workplace.
It interfaces with existing UNIX information servers over a local area network to obtain information about users: their login state, and what they are currently doing.
It was suggested by, and named after, the UNIX finger utility .
The main use of the finger utility is to find out who is logged in to a computer system, and what they are doing or how long since they did something.
.
The main use of the finger utility is to find out who is logged in to a computer system, and what they are doing or how long since they did something.
The traditional output of the finger utility is text in a chart format, listing selected information. An example output is shown in Fig. 4.1.
Alternatively, visualize a video interface to the same program: A window on the user's display shows a preselected scene, perhaps a local computer terminal room or set of offices.
In this scene are the people sharing that computer system.
The people being observed may actually be working at home, or in another country. The task being performed by the people in the scene is indicative of their computer usage.
If, for example, they have been idle for longer than a preset threshold, they appear to have fallen asleep.
A typical Video Finger window is shown in Fig. 4.2.
3:08am up 3 days, 12:18, 26 users, load average: 0.70 User tty login@ idle JCPU PCPU what sab tty12 9:51am 9:01 1:49 1:11 emacs -f rmail wad tty16 2:57am 1 finger kazu tty36 11:11am 15:21 1 1 rn chen tty41 11:07pm 1:34 9 6 rlogin rebel vmb tty58 9:23am 10:17 3:25 6 -tcsh gslee ttyp2 3:05am 18 17 col pat ttyp3 4:14pm 38:17 1 emacs ch2.tex jh ttyp6 3:35am 6:12 5 -tcsh lacsap ttypa 8:54pm 50:28 1:20 8 more foobar klug ttypb 1:43am 1:09 10 tcsh walter ttyr0 11:25am 36:15 40 4 emacs isabel wave ttyre 2:18pm 1:49 1:14 3 -tcsh
If the window is allowed to remain, the scene within changes to reflect the changing computer environment. When a person logs into the system, they enter the scene. When they log out, they exit the scene. They stop doing one task, say reading the news, put down the paper, and start doing another task, such as writing. The user may select a person by clicking on them with a mouse (or touching a touch-screen), and then ask the application for more specific information than is being shown (such as the exact name of the task being run by the person). The information being presented could be varied. A voice-mail system where the user sending the mail actually reads the mail to you is a simple extension. Or a ``talk'' utility where the person actually turns around and does that, on your screen.
Video Finger synthesizes the image sequence displayed in response to changes in remote user activity. The description of the sequence is generated by a routine that monitors the activity of the remote users. The descriptions of the objects/persons in the sequence reside in local storage in the receiver, although they could be obtained from a remote file server over the same local area network used to monitor the remote user information.
The image sequence being synthesized by Video Finger can be visualized as the output of a software camera being aimed at the computer system. Occasionally, when the system is at rest, the output of the camera will be still and nothing in the sequence will be changing. At other times, when the many users are logging in or out, the camera will record the five o'clock rush and show much action in the sequence.
The hardware platform chosen for Video Finger was the Apple Macintosh IIx personal computer, equipped with the IranScan video card. The Mac II was chosen because it is a personal computer, yet it supports a graphics oriented user interface well suited to integration with image sequences. The IranScan video card is the result of a joint effort by the Media Laboratory and Apple Computer to develop a system capable of decoding and displaying compressed image sequences. IranScan is designed to decode vector quantized images, but may be used to display color quantized images with up to 4096 colors as well.
The Macintosh IIx is a 32 bit microcomputer, with a 16 MHz Motorola 68030 and up to 8 MByte of RAM. It has a floating point coprocessor, the Motorola 68882. A SCSI mass storage interface allows the use of hard disks and CD-ROM optical drives. An expansion bus, the NuBus, allows additional memory, processors, and peripherals to be integrated into the system. Video display devices are connected to the NuBus. System expansion normally includes separate, specialized processors connected to the NuBus to accelerate sound and graphics synthesis and processing. Although the theoretical data transfer rate over the NuBus is in excess of 35 MByte/sec., actual data rates obtained between the Mac II processor and a peripheral on the NuBus are much lower, on the order of 4 MBytes/sec [Baumwell88]. Due to the lack of a DMA controller, the Mac IIx is not capable of sustaining this rate.
