lieber@media.mit.edu
http://www.media.mit.edu/~lieber/
Besides the problem of the accuracy of the wording of the query request, a more fundamental problem has to do with the control structure of the interaction between the user and the search agent. The query interface is conversational -- the user asks a question, then waits for the answer. After the answer is received, the user continues the browsing process, either accepting the recommendations of the agent, or doing unrelated browsing. Any other interaction with the agent requires a new search query.
A problem with this conversational metaphor is its sequential nature. Either the user is actively working, or the agent is actively working, but never both at the same time. When the agent is working on the user's request, it must try very hard to come up with the most accurate result possible in fulfilling the user's request, because once it has returned, it never gets another chance. This places strict requirements on how the search agent determines its choices.
Another problem with the suggestions provided by traditional search engines is that their recommendations are not delivered "in context". The user must perform a mental "context switch" from browsing the space of Web pages to explicitly interacting with the search agent.
Letizia is an agent that treats search through the Web space as a continuous, cooperative venture between the user and a computer search agent. Letizia is always active, and searches the Web space in parallel with the user's browsing activity. The user need not explicitly interact with Letizia. Letizia records the URLs chosen by the user and reads the pages to compile a profile of the user's interests. A simple keyword-frequency information retrieval measure is used to analyze pages. Letizia delivers its suggestions to the user through browser windows that appear on the user's screen simultaneously with the user's manual browsing activity. The user may choose to continue browsing with either his or her own selected pages, or Letizia's suggestions, at any moment in time.
This concurrency between the user interface and the search agent leads to a different style of interaction in the Web search. It is not customary to think of Web browsing as a real-time activity, but it is. A query-based search interface's value must be balanced against the cost in terms of time it takes to interact with the search agent which could have been spent browsing instead.
Having a continuously-running agent means that the agent can be bolder in its recommendations to the user. It need not make a perfectly accurate judgment as to which document best meets the user's interest, since it is likely to get another chance to do better at some future time, if the user continues to browse in related areas.
Finally, the recommendations are presented in context. Since Letizia bases recommendations on the page the user is examining at the moment, the user often sees both an explicitly selected page and an agent-recommended page simultaneously. The flow of thought of the user's browsing activity is not interrupted by the need to switch to an independent query interface. The agent recommendations come "just in time" as the related pages arise in the user's browsing activity.
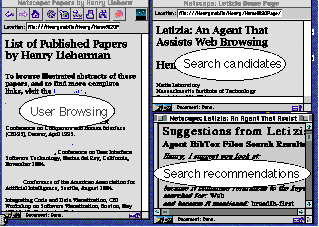
Letizia's usual interface, shown in the first illustration in this paper, consists of three Netscape windows. By default, the left-hand window is reserved for user browsing activity. The user may browse in this window in a normal matter, and can completely ignore any agent activity. The two windows on the right side are under control of the agent. The top window displays search candidates, those pages which Letizia is considering to recommend to the user. The bottom right window displays those pages that Letizia actually decides to recommend to the user, passing Letizia's tests for user interest.
In fact, the user may operate any of these windows, and Letizia notices which window is being controlled by the user and only uses windows that are not being actively used by the user. Accepting a suggestion from Letizia simply consists of switching to a window that contains a page recommended by Letizia, and continuing to browse. The user may, of course, save recommended pages on a hotlist or otherwise use them as usual in Netscape.
In practice, a less obtrusive way of running Letizia is just to use two windows, a user window and one Letizia window. Displaying the search candidates is not strictly necessary, but is often useful for demonstration and debugging purposes.
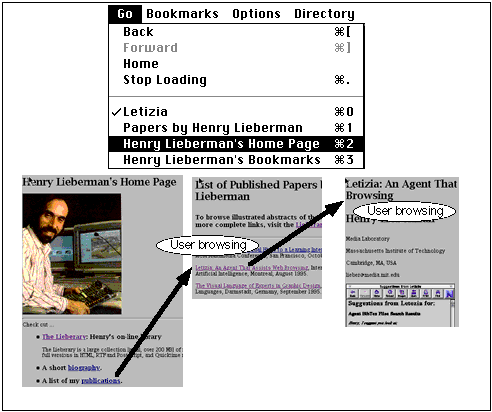
Netscape's "Go" menu accumulates a stack of previously explored Web pages. You can always "back out" to a previous page at a higher level, but this is not as natural an operation as clicking on a link to go further down one more level. You can see only the titles of the pages on the stack, and it is often unclear how many levels to back up in order to "leave" the current topic.
