Media Laboratory, Massachusetts Institute of Technology, Cambridge, Mass., USA
Abstract. The traditional field of Machine Learning is concerned with techniques for modifying the behavior of a computer agent over time in order to improve its usefulness to people. This problem has traditionally been formulated as an abstract mathematical problem of inducing a generalized function from assertions representing the "perceptions" or "experience" of the agent. This paper argues that this formulation of the Machine Learning problem is unnecessarily restrictive, and leaves out consideration of interaction between the human teacher and the computer learner during the learning process. Issues such as graphical representation of the input examples and visible feedback about the results of the learning process cannot be abstracted out because they are critical determinants of what learning problems the user will ask the system to solve, and whether the user will be satisfied with the system's behavior. Programming by Example [or Programming by Demonstration] systems try to integrate modern graphical user interfaces with Machine Learning techniques, and thus run up against these issues. While traditional learning techniques are useful for Programming by Example, they must be evaluated in terms of how they affect user interaction rather than just by such abstract measures as "speed" of learning or expressiveness of learned descriptions.
Key Words. Machine Learning, Programming by Demonstration, Programming by Example, User Interface
INTRODUCTION
The workshop description poses the question, "Is interaction the key to machine learning applications?" The purpose of this paper is to answer the question in the affirmative.
The field of Machine Learning has made many advances in inductive algorithms in recent years, but these results have been slow to make their way into implemented applications. Programming by Example [or Programming by Demonstration] has been one of the principal research areas that has tried to apply some learning techniques to interactive graphical interfaces in commonly used applications: word processors, graphical editors, spreadsheets, iconic file systems [Cypher, ed. 93]. These systems generally record user actions, such as menu commands, icon selections, and typing, while the user demonstrates a procedure on a concrete example. The system generalizes the sequence of actions, and learns a new procedure that can then be applied in similar, analogous examples.
These systems use a variety of learning algorithms, but all share a strong concern with the dynamics of user interaction. Their experience teaches some important lessons about how machine learning algorithms can be applied in practice, that are not usually fully considered in the machine learning literature.
IS LEARNING A MAPPING FROM EXAMPLES TO DESCRIPTIONS?
First, we have to ask ourselves, what is machine learning trying to do? The object of machine learning is to improve the behavior of a computer over time by having the computer process input, usually in the form of concrete examples of data, and change its behavior so that it can more effectively process similar input in the future. This can take many forms, such as a parameter-controlled algorithm that can adjust its parameters each time it receives input.
In many discussions of learning, there is often an assumption, sometimes implicit, that the learning problem can be simply represented as a function from the input examples to some form of generalized description: a set of criteria for classifying examples, a generalized algorithm.
There is then a measure of how "good" that learning algorithm is -- whether the algorithm correctly classifies a set of examples, whether the algorithm can learn the shortest possible description from a set of examples, whether a generalized algorithm can handle a given set of cases. The algorithm is sometimes evaluated by how "fast" it is, that is, how many examples it may take to converge on a given description.
This abstraction of the machine learning problem assumes that the "I/O" behavior of the system -- how the examples are input to the system, how the system communicates the result of its learning process -- is relatively unimportant. All that counts is the mapping between examples and generalizations. The user interface to the system is abstracted away.
The problem with this kind of abstraction is that it assumes that any measure of how "good" the learning algorithm is can be independent of the user interface. In fact, this is not true at all. Some learning algorithms will work better or worse depending on how they are presented to the user. A learning algorithm that is "theoretically" better might be worse in practice if, for example, input is not in a form that the user finds convenient to provide, the system cannot provide informative feedback on what it is learning, the algorithm is not incremental enough, or the system cannot provide suitable explanation for why it took the actions it did.
For an interactive learning system such as a Programming by Example system, the user's choices as to what input to provide the system, and what generalizations to expect from the system are highly dependent upon the interactive context. Furthermore, the user is also a "learning system", so that experience with the system will cause the user to change his or her behavior over time in order to work effectively with the learning system.
It is true that "all other things being equal", algorithms that learn faster, have the most expressive power, etc. are more desirable. Yet interface concerns are so strong in practical learning systems, that all other things are rarely equal.
