Useful, Welcoming Software is a conceptual model for describing software, and articulating design goals. It is built around two questions:
What is this software useful for?
Who is this software welcoming to?
Avid Technologies Pro Tools and Ableton Live are useful for producing
music. Ableton Live is useful simply because a lot of producers choose to “use” it for aesthetic and practical reasons. Pro Tools is similarly
useful because it is still a core component of commercial music production.
However, Live and Pro Tools are “welcoming” to a very narrow user base, because both are expensive, closed source, and only available under restrictive
licenses. You cannot legally share your copy of Ableton Live with a friend. Are you allowed to run a copy of Pro Tools on a web server as part of an generative
interactive streaming audio exhibit? I do not know, because Pro Tools’ legal user rights are buried in a 240 page End User License Agreement (as of December 2020). Pro Tools is probably only welcoming to affluent audio engineers and producers with professional ambitions.
In the context of Useful, Welcoming Software, “useful,” and “welcoming” are intended to have somewhat more specific
meaning than in everyday conversation.
You can think about these questions as aspirational design goals:
What do we want this software useful for?
Who do we want this software to be welcoming to?
Here’s an example from Fluid Music, which is software I am writing for my dissertation.
Fluid Music aims to be:
Useful for creating music that people care about
Welcoming to developers with a wide variety of backgrounds
Within the Useful, Welcoming Software model, software is always useful for some purpose. Conceptually, this is more useful for thinking
about and articulating software design goals.
Similarly, within the Useful, Welcoming Software model, software is always welcoming to some audience.
The word “welcoming” is intended to express the intention of going beyond “access”. Not only can you access welcoming software, but
in the ideal case, it invites you to use it. A high cost, a difficult user interface, or a restrictive user license are all antithetical to welcoming
software. Free, well-documented software with a permissive license, and an accessible user interface, is more “welcoming.” However, care should
still be taken to consider who is it welcoming to. What language is the software written in? What spoken languages are present in the documentation?
Does the website or documentation use subtle -isms? What assumptions does the documentation
make about the reader’s background and areas of expertise?
I found that being intentional about what I want my software to do, and who I want to be able to do it helped me make consistent design choices.
It also helped me to articulate why I made the design choices I did.
It is is a simple model with modest ambitions. Note that while it may help identify or articulate design goals, this is just a first step. You still need to
evaluate the implications of the software you are building. For example…
Amazon Rekognition aims to be:
Useful for identifying and characterizing individuals using an image of their face
Welcoming to governments, NGOs, and businesses
In an ideal world this would alert you to the fact that there are some serious ethical concerns with the software Amazon is creating. But if you are not familiar
with the literature on facial recognition software, that might not be obvious. Know that merely identifying and articulating the goals of software you are working
on is not a substitute for understanding and evaluating them.
OpenAI Is Joining Amazon in a nascent group of major tech companies to invest astronomical sums of money in machine learning projects for generating music.
This example output from OpenAI’s new Jukebox demo probably illustrates it best:
OpenAI situates this track as the output of their waveform generating neural network, which has been conditioned on music by Kanye West.
The result is actually a very garbled hip hop audio with clearly audible excerpts from Eminem’s Lose Yourself. It is more revealing of Deep Neural
Networks’ tendency to obscure and appropriate the labor used in their creation than it is impressive that they made Eminem sound a little bit like Kanye
West.
As was the case for Amazon’s DeepComposer, George Lewis’ writing about
music tech is probably the best lens through which to study OpenAI’s Jukebox. Lewis published a paper in the Leonardo music journal in 2000, which includes this quote:
“As notions about the nature and function of music become embedded in the structure of software-based musical systems and compositions, interactions
with these systems tend to reveal characteristics of the community of thought and culture that produced them.”
We should understand the meticulously researched, astronomically expensive, machine learning technology on display here as representative of the “community
of thought” at OpenAI.
August 12, 2021: sub.live now available for MacOS and Windows
I’ve been getting a lot of questions about collaborative online music in the age of Covid-19. There are lots of performance and DJ streams on Twitch and
Youtube. What are the options for collaborating on making music. What is the lowest-latency way to play music together over the internet? Can my choir
rehearse over zoom? How can I collaborate on recordings with other musicians while we are self-isolating? What follows is a quick brain dump that I hope will
be helpful.