Thus browsers tend to encourage a depth-first exploration of the Web space. Letizia compensates for this by doing a breadth-first search, interleaved with the depth-first search performed by the user. Letizia starts by searching every page one link away from the user's current position, then two links away, and so on. It is often the case that pages of considerable interest to the user are not very far from the user's current position, if only the user knew exactly which links to follow to arrive at them.
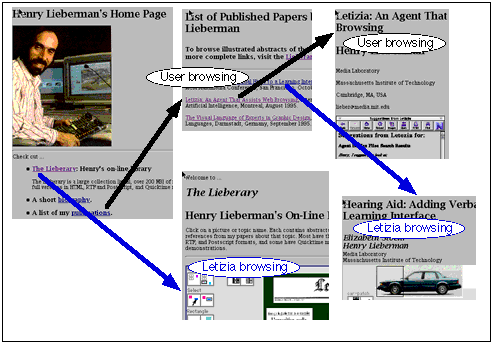
Uncontrolled breadth-first search is known to be combinatorially explosive, hence impractical. In practice, though, Letizia's breadth-first search is constrained by the interactive behavior of the user. Whenever the user switches from one Web page to another, Letizia's search is immediately refocused to the new page. The state of the search can be stored in a hash table indexed on the current page to continue if the user returns to the page in a short time [a common occurrence]. The user typically looks at a Web page for two or three minutes, then goes on. Web pages tend to be approximately of uniform size. Thus the search tends to remain manageable.
To compute the content of a document, Letizia currently uses a simple keyword frequency measure, TFIDF [term frequency times inverse document frequency]. This well-known technique [Salton 89] says that keywords that are relatively common in the document, but relatively rare in general are good indicators of the content. This heuristic is not very reliable, but is quick to compute and serves as a placeholder for more sophisticated techniques. Partial parsing techniques [Lehnert and Sundheim 91] would greatly improve the content analysis. A user profile is accumulated during browsing, and may be written out and read back in across sessions so the user profile can be persistent.
The utility of a Letizia agent lies not in making as accurate a recommendation as possible to the user, but in contributing to increasing the "efficiency" of the browsing process by reducing wasted browsing movements and by increasing the likelihood of taking advantage of browsing opportunities.
A dead end is a link that looks like it might be interesting from reading the link text or seeing a link image, but turns out not to be. A garden path is a sequence of links that provide just enough incentive to keep following the path, but ultimately results in a dead end. These may account for a significant percentage of total user browsing time, and is one of the great frustrations of current Web interfaces. Letizia serves the user by helping avoid dead ends and garden paths, which tend not to appear among Letizia's recommendations.
On the other hand, Letizia serves the user by noticing serendipitous connections. Users tend to have "chunky" browsing behavior, spending a coherent interval of time browsing pages on a single topic or a topic and areas related to it, then switching to a [seemingly] completely different topic. Since I once lived in France, I often browse pages related to French news, language, and culture. From this sustained browsing activity, Letizia can pick up my interest in things French. If I then turn to my interest in music and browse pages related to jazz, this interest, too can be noted. If I continue by browsing a calendar of events in the Boston area, bringing me a couple of links away from an announcement about a French jazz festival, this event should be brought to my attention. Thus, Letizia serves an important function in noting the serendipitous connections that occur during browsing.
From a human interface standpoint, people tend to find browsing interfaces more fun than querying interfaces. They don't have to commit in advance to evaluation criteria, and often learn something along the way. The problem with pure browsing interfaces is that they do not take advantage of the computational power of the computer to search large amounts of information rapidly.
Even before the Web, there were many query-oriented interfaces [Dow Jones, Lexis/Nexis, Medline, Compuserve, etc.] which did not achieve the popularity or fire the popular imagination as did the Web. One possible explanation for the sudden growth of the Web is that Mosaic was the first interface that made such a large body of information accessible through a purely browsing interface.