MACHINE LEARNING IS AN INTERACTION PROBLEM
To see why this is so, we need to make an analogy between machine learning and human education. Programming by Example is probably the area of machine learning that takes this analogy most seriously. It takes as its metaphor that teaching the machine should be like teaching a human student. Since it is a psychological fact that people learn best by example, it is only natural that we should use interactively presented examples as the means of instructing a machine.
In human education, effective learning occurs not solely as a result of an optimal presentation method on the part of the teacher, nor as the result of an optimal learning method on the part of the student. What is most important is that there be an effective teacher-student interaction.
A consequence of this is that a variety of particular presentation and interpretation strategies might be effective, providing that both the teacher and the student find themselves able to communicate effectively with them, including feedback to verify what has been learned. There is no such thing as an optimal learning algorithm, or optimal teaching strategy, considered abstractly apart from the capabilities and concerns of both the teacher and the student.
Thus the machine learning problem is really one of interaction. The key is to establish an interaction language for which the human teacher finds it easy to convey notions of interest, and at the same time, for which the computer as student is capable of learning the appropriate inferences. The "user-friendliness" of the interaction for the teacher is as important as the logical power of the inference method employed by the student.
INFERENCE METHODS AND INTERACTION
It is typically assumed in traditional machine learning that "more powerful" learning algorithms -- those that learn more general descriptions quickly from few examples -- are uniformly better than less powerful strategies that don't jump to conclusions as quickly. However, in interactive systems, there is a tradeoff between the "power" of a machine learning algorithm and the understandability of the system's behavior to the user. More powerful inference mechanisms allow the teacher to present ideas of greater complexity with less input, but at the price that it may be harder for the teacher to understand just how to convey a desired generalization, and it becomes harder for the system to present, in a clear and understandable manner, what it has learned and why.
The problem is that the user is trying to form a conceptual model of what the system can and cannot do, at the same time as he or she is trying to use the system to solve particular problems. It is often better to start with a simple inductive algorithm, so that the user can build up confidence and trust, and perhaps to slowly "crank up" the inductive power over time and under the control and consent of the user.
Machine learning divides into supervised and unsupervised learning. Essentially, learning in interactive contexts such as Programming by Example systems is always supervised learning, in that the user supervises the results of the learning algorithm by its effects in the interface. The user interface determines the nature of the supervision and feedback provided to the learning algorithm.
The traditional discussions of machine learning tend also to assume that the learning process is divided sharply into temporal phases. The learning process is assumed to start with input data, which is often assumed to be all available at the start of the learning process. Then there is a training phase, where the examples are presented to the system and the system computes a general description. Finally, there is a teaching phase where the descriptions are tested against new examples not originally in the training set.
In interactive applications, however, these phases are interleaved and affect each other. Typically, some initial data is presented interactively, but without the requirement that the complete training set be available at once. The system performs some generalization, and provides visual feedback to the user about the effect of both the particular example and the generalization produced. The user will choose to present examples that both have a desired immediate effect, and, if he or she is conversant with the learning algorithm, those that will tend to produce the desired generalizations. The feedback received from the system about both the example and its generalization will affect what generalizations are desired, what hints, if any, are given to the system, what further examples are used for testing, and also what new examples are used for further training. Examples that do not have the desired interactive effect can be designated as negative examples for training.
INTERFACE IMPLICATIONS OF SYMBOLIC VS. CONNECTIONIST APPROACHES
Connectionist approaches, particularly, pose problems in an interactive context. They typically require large numbers of examples to work well, relying on the statistical properties of input and algorithms to develop over time. If there is a one-to-one correspondence between user actions and input to the learning algorithm, it will require a large number of user actions to be effective, which tries the patience of the user.
To establish trust in user interaction, it is important that the learning system be able to explain, especially at first, why it made the decisions that it did, and because connectionist algorithms do not give ready access to concise explanations in terms that make sense to the user, users may not come to trust them easily. Such an effect is evident with software like Open Sesame, a commercial learning agent that uses connectionist learning techniques. While the interaction patterns learned by Open Sesame can often be useful, it is not always evident why particular patterns were chosen by the software, nor how the user might influence it to choose some over others.
Finally, a big advantage of connectionist algorithms is that they are able to learn without supervision or explicit hints. But this is not such an important advantage for learning from interactive user actions, because the user is often able and willing to interactively supply hints that explain actions [Lieberman 94]. Many Programming by Example systems adopt a "show and tell" mode that interleaves example input with hints and explanations, just as in human teaching.