NOTE: The tweet-sized description of my PhD work at the MIT Media lab is: “Understanding the long-term potential of the internet, AI,
and streaming technologies for music through experimentation” and I have way more to say about this than almost anyone wants to hear. I’ll try
to keep this pragmatic.
The Short Answer
No one wants to hear the short answer, but: Real-time (synchronous) internet-enabled music collaboration will never seriously compete with playing music with
other people in the same room. Video conferencing options like Zoom and Google Hangouts have a combination of latency and quality issues, and will be more frustrating
than rewarding. When making music together online, I recommend non-real-time (asynchronous or semi-synchronous) approaches.
Below I list a variety of collaborative technologies for creating music on the internet. I’ve written about this in the past, but FWIW, the technologies outlined below are primitive, and are (in their own different ways) attempting to squeeze historical ideas and
formats into the online medium. We haven’t yet figured a way to create music collaboratively on the internet where the advantages outweigh the disadvantages.
However because many of us are self isolating right now, playing music in the same room just isn’t possible…. So now is a good time to look at
some of the current options for online music collaboration.
Realtime Internet Enabled Collaboration
If you really want to shoehorn the experience of making music together in real-time into the internet, I recommend trying one of the following native applications
which are designed to minimize latency.
JackTrip (Mac, Linux), (Windows).
Open source, free software for creating reasonably low-latency audio connections over the internet. It also scales to multiple concurrent users, as bandwidth
allows.
SoundJack I haven’t used this, but it looks slightly more user friendly than JackTrip.
sub.live prioritizes low latency audio, but also includes video support. As of August 2021 it is available for Mac and Windows.
I would go with one of the options above if everyone in your ensemble knows what an IP address is, and is ready to set up port-forwarding if needed. SoundJack
has some nice tutorials and documentation for network configuration. JackTrip requires that one user run a server, which will be easier if that user is familiar
with a command line, is familiar with Jack Audio, and has some knowledge of computer networking. JackTrip comes from Stanford’s
Center for Computer Research in Music and Acoustics, which published a write-up of
one of their early experiments, containing some useful references.
Note that all real-time options will have latency. Your mileage will vary. If your ensemble is small, everyone is in the same geographic region, and everyone
has a fast internet connection you might just get usable results.
A quick note about latency: Assume our latency threshold is 20 milliseconds. Anything higher than this and your ability to play together begins to suffer. Light
travels approximately 3728 miles in 20 milliseconds (in a vacuum). Absolute best case scenario for round-trip audio is 1864 miles or NYC to Wyoming (but not
across the Atlantic). Practical results will rarely be better than half that, and typically be much, much worse, due to network congestion, bandwidth limitations,
IP throttling, the fact that light travels slower in the optical cables and internet hardware that it does in a vacuum, and other factors.
Experiments show that musicians can perform together acceptably with latency as high as 50
milliseconds. However, even in the unusual situation when you have a low-ish latency connection to your fellow musicians, there are other difficulties associated
with playing music together over the internet in real-time. Think of how difficult it is just to get a Zoom meeting in the office going, with projectors, calls,
constantly misbehaving in creative new ways. Now imagine that every participant brings with them the complexity of a small home studio. Suddenly trying to coordinate
a performance becomes much harder.
Almost realtime (with optional Zoom video share)
If your use-case can tolerate approximately 100 milliseconds of latency, and you want lossless audio, the subscription service by Audio Movers might be what you need. Their service uses an audio workstation plugin, and can stream to a sharable browser URL. The video below shows how to synchronize a
web stream to a Zoom call for Audio+Video.
This might be useful in professional situations as discussed in the video. However it will probably not be suitable for realtime jamming or distributed performance.
Non-Internet Network Audio
If you are lucky enough to be on the same physical network as your musical collaborators then JackTrip might work well. However, depending on your network infrastructure,
you can probably get even better results with professional audio-over-ethernet options such as AVB (Supported by modern Motu interfaces like the UltraLightAVB)
or Dante (supported by modern Focusrite audio interfaces like the REDNET2XP). These
protocols can deliver high channel counts at sub-millisecond latency over a local network. For Dante or AVB, ensure compatibility with your network hardware
before buying audio interfaces.