Search agents such as Lycos and Altavista are a way of grafting a query interface onto the browsing interface of the web, so that the benefits of automated searching are obtained. But they replace the desirable browsing interface with a less desirable query interface, reintroducing the problems of such interfaces.
If Web search agents replacing browsing with querying, the idea of Letizia is to replace the query interface of a search engine, with an interface that is more like browsing, namely the standard Netscape interface. Letizia keeps the user within a purely browsing interface while still getting some of the benefit of automated searching.
Bates [Bates 90] provides a broad discussion of the spectrum of strategies people use in information retrieval, from the perspective of library science. Computer interfaces can play a variety of roles as collaborators in the information search process, taking various amounts of initiative ranging from low-level keyword searches to automating high-level, multi-step, content-oriented searches. Letizia-like agents can cut across this spectrum.
[Armstrong, Freytag, Joachims and Mitchell 95] Robert Armstrong, Dayne Freitag, Thorsten Joachims and Tom Mitchell, WebWatcher: A Learning Apprentice for the World Wide Web, in AAAI Spring Symposium on Information Gathering, Stanford, CA, March 1995. http://www.cs.cmu.edu/afs/cs/project/theo-6/web-agent/www/project-home.html
[Balabonovic and Shoham 95] Marko Balabanovic and Yoav Shoham, Learning Information Retrieval Agents: Experiments with Automated Web Browsing, in AAAI Spring Symposium on Information Gathering, Stanford, CA, March 1995. http://flamingo.stanford.edu/users/marko/bio.html
[Bates 90] Marcia Bates, Where should the person stop and the information search interface start? Information Processing & Management, 26, 575-591, 1990. http://www.gse.ucla.edu/facpage/bates.html
[Borges 42] Jorge Luis Borges, The Library of Babel, in Ficciones, Grove Press, 1942. http://www.microserve.net/~thequail/libyrinth/borges.works.html
[Drummond, Holte, and Ionescu 93] C. Drummond, R. Holte, D. Ionescu, Accelerating Browsing by Automatically Inferring a User's Search Goal. Proceedings of the Eighth Knowledge-Based Software Engineering Conference pp. 160-167. http://www.csi.uottawa.ca:80/~holte/Learning/index.html
[Etzioni and Weld 94] Oren Etzioni and Daniel Weld, A Softbot-Based Interface to the Internet, Communications of the ACM, July 1994. http://www.cs.washington.edu/homes/weld/pubs.html
[Holte and Drummond 93] Robert C. Holte and Chris Drummond, A Learning Apprentice For Browsing, AAAI Spring Symposium on Software Agents, 1994. http://www.csi.uottawa.ca:80/~holte/Learning/index.html
[Knoblock, Arens and Hsu 94] Craig A. Knoblock, Yigal Arens, and Chun-Nan Hsu Cooperating Agents for Information Retrieval Proceedings of the Second International Conference on Cooperative Information Systems, Toronto, Ontario, Canada, University of Toronto Press, 1994. http://www.isi.edu/sims/knoblock/info-agents.html
[Koster 94] M. Koster, World Wide Web Wanderers, Spiders and Robots, http:// web.nexor.co.uk/ mak/doc/robots/robots.html
[Lieberman 95] Henry Lieberman, Letizia: An Agent That Assists Web Browsing, International Joint Conference on Artificial Intelligence, MontrŽal, August 1995. http://lieber.www.media.mit.edu/people/lieber/Lieberary/Letizia/Letizia.html
[Lehnert and Sundheim 91] Wendy Lehnert and B. Sundheim, A Performance Evaluation of Text-Analysis Technologies, AI Magazine, p. 81-94., 1991. http://ciir.cs.umass.edu/info/psfiles/tepubs/tepubs.html
[Perkowitz and Etzioni 95] Mike Perkowitz and Oren Etzioni, Category Translation: Learning to Understand Information on the Internet, International Joint Conference on Artificial Intelligence, MontrŽal, August 1995. http://www.cs.washington.edu/homes/map/ila.html
[Rhodes and Starner 96]B. J. Rhodes and Thad Starner, The Remembrance Agent, http://www.media.mit.edu/~rhodes/remembrance.html
[Salton 89] G. Salton, Automatic Text Processing: The Transformation, Analysis and Retrieval of Information by Computer, Addison Wesley, 1989.