ADAPTING A MACHINE LEARNING TECHNIQUE FOR INTERACTION: EXPLANATION-BASED LEARNING
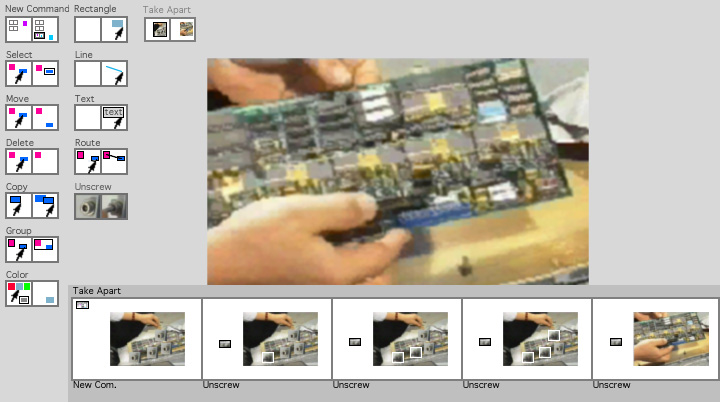
Mondrian [Lieberman 93, 94] is an object-oriented graphical editor that learns new graphical editing procedures by example. It has a simple learning system that uses a form of explanation-based generalization. A study of how explanation-based generalization techniques fit into Mondrian's interface is a good example of how machine learning techniques can be applied in the context of interactive user interfaces.
The learning method employed by Mondrian had its origin with Tinker (Lieberman 93) and is similar to classic explanation-based generalization. The major difference is the order of "explanations", which is of little theoretical import, but makes a major impact on the usability of this learning technique.
Classical explanation-based generalization is a "batch" operation in that the explanation is presented all at once, together with the example. The generalization algorithm produces a generalization from the example and the explanation, which explains to the system "how" the example exemplifies the concept.
The problem with this as a paradigm for interactive construction of generalizations is that the user is, typically, more confident in his or her choice of examples than in the details of explanation steps, or even in the choice of the exact generalization desired. Feedback from the system on the intermediate steps in the construction of a complex explanation is of vital importance.
Especially in domains where the examples are graphical, or can be visualized graphically, immediate graphical feedback can be of immense help to the user in deciding how to explain the example to the system in a way that will cause a desired generalization to emerge. It is not uncommon for the user to realize, in the course of explaining an example, that a related alternative generalization is actually more desirable than the one originally envisaged. The presence or absence of appropriate feedback concerning the relationship between the example and the explanation can make the difference between the usability or impracticality of explanation-based techniques in an interactive interface.
The solution is for the user to provide the "explanation", and the system to construct the generalization, incrementally. We can take advantage of the inherent feedback loop of an interactive interface. At each step, the visible state of the screen indicates the current state of the example, and the explanation is provided by invoking one of the interactive operations, by selecting a menu item or icon. Feedback is generated by the redisplay of the screen, indicating the new state of the example.
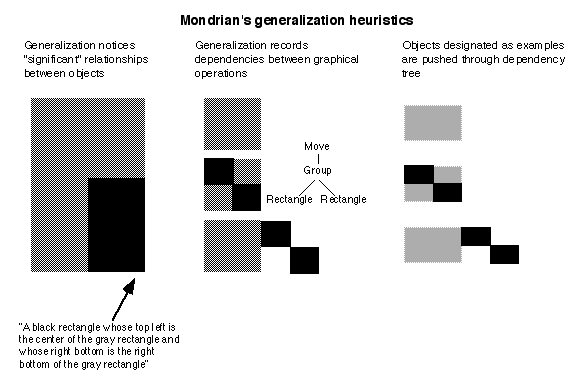
The "explanation" produced by Mondrian in its world of graphical interaction is a recorded dependency tree of user interface actions, which it generalizes to form a procedure that can be applied to other examples in the future. At the start of the demonstration, the user designates a set of objects as "examples", arguments to the procedure being defined by the demonstration. As the user performs actions in the interface involving those examples, the system constructs a dependency tree of graphical operations and their values. Designating an object as an example gives the system license to construct generalizations involving that object, and generalized objects are propagated through the dependency tree of operations.
INTERACTION AFFECTS THE LEARNING BIAS
Mondrian has a learning bias, which consists of a set of geometric relations that it uses to describe the graphical objects involved in each operation. These initially consist of geometric relations such as left, top, right, bottom, center, above, below, etc. The system is also biased towards relations that involve the example objects, to reduce the possibility of accidental alignments.
