Computational Photography
Ramesh Raskar, Jack Tumblin
What is
Computational Photography ?
Computational photography combines plentiful computing, digital
sensors, modern optics, actuators, and smart lights to escape the
limitations of traditional film cameras and enables novel imaging
applications. Unbounded dynamic range, variable focus, resolution, and
depth of field, hints about shape, reflectance, and lighting, and new
interactive forms of photos that are partly snapshots and partly videos
are just some of the new applications found in Computational
Photography.
In traditional film-like digital photography, camera images represent a view of the scene via a 2D array of pixels. Computational Photography attempts to understand and analyze a higher dimensional representation of the scene. Rays are the fundamental primitives. The camera optics encode the scene by bending the rays, the sensor samples the rays over time, and the final 'picture' is decoded from these encoded samples. The lighting (scene illumination) follows a similar path from the source to the scene via optional spatio-temporal modulators and optics. In addition, the processing may adaptively control the parameters of the optics, sensor and illumination.
Encoding and Decoding
The encoding and decoding process differentiates Computational
Photography from traditional 'film-like digital photography'. With
film-like photography, the captured image is a 2D projection of the
scene. Due to limited capabilities of the camera, the recorded image is
a partial representation of the view. Nevertheless, the captured image
is ready for human consumption: what you see is what you almost get in
the photo. In Computational Photography, the goal is to achieve a
potentially richer representation of the scene during the encoding
process. In some cases, Computational Photography reduces to 'Epsilon
Photography', where the scene is recorded via multiple images, each
captured by epsilon variation of the camera parameters. For example,
successive images (or neighboring pixels) may have a different
exposure, focus, aperture, view, illumination, or instant of capture.
Each setting allows recording of partial information about the scene
and the final image is reconstructed from these multiple observations.
In other cases, Computational Photography techniques lead to 'Coded
Photography' where the recorded photos capture an encoded
representation of the world. In some cases, the raw sensed photos may
appear distorted or random to a
human observer. But the corresponding decoding recovers valuable
information about the scene.
There are four elements of Computational Photography.
(i)
Generalized Optics
(ii)
Generalized Sensor
(iii)
Processing, and
(iv)
Generalized
Illumination
The first three form the Computational Camera. Like other imaging fields, in addition to these geometry defining elements, Computational Photography deals with other dimensions such as time, wavelength and polarization.
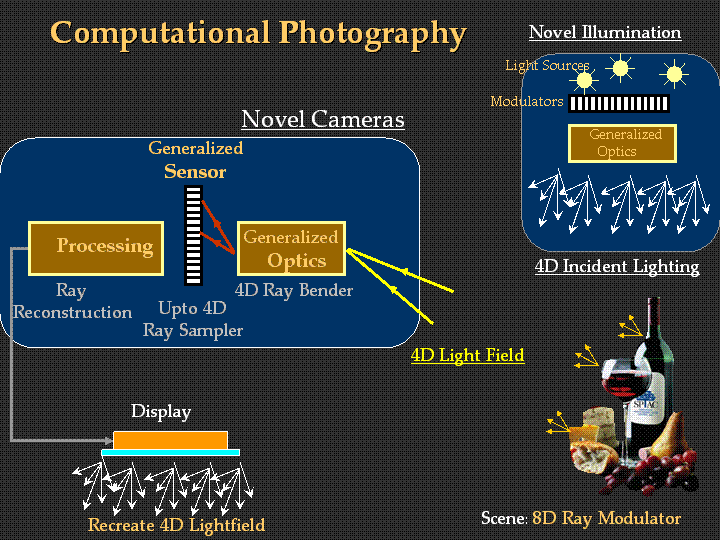
introduction of Computational Illumination as fourth element and emphasis on ray-modulation in each element.)
What is Next
The field is evolving through three phases. The first phase was about building a super-camera that has enhanced performance in terms of the traditional parameters, such as dynamic range, field of view or depth of field. I call this Epsilon Photography. Due to limited capabilities of a camera, the scene is sampled via multiple photos, each captured by epsilon variation of the camera parameters. It corresponds to the low-level vision: estimating pixels and pixel features. The second phase is building tools that go beyond capabilities of this super-camera. I call this Coded Photography. The goal here is to reversibly encode information about the scene in a single photograph (or a very few photographs) so that the corresponding decoding allows powerful decomposition of the image into light fields, motion deblurred images, global/direct illumination components or distinction between geometric versus material discontinuities. This corresponds to the mid-level vision: segmentation, organization, inferring shapes, materials and edges. The third phase will be about going beyond the radiometric quantities and challenging the notion that a camera should mimic a single-chambered human eye. Instead of recovering physical parameters, the goal will be to capture the visual essence of the scene and analyze the perceptually critical components. I call this Essence Photography and it may loosely resemble depiction of the world after high level vision processing. It will spawn new forms of visual artistic expression and communication. Please see the Introduction slides in Siggraph 2008 course notes for details on the three phases and example projects.
- Slides
from Siggraph 2008 Course Presentation (Debevec,
Raskar, Tumblin) [Video
of Presentation]
- Slides
from Siggraph 2007 Course Presentation [Videos] (Davidhazy, Georgiev, Levoy, Nayar, Raskar, Tumblin) [ACM Portal Videos]
- Slides
from Siggraph 2006 Course Presentation (Levoy,
Nayar, Raskar, Tumblin)
- Slides from Siggraph 2005 Course Presentation
- Bibliography 2006
- Source code for Graph Cuts, Bilateral filtering and Gradient domain reconstruction (Credit: Amit Agrawal, MERL intern 2004)
Book
- Computational
Photography: Mastering New Techniques for Lenses, Lighting, and Sensors
: A K Peters, Publishers
- Website
for the Book: ComputationalPhotography.org

Courses
- MIT Media
Lab course on Computational
Camera (Fall 2008)
- Siggraph
2008 Course Los Angeles, CA(July 2005) (Debevec,
Raskar, Tumblin)
- Northeastern University, Fall
2005 Course Boston, MA (May 2005)
- Siggraph
2005 Course Los Angeles, CA(July 2005)
Other Links
- Symposium
on Computational Photography and Video Cambridge, MA (May 2005)
- Wikipedia
Page on Computational Photography