ROO: A DISTRIBUTED AI TOOLKIT FOR BELIEF BASED REASONING AGENTS
National Research Council
AI Research Branch, MS 269-2
NASA Ames Research Center
Moffett Field, CA 94035-1000 USA
e-mail: mason@ptolemy.arc.nasa.gov
ABSTRACT
ROO, Rule-oriented cOOperative problem-solving tOOlkit, is a toolkit
for building and experimenting with rule-based cooperative assumption-based
reasoning systems. ROO has evolved from experience with three widely varying
applications: distributed interpretation for global networks of seismic
monitoring stations in Comprehensive Test Ban Treaty Verification, distributed
planetary exploration using hybrid reactive-planning ISX-Robotics T-1 micro-rovers,
and distributed scheduling for global networks of robotic telescopes. The
basic components of ROO include 1) a multi-context, multi-agent assumption-based
TMS, the DATMS, 2) the belief-based agent programming language, BBRL, which
provides agents with access to the history of belief states to selectively
focus among incoming results and supports creation of heterogeneous CKBS
by promoting a separation between socializing and domain problem solving,
and 3) the Multi-Agent Test Environment, MATE, that alleviates much of
the tedium of running experiments with CKBS, including automatic network
resource allocation, monitoring and executing sequences of experiments
without human intervention, and automatic archival of experiment results
and messages.
1 INTRODUCTION
As developers of Cooperative Knowledge Based Systems (CKBS) we are particularly
concerned with engineering and experimenting with protocols for communication
and cooperation. Effective coordination of problem solver agents cannot
be considered by single message exchange. Instead, communication occurs
through protocols for informing, requesting, and convincing. Cooperation
among knowledge based systems, or problem solving agents, requires not
only that agents reason about a problem domain, but they must also reason
about when to communicate with other agents, which agents to communicate
with, and what to say. ROO, Rule-oriented cOOperative problem-solving tOOlkit,
is a building-block approach to creating CKBS applications that emphasizes
support for designing and experimenting with communication and problem
solving protocols.
The structure of ROO was motivated by experience with three widely varying
distributed systems: NETSEA II - a result-sharing, collaborative interpretation
network for global seismic monitoring for a Comprehensive Test Ban Treaty
[16], where each KBS agent had the task of determining the number and location
of seismic events for a particular geological or political region 1 ),
EXPLORE-TEAM - a team of hybrid reactive- deliberative agents, each controlling
an ISX Robotics T-1 micro rover for planetary exploration, and GNAT - a
task-sharing, collaborative scheduling network for Globally Networked Automatic
Telescopes[18], where each agent was responsible for scheduling telescope
time for a particular astronomical observatory 2. ROO contains the tools
we have found essential in developing cooperative distributed problem solving
systems: an agent architecture, a corresponding agent programming language
to support the architecture, and a distributed testing environment.
Each agent program is composed of a coordination problem solving module
expressed in terms of a rule oriented KBS, and a domain problem solving
module, which may take any form. The agent language, BBRL - Belief Based
Rule Language, provides for 1) the open expression of communication operations,
2) an agent interface to a multi-context distributed truth maintenance
system, the DATMS[17], and 3) permits invokation of problem solver modules
and communication primitives through pattern directed inference rules,
thus supporting the encoding of situation-based communication and coordination
strategies. MATE - the Multi-Agent Test Environment [15] relieves the developer
from much of the tedium involved in running CKBS experiments including
network resource allocation (through a program called "NOSE"), initiating
and monitoring experiments over a I,AN or WAN - restarting KBS agents if
necessary and possible, and automatic archival of communications and performance
information. using MATE, the CKBS developer creates a problem-solving setting
by choosing the rule bases, number of agents, inference engine, data sets,
and communication strategy. Experiments may be run automatically (without
human intervention) or manually, as when debugging single agents, new inter-processor
communication code, or a particular multi-agent scenario.
1 Prototype development and extended experimentation for this system was conducted at Lawrence Livermore National Laboratory.
2 Prototypes for EXPLORE-TEAM and GNAT were both developed at NASA Ames
Research Center.
2 AGENT ARCHITECTURE
The agent architecture consists of a social component, expressed as a Knowledge Based System (KBS), and a problem solving component, that may take any form and is accessed by actions of the social component. The basic philosophy of the agent architecture is that coordination knowledge, that is, knowledge about communication and problem solving cooperation, is something agents explicitly reason about and should be separated from domain problem solving knowledge. This perspective was developed during work on the second distributed application, EXPLORE-TEAM, and corroborates the observations of Jennings regarding the need for social levels of knowledge in our computational models of cognitive agents [11]. The view taken by this agent design is that communication, like problem solving, is a controlled and deliberative action taken by an intelligent agent charged with the responsibility of interacting with other agents in a shared computational environment.