“Google Docs for Audio”
A number of startups are developing tools that add cloud enabled collaboration to the form factor of conventional digital audio workstations. These add real-time
remote collaboration to a digital audio workstation, meaning that users record and edit audio at the same time similar to how users can edit text collaboratively
in Google Docs. Note that the real-time interaction is for composing, editing, or recording music – these are not helpful if you want to play music together in real-time.
faders.io - This is a brand new option which is as of Summer 2021. In beta
All of these are less mature and less capable than native digital audio workstations. Soundtrap was purchased by Spotify in 2017, and so it has a little more
support than some of the others. It is also browser based, which means its sessions are easy to share, but limits its capabilities in other ways. These tend
to be aimed at podcast creators, and beat makers, but you can use them for other kinds of music as well.
“Dropbox for Digital Audio Workstations”
If you are accustomed to working with a conventional digital audio workstation like ProTools, Ableton Live, or Reaper, one easy option is to save your session
files along with the accompanying audio files in a Dropbox folder, and then pass them off to your band mates so that they can record over them. Unlike the options
above, only one user will be able to record or edit at a time.
Dropbox works okay for this purpose, but I would also recommend taking a look at these variants, which are specially designed for working with digital audio
sessions. These include extra features like dedicated audio session version control and track preview. These can be helpful for sharing audio sessions between
users.
These will try to sell you sample packs and drum loops. If you want to make music with samples or loops, this might even be useful.
Mobile apps
These come and go so quickly it is hard to keep up! Here are just a few.
There are a million different mobile apps for creating videos. Want to make a video like the one that recently went viral by the Chino Valley Unified School
District in California? Google video collage, and there are numerous apps that will help.
Acapella is one iOS app that cam make video collages, and includes built-in
support for remote collaboration. Here’s a self-isolation themed music video made with Acapella.
TikTok is often used with video editor apps (like Acapella), but it also includes features for asynchronous collaboration
called “duets” and “reactions” which are pretty self explanatory. If you know of a nice example of a musical TikTok Duet, please
send me a link, and I’ll embed it.
Smule’s eponymous mobile app is specifically made to create karaoke style videos collaboratively. It includes a RockBand
style vocal pitch display, supports remote collaborations, and can create video collages.
Semi Real-Time Loop Based Jamming
This final category of apps is for jamming with people in almost-real time. Instead of trying to minimize latency, these increase latency to a musical
duration in measures. They work kind of like playing with a looper, except that instead of layering over yourself, you are layering over what other musicians
played a few bars ago.
Ninjam is free and open source. It is designed to be used with the commercial, but very affordable DAW, Reaper
Jammr is a commercial version of the same concept. Might be slightly easier to setup than Ninjam, but for most purposes, I
recommend Ninjam
Endless is a mobile app that supports semi real-time beat making, and can also sync with a MacOS desktop app.
If you are familiar with (or interested in) algorithmic music or code-based composition, there are also tools for “jamming” semi real-time with
code. The TidalCycles software package supports several different collaborative paradigms including shared editors for a google-docs like experience capable of generating MIDI messages with code (thanks to Manaswi Mishra for the tip).
Latency Tolerant Music
Music and compositions that do not depend on precise shared rhythm can be tolerant to latent or distributed interaction. Playing this kind of music is one way
to circumvent some (but not all) of the obstacles introduced by video conferencing. I participated in Pauline Oliveros’ “World Wide Tuning Meditation” via zoom, and while I wasn’t expecting to enjoy it, I was surprised. A review in the New York Times explains how the piece works.
For technology centric people (such as myself) it’s worth recognizing that what makes this kind of music work is not the technology: it is the community
leadership of the organizers.
Final Thoughts
There’s lots of historical examples, and a million apps I left out. If you think of an important category or example that I missed, please feel free to
reach out and I’ll add it to the list. If you don’t know me personally, try @CharlesHolbrow (or
email, etc.)
COVID-19 has and will continue to be challenging for musicians. Performing musicians (who don’t typically have extra money laying around) suddenly had
their tours cancelled and their income eliminated. Venues are closing. If you are lucky enough to be self-isolating with loved ones or family members, I recommend
making music with them. Also please reach out to friends and family who may be more isolated.
