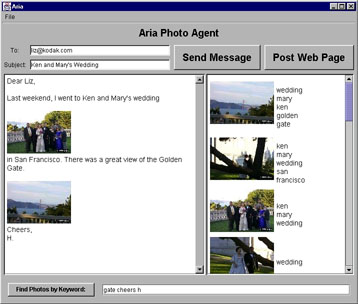
We present a user interface agent, ARIA [Annotation and Retrieval Integration Agent], that assists users by proactively looking for opportunities for image annotation and image retrieval in the context of the user's everyday work. The initial version of ARIA sits in the user's e-mail editor, and continuously monitors typing. Continuous, ranked searches are automatically performed from an image library, and images relevant to the current text can be inserted in a single click. Descriptions of images entered for the purposes of storytelling in e-mail can be seamlessly employed as raw material for image annotation. While not completely automating the image annotation and retrieval process, ARIA dramatically reduces user interface overhead, leading to better annotated image libraries and fewer missed opportunities for image use.
A movie demonstration of Aria with Common Sense Reasoning (Shockwave Flash format. Make the window BIG!)
Henry Lieberman, Elizabeth Rosenzweig And Push Singh
Aria: An Agent For Annotating And Retrieving Images,
IEEE Computer, July 2001, pp. 57-61.
Henry Lieberman and Hugo Liu,
Adaptive Linking between Text and Photos Using Common Sense Reasoning,
Conference on Adaptive Hypermedia and Adaptive Web Systems, Malaga, Spain, May
2002.

In a hypermedia authoring task, an author often wants to set up meaningful connections between different media, such as text and photographs. To facilitate this task, it is helpful to have a software agent dynamically adapt the presentation of a media database to the user's authoring activities, and look for opportunities for annotation and retrieval. However, potential connections are often missed because of differences in vocabulary or semantic connections that are "obvious" to people but that might not be explicit. ARIA (Annotation and Retrieval Integration Agent) is a software agent that acts an assistant to a user writing e-mail or Web pages. As the user types a story, it does continuous retrieval and ranking on a photo database. It can use descriptions in the story to semi-automatically annotate pictures. To improve the associations beyond simple keyword matching, we use natural language parsing techniques to extract important roles played by text, such as "who, what, where, when". Since many of the photos depict common everyday situations such as weddings or recitals, we use a common sense knowledge base, Open Mind, to fill in semantic gaps that might otherwise prevent successful associations.
Hugo Liu and Henry Lieberman,
Robust Photo Retrieval Using World Semantics
Proceedings of the 3rd International Conference on Language Resources And
Evaluation Workshop: Using Semantics for Information Retrieval and Filtering
(LREC2002) -- Canary Islands, Spain
Photos annotated with textual keywords can be thought of as resembling documents,
and querying for photos by keywords is akin to the information retrieval done
by search engines. A common approach to making IR more robust involves query
expansion using a thesaurus or other lexical resource. The chief limitation
is that keyword expansions tend to operate on a word level, and expanded keywords
are generally lexically motivated rather than conceptually motivated. In our
photo domain, we propose a mechanism for robust retrieval by expanding the concepts
depicted in the photos, thus going beyond lexical-based expansion. Because photos
often depict places, situations and events in everyday life, concepts depicted
in photos such as place, event, and activity can be expanded based on our "common
sense" notions of how concepts relate to each other in the real world.
For example, given the concept "surfer" and our common sense knowledge
that surfers can be found at the beach, we might provide the additional concepts:
"beach", "waves", "ocean", and "surfboard".
This paper presents a mechanism for robust photo retrieval by expanding annotations
using a world semantic resource. The resource is automatically constructed from
a large-scale freely available corpus of commonsense knowledge. We discuss the
challenges of building a semantic resource from a noisy corpus and applying
the resource appropriately to the task.