The practical utility of an agent architecture which features an explicit cooperatior~ knowledge level is three-fold. First, by explicitly separating social knowledge from problem solving knowledge, it becomes easier to engineer heterogeneous collaborative problem solving systems (where one agent's domain knowledge may be represented as a procedure such as a large Fortran simulation, another as queries to a DBMS or information navigation system, and yet another as KBS) as the representation of problem solving knowledge is now independent of the representation of social knowledge.
Second, it presents solutions to some of the software engineering problems related to constructing CKBS software. We have found this is one way our existing single- agent problem solvers can be engineered to work together, by adding a layer of "social skills". The division also permits parallel development and testing of software for the problem domain and for software related to collaboration. The division also addresses the problems of creating evolutionary software. As with problem solving knowledge in a single KBS agent, we find that our understanding
of the knowledge required for coordinated collaboration unfolds as the design and analysis of basic cooperation scenarios in a domain proceeds. By insulating the two types of knowledge, we can develop the collaborative problem solver agent as a single problem solving system whose "social skills" improve over time.
Third, it enables us to build computational models of the social phenomena
that occur during interactive problem solving. This model of collaboration
permits a better understanding of the nature of collaboration and can direct
the identification of primitive communication and coordination operations
(and their various compositions) that give rise (or not) to coordination
during problem solving. At the same time, such models take steps towards
the larger goal of building a preliminary taxonomy of basic cooperation
scenarios and collaborative problem solving methods.
3 BBRL- A BELIEF-BASED AGENT LANGUAGE
The Belief-Based Rule Language, BBRL, is an interpreted rule-based agent programming language that directly encodes the coordination component of the agent architecture. Optionally, it may also be used to express the domain problem solving component, as depicted by the BBRL grammar in table 1 describing an agent program. BBRL supports explicit representation of cooperation and communication knowledge through pattern directed situation-action rules. BBRL is a generally expressive medium, making no commitment to a particular representational form, and can therefore be used to encode many representations. The knowledge model used is assertions, implemented as triplets. In general, both the LHS and RHS of situation- action rules may be arbitrary Lisp expressions that reference assertions. Three classes of situation-action rules are supported in a BBRL agent program: inference (THINK- rules), communication (TALK-rules), and belief-revision or truth-maintenance (REVISE-rules).
Inference Rules
Inference rules provide the basic reasoning facility for coordination
and take the general form shown in table 2. The LHS of an inference rule
provides access to the assertions data base through a TMS interface that
allows reference to the full history of an assertion's belief status: BELIEVED,
DISBELIEVED, UNKNOWN, DISBELIEVED-OR-UNKNOWN, KNOWN. As a result, the actions
an agent takes are not restricted to depend on the current set of beliefs,
but on the full history of the agent's previous belief states and actions.
<Agent-Program> ::= <Coordination-Module>
<ProblemSolver-Module>
<Coordination-Module> ::= <BBRL-Agent-Program>
<ProblemSolver- Module > :: = < BBRL- Agent-Program > | <External-Software>
<ExternalSoftware> ::= <Lisp-Program> | <For/ran-Program> |<DBMS-Program> | <C-Program>
<BBRL-Agent-Program> ::= <THINK-RULE>+ | <TALK-RULE>* | <REVISE-RULE>*
Table 1: BNF grammar for BBRL Agent program.
This feature has proven useful in preventing the rediscovery of inferences
in result- sharing CKBSs. Presently, research towards controlling communication
among result- sharing agents has largely focused on techniques for restricting
the transmission of messages (ea. organization structuring, meta-plans,
planning). Our instincts would have us believe that the best form of communication
in resultsharing networks is the narrow casting of results towards agents
that actually need the results. In the seismic monitoring domain it was
difficult to predict on-line which agents (which seismic stations) actually
needed help. We were thus motivated to find a way of using broadcast communication
without imposing extra problem solving on agents who did not need the in-coming
information. Much to our surprise, we found through experimentation (for
details, see [19]) that we were able to obtain the solution quality that
would come with broadcast result-sharing strategies, paying very little
in the way of communication overhead, use of working memory, etc., by using
an explicit reference to the history of an agent's previous problem solving
(as expressed through our states of belief) in pattern matching. The following
example rule was taken from the seismic monitoring domain. Each agent has
the task of interpreting data from a particular geological region or seismic
station and exchanges full or partial interpretations in order to help
each other focus the application of computationally expensive signal processing
to selected regions of data, or PICKS. An interpretation is formed by alternatively
applying symbolic reasoning and numerical processes (signal processing)
to the seismic data stream.