It can be tricky to understand how Kubernetes Services and Ingresses interact. The most important distinction relates to the concept of a Kubernetes Service.
A Kubernetes LoadBalancer is a type of Service.
A Kubernetes Ingress is not a type of Service. It is a collection of rules. An Ingress Controller in your cluster watches for Ingress resources, and attempts to update the server side configuration according to the rules specified in the Ingress.
For both Ingress and LoadBalancer resources, different Kubernetes providers (such as GKE, Amazon EKS, or bare metal) support different
features. One of the things that makes Ingresses and LoadBalancers tricky is that your YAML manifest files might not be portable between different platforms
and controllers.
Let’s talk about Services. One thing that clarified services for me is understanding how the different services build on each other. For example the ClusterIP is a simplest type. NodePort does everything that ClusterIP does (and more). LoadBalancer is another layer of capability
on top of NodePort.
So the mental process when I need a Service is:
Am I trying to help my pods talk to each other? If yes, ClusterIP is enough. If not…
Am I trying to make my Service accessible on the public web (on a port above 30000)? If yes, NodePorts is enough (this is unusual). If not…
Am I trying to manage most public traffic coming into the cluster? If yes, choose an Ingress or a LoadBalancer. This is where things get tricky, because your
options depend on the controllers that are available on your cluster.
Load Balancers tend to be a little simpler than Ingresses.
Ingresses might come with nice features like TLS/HTTPS termination and limited HTTP routing.
In my cluster I use the NGINX Ingress Controller for routing incoming HTTP requests to different services
based on their Host HTTP header and url.
Make sure you understand what ingress controller is installed on your cluster (if any) and know that the YAML manifests for it are likely not portable to other
Ingress Controllers — the YAML manifest that you give to the NGINX Ingress Controller might need to be pretty different than the manifest that you give
to your GKE Ingress.
It used to be that when I started a new RPG I got this amazing feeling of excitement when I began to explore the world. The thrilling feeling of entering a new
area and wondering what secrets could be hidden, waiting to be discovered.
Getting older, I experienced this less and less. The novelty of exploring a virtual world seemed to wear off as I got older. Then in 2011 I (along with the rest
of the world) found Minecraft. The experience was fresh and exciting. A great implementation of a different approach to generating a virtual world. Something
about knowing that world is infinite and unlike the world that anyone else is playing made exploration feel meaningful again.
Once I began to internalize the patterns of terrain in Minecraft the feeling of excitement began to ebb. It was still exciting to find diamonds, but the random
terrain began to feel repetitive and similar. I wanted to find something not random in the world - I wanted to find something that felt intelligent. What if
there were a way to stumble on the ruins of other users civilizations, decayed after many years of abandonment?
Could a hybrid approach to world building be the next step in the evolution of wanderlust in games? I started writing this game for mobile devices,
but my skills at the time were not enough to implement the networking required to simulate the dynamic world I imagined. Then I found Meteor, a javascript framework
that makes it very easy to synchronize client data. I re-implemented the game, migrating from the the Moai game engine to Meteor with the front-end entirely
written in a custom canvas based game engine. Here is my lightning talk at a 2013 meteor meetup in
San Francisco.
There were some pretty awesome features in the last meteor version. Users could write their own custom servers, characters could move between servers with a
complex three way authentication handshake. But I wasn’t following Ken Levine’s excellent game development advice: “Stop trying to be smart,
and start trying not to be dumb”. The engine and features were too complex, and it didn’t make sense for me to be maintaining my own javascript
game engine. So in early 2017 I started re-writing the game again. This time the server is written in Go, and the client built on top of PIXI.js canvas engine.
Both decisions have already paid off.
In one way or another I have been working on this game since the first mobile version 2012. It’s nearly always in some part of my mind – even when
I am too busy to be actively developing. Whenever I have a spare moment my mind wanders back to the most recent development challenge. There’s some inexplicable
force that drives me to keep at it. I envision a dynamic and evolving world in the cloud. A dwarf fortress for the next generation. A Minecraft for the future.
A limitless RPG for that can fill others with the same wanderlust that I found in RPGs of my childhood.