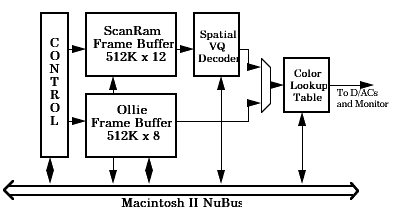
The IranScan frame buffer (shown in Fig. 4.3) consists of two frame buffers, one of which may be superimposed over the second. The ``top'' frame buffer (Ollie) is used by the Macintosh operating system to display the Desktop, and supports pixels from 1 bit to 8 bits deep. The ``bottom'' frame buffer (ScanRam) is used for display of image sequences. It supports pixels from 8 to 12 bits deep. IranScan was designed as a tool for exploring vector quantization of image sequences. In this application, however, I am using IranScan because of flexibility that ScanRam provides for display of more conventional image sequences. An image displayed in a ScanRam window may be double buffered without redrawing the entire screen. This requires less screen memory, as well as allowing faster screen updating. In addition, the pixel depth provided by ScanRam allows the use of realistic color [Heckbert82]. The color lookup table (CLUT) hardware also supports double buffering, allowing it to be updated without disturbing the displayed image.
The display window generated by Video Finger has a content region of 320x240 pixels, which is one-quarter of the screen. This size reduces the drawing requirements to allow real-time animation, yet is still capable of conveying much information.
If a Macintosh IIx can draw 1 Mpixels per second to the screen, it should be capable of displaying thirteen frames of video (320x240) per second. If it is equipped with 8 MBytes of RAM, it can display around seven seconds of such video. Actual applications introduce overhead, however, making this predicted frame rate optimistic.
There are several possible representations for the object data, varying in complexity and manipulability.
Unfortunately, the Mac II is not powerful enough to implement even a simple three dimensional rendering in real time, requiring a larger, less complex representation.
The object representation chosen for Video Finger is the 2D image set representation. This representation, although restrictive and memory intensive, is very simple to display. If desired, the data for the object representations could be rendered from a more complete, computer graphic database. This representation also allows a simple description of motion.
The concept of using image views as a description of the object's appearance suggests a similar approach to motion description, the one used by Video Finger. Object motion/deformation is described by a series of views, called a ``task''. Each object has associated with it a set of tasks, which represent a significant motion/deformation for that object. An example of the views composing a simple task is presented is Fig. 4.4.
The tasks are defined using a simple interpreted language which defines which object view to use and any independent object motion. The use of a ``task'' motion representation constrains the motion of objects to be simple translation, existing tasks and unions of those tasks.
A ``task'' can only define the motion of one object. The Task Dispatcher, along with a signaling mechanism incorporated into the language, provide for the concurrent object motion necessary for intraframe synthetic movies.
Unfortunately, object descriptions must contain all the views and tasks desired. In Video Finger, this is not a significant problem, as the required object motion is limited. Only about a dozen object tasks were considered necessary for Video Finger.
Given the two dimensionality of the object representation being used, other methods must be used to impose the perception of a projection of a three dimensional image. Video Finger provides for simple occlusion, as well as perspective. Each object may have one of 256 discrete depths. The depth indicates the order of drawing: the objects with larger depth (distance into the screen) are drawn first.
This provides for simple occlusion, but complex occlusion
requires that the object be divided into two parts, one in front of the occluding object and the rest behind. This would be a simple extension to the existing software, but it was not implemented.
In addition to occlusion, the size of an object is changed to correspond to the depth. This simulates the lens parameters used in ``recording'' the scene.
The scaling value used is derived from the formula for a simple lens: 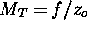 , where
, where 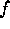 is the focal length of the lens being simulated and
is the focal length of the lens being simulated and 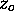 is the depth of the object [Hecht79].
The focal length used in drawing a frame is determined by the background image being used. The focal length used is the same as that used to record the background, so that objects superimposed over the background appear normal with respect to the background.
is the depth of the object [Hecht79].
The focal length used in drawing a frame is determined by the background image being used. The focal length used is the same as that used to record the background, so that objects superimposed over the background appear normal with respect to the background.