The bias can be dynamically affected by user interaction. In [Stoehr and Lieberman 95], speech recognition is used to accept verbal hints while the learning process is going on. This can change the interpretation of objects, even from one step in the procedure to another.
Another way to affect the system's learning dynamically is to teach it new relations. We do this by graphical annotation [Lieberman 93]. If the object is represented graphically, the user can point to different parts of the picture and attach textual labels that designate that object. The labels can be grouped into part-whole relations, and the system will subsequently use those relations in describing the objects. We have found graphical annotation a natural way for a non-expert user to introduce new conceptual descriptions while the learning process is taking place.
GRAPHICAL AND AUDIO FEEDBACK ABOUT GENERALIZATION
Speech output is used to verbally communicate the explanation of the procedure step generated by the system immediately after it is performed by the user. The system has a simple natural language generator that constructs English sentences that report the generalization learned by the system. For the repair procedure demonstrated above, the first step would be described as, "Unscrew the left bottom screw of the object that is the first argument to the procedure".
Speech input and output are advantageous because they do not interfere with the drawing task, and people naturally adopt a "show and tell" teaching strategy. This feedback is essential for the user in determining what examples to show, what the next step of the procedure should be, and if the system is correctly understanding the user's intent.
The system also gives graphical feedback about the generalized procedure in the form of a storyboard, a comic-strip like sequence of saved graphical states of the procedure, each one captioned with the natural language sentence generated to verbally explain the generalized procedure step learned by the system. Again, it is important that this feedback is made available incrementally.
The graphical and audio feedback are more comprehensible to the user as feedback about the result of the generalization process than is the Lisp program that the system synthesizes as a result of the demonstration, shown below. Representing the result of generalization as propositions or descriptive assertions would also have the same effect.
(DEFUN TAKE-APART (INTERACTOR SELECTION)
(UNSCREW-ACTION INTERACTOR
(FIND-SCREW-NAMED (NTH 0 SELECTION)
'RIGHT-BOTTOM))
(UNSCREW-ACTION INTERACTOR
(FIND-SCREW-NAMED (NTH 0 SELECTION)
'RIGHT-TOP))
(UNSCREW-ACTION INTERACTOR
(FIND-SCREW-NAMED (NTH 0 SELECTION) 'LEFT-TOP))
(UNSCREW-ACTION INTERACTOR
(FIND-SCREW-NAMED (NTH 0 SELECTION)
'RIGHT-CENTER)))
CONCLUSION
A common thread among these interaction techniques is that they make the operation of the explanation-based learner incremental, and immediately visible to the user, through examples in the interface, using graphics and verbal feedback suitable for non-expert users. It is these characteristics, in addition to the power of the learning algorithm itself, which make the explanation-based learning effective for the interactive graphics application. Regardless of the learning algorithm chosen for a given application, interface issues are not just cosmetic or secondary, but instead an integral part of what it means for a machine to learn.
ACKNOWLEDGMENTS
David Maulsby provided helpful feedback on this paper. Support for the work described here has been provided principally by Alenia, Apple Computer, ARPA/JNIDS, and the National Science Foundation, and other sponsors of the MIT Media Lab.
REFERENCES
Charles River Analytics, Open Sesame [software product], A Learning Agent for the Macintosh, 55 Wheeler St., Cambridge, Mass.
Cypher, ed. (1993) Watch What I Do: Programming by Demonstration, MIT Press, Cambridge, Mass.
Lieberman, H., (1993) Mondrian: A Teachable Graphical Editor, in [Cypher, ed. 93].
Lieberman, H. (1993) Tinker, a Programming by Demonstration System for Beginning Programmers, in [Cypher, ed. 93].
Lieberman, H. (1993) Graphical Annotation as a Visual Language for Specifying Generalization Relations, in IEEE Symposium on Visual Languages, Bergen, Norway, 1993.
Lieberman, H., (1994) A User Interface for Knowledge Acquisition, in Conference of the American Association for Artificial Intelligence, Seattle, August 1994.
Stoehr, E. and Lieberman, H. (1995) Hearing Aid: Adding Verbal Hints to a Learning Interface, submitted to ACM Multimedia 1995.
_________________________________________