American composer Charles Ives (1874-1954) wrote many experimental pieces where he would selectively disregard certain ‘rules’ of music theory,
and explore the sonic results. In an essay on his experimental music, Ives asked this question:
If you can play a tune in one key, why can’t a feller, if he feels like, play one in two keys?
Ives’ early polytonal experiments include pieces with a melody in one musical key and accompaniment in another key, and pieces with separate
voices, each in separate keys. These experimental pieces were not published or performed until long after he wrote them, but Ives’ ideas did appear in
his less systematic compositions. More importantly his ideas influenced a generation of younger composers.
Among these younger composers was Henry Cowell (1897-1965), who in 1930 published New Musical Resources, a collection of largely unexplored musical
ideas. The book extends the notion of multiple simultaneous musical keys polytonal music to multiple simultaneous tempos, polytempic music.
Can we make music with multiple simultaneous tempos? Certainly. But Cowell took the idea a step further. Assume we have multiple simultaneous tempos and these tempos are accelerating or decelerating relative to each other. In New Musical Resources, Cowell called this practice sliding tempo,
and he noted that this would not be easy to do. In 1930, he writes:
For practical purposes, care would have to be exercised in the use of sliding tempo, in order to control the relation between tones in a sliding part with those
in another part being played at the same time: a composer would have to know in other words, what tones in a part with rising tempo would be struck simultaneously
with other tones in a part of, say, fixed tempo, and this from considerations of harmony. There would usually be no absolute coincidence, but the tones which
would be struck at approximately the same time could be calculated.
Phase Music
Can we calculate the times of coincidence like Cowell suggests? How? Can a musician even perform polytempic music with tempo accelerations or decelerations?
Over the course of the 20th century, musicians explored this idea in what is now called phase music (wikipedia).
One early example is Piano Phase (1967) by Steve Reich (wikipedia, vimeo).
Through experimentation, Steve Reich found that if the music is reasonably simple, two performers can make synchronized tempo adjustments relative to each other
well enough to yield compelling results. In Piano Phase two pianos both play the same repeating 12 note musical pattern. One musician plays at a slightly
faster rate than the other. It is possible for a musician to play this, but there is a limit to complexity of the patterns that a musician can play and a limit
to the number of simultaneous changing tempi a musician can comprehend. Piano Phase approaches the limit of what a musician can perform. Can we not
use electronic sequencers or digital audio tools to synthesize complex phase music with many simultaneous tempic transitions?
Most phase music (including Piano Phase) layers identical copies of musical content playing at slightly different speeds. The layers begin in-phase
with with each other, and gradually drift out of phase. Reich’s Piano Phase is no exception. As the layers drift out of phase, our listening
attention is drawn to variations caused by shifting phase relationships between the layers. In the example below, the two layers start out playing together
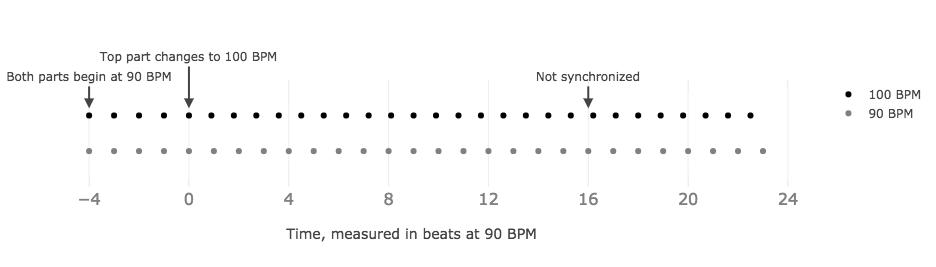
at 90 beats-per-minute (BPM), at \(t=0\) the top layer abruptly starts playing at 100 BPM.
Abrupt tempo change
If we wait long enough, eventually the layers will re-align, and and the whole pattern will start from the beginning again. But what if we want to control exactly
when the layers re-synchronize? Can we specify precisely both the time and the phase of sync points without abrupt changes in tempo? How can we sequence patterns
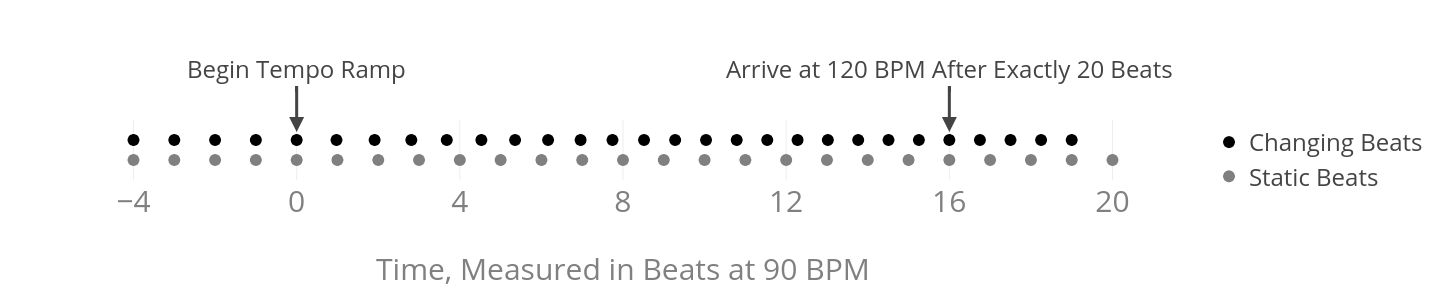
like the one below exactly? This is the central question of Tempic Integrations.
Continuous tempo acceleration from 90 BPM to 120 BPM
Tempic Integrations
If we want to specify the exact number of beats that elapse between the beginning of a tempo acceleration and the end point of the acceleration, and we want
to hear this precisely we need a mathematical model for shaping our tempo acceleration curves. The goal is to compose and audition music where:
Swarms of an arbitrary number of simultaneous tempi coexist.
Each individual player within the swarm can continuously accelerate or decelerate individually, but also as a member of a cohesive whole.
Each musical line can converge and diverge at explicit points. At each point of convergence the phase of the meter within the tempo can be set.
We start by defining a single tempo transition. Consider the following example from the image above:
Assume we have 2 snare drum players. Both begin playing the same beat at 90 BPM in common time.
One performer gradually accelerates relative to the other. We want to define a continuous tempo curve such that one drummer accelerates to 120 BPM.
So far, we can easily accomplish this with a simple linear tempo acceleration. However, we want the tempo transition to complete exactly when both drummers are on a down-beat, so the combined effect is a 3 over 4 rhythmic pattern. Linear acceleration results in the transition completing at an arbitrary
phase.
We want the accelerating drummer to reach the new tempo after exactly 20 beats.
We also want the acceleration to complete in exactly 16 beats of the original tempo, so that the drummer playing a constant tempo and the accelerating drummer
are playing together.
We are interested in both the number of beats elapsed in the static tempo and in the changing tempo, as well as the absolute tempo. If we think of the
number of beats elapsed as our position, and the tempo as our rate, we see how this resembles a physics problem. If we have a function that
describes our tempo (or rate), we can integrate that function, and the result will tell us our number of beats elapsed (or position). Given the above considerations,
our tempo curve is defined in terms of 5 constants:
Time \(t_0=0\), when the tempo transition begins
A known time, \(t_1\), when the tempo transition ends
A known starting tempo: \(\dot{x}_0\)
A known finishing tempo: \(\dot{x}_1\)
The number of beats elapsed in the changing tempo between \(t_0\) and \(t_1\): \(x_1\)
The tension of the tempo curve determines how many beats elapse during the transition period. The curve is well-defined for some starting acceleration
\(a_0\) and finishing acceleration \(a_1\), so we define the curve in terms of linear acceleration. Using Newtonian
notation we can describe our tempo acceleration as:
Integrating linear acceleration (above) yields a quadratic velocity curve (below). The velocity curve describes the tempo (in beats per minute) with respect
to time.
Evaluating for \(a_0\) with our constants gives us our starting acceleration. Once we have \(a_0\) we can solve our velocity equation to find the value of \(a_1\). Plugging \(a_1\) and
\(a_0\) into the velocity equation will give us velocity curve that produces a continuous BPM curve over the course of the tempo transition.
Note: We must specify the same time units for input variables like \(t_1\) and \(\dot{x}_1\).
I prefer minutes for \(t_1\) and beats per minute for \(\dot{x}_1\) over
seconds and beats per second.