The rule USE-PICK-HINT-TO-FIND-EVENT describes the heuristic where an
agent may use clues from an interpretation formed at another seismic station
(on a different data stream) to guide its application of signal processing
(an expensive computation) when trying to form an interpretation of its
own seismic
(THINK-rule USE-PICK-HINT-TO-FIND-EVENT
((BELIEVED
((FOREIGN-STATION instance $other)
($other interpretation $eventl)
($eventl has_phase $phase)
($phase id $id)
($phase pick $pickhint)
($pickhint begin_time $bl)))
(UNKNOWN
((FOREIGN-PICK instance $p) ($p begin_time $b2)
(! (< (abs (- $bT $b2)) O.O1)) ))
(UNKNOWN
((PICK instance $p)
($p begin_time $b2)
(! (< (abs (- $bT $b2)) O.Ol)))))
(ESTIMATE-PICKS)
(ASSUME ((FOREIGN- PICK instance $pickhint)
($other pick $pickLint))))
data stream. The preference list for this rule indicates that if both USE-PICKHINT-TO- FIND-EVENT and another rule ESTIMATE-PICK-HINTS are ready to fire, the preference should be to execute ESTIMATE-PICK-HINTS first. In other words, the agent choses to explore its own ideas on where to look for solutions before using incoming hints from other agents. The Believed-Clause in the rule describes the situation where the agent believes the interpretation of another agent's data. There are two Unknown-Clauses. The first one describes the state where the agent has not already explored a similar clue from another agent. Here "knowing" refers to a fact which may either be believed or disbelieved, and that "unknown" refers to a fact which is neither believed nor disbelieved. This prevents the agent from re-exploring a clue like the one it has already considered, regardless of whether or not the clue was useful. The second Unknown-Clause prevents the agent from wasting time on clues that are in proximity to a PICK it has already explored.
Tf the agent developer simply refers to BELIEVED assertions only, the
interface is more like that of a conventional belief revision system interface,
where an assertion is believed exactly when it can be found in the system's
data base. An example of the use of this type of rule occurs in the robotic
telescope scheduling domain. In the following rule, an agent has detected
its telescope no longer has
status 'operational, so it creates a request for its highest priority
observing task, watching for super nova, to be rescheduled on another telescope.
(THINK-rule MAKE-REQUEST-FOR-RESCHEDULE
((BELIEVED
((AGENT instance $s)
($s status $status)
($s remaining-obs $r)
(! (and (not (equal $r nil))
(not
(equal $status 'operational)))))))
()
(let ((R1 (create-anode))
(D1 (create-anode)))
(ASSUME
((REQUEST instance R1)
(R1 priority '10)
(R1 reason $status)
(R1 obs-type 'super-nova)
(R1 status 'guest-observer)
(R1 agent 'Henry)
(R1 station 'Ml-Hopkins)
(DIALOGUE instance D1)
(D1 request R1)
(D1 status 'send-request)))))
Access to domain problem solving modules is through reference on the
RHS of an inference rule. In general, the RHS of an inference rule may
take on any Lisp form, as shown by the use of the let statement
in the previous example. This allows for the invokation of many varieties
of problem solvers through the foreign function interface. Locally generated
assertions are added to the agent's data base through the forms ASSERT,
ASSUME, and GIVEN. Externally generated assertions may be added by message
receipt in the agent's main control loop. The corresponding belief maintenance
structures for each of ASSERT, ASSUME, GIVEN and externally generated facts
are discussed in section 5.
Communication Rules
Communication rules or TALK-rules are used to send domain specific messages to other agents and takes the general form shown in table 3.
<TALK-rule> ::= ( TALK-rule <Rule-Name> <COMM-Situation> <COMM-Action> )
<COMM-Situation> ::= ( <Believed-Clause>+ )
<COMM-Action> ::= ( SEND <Destination>
<Message> [ <LISP-Form> ]
<Destination> ::= <LISP-Form> | <Comm-Policy> | ( <Agent-Id>+
) | $Var
Table 3. B NF grammar for Coordination-Module TALK-rules.
The LHS specifies a state of the agent's assertion knowledge. The RHS specifies a destination that evaluates to a list of agents, and a Lisp form which may contain references to assertions from the Believed-Clause. The message itself is a, form that is evaluated by the interpreter and then written to the message buffer. The message is expected to contain communication verbs relevant to the particular domain and agent.
For example, the rule SEND-REPLY describes the situation where the agent
(TALK-rule SEND-REPLY
((BELIEVED
((DIALOGUE instance $d)
(REPLY instance $r)
($d agent $a)
($r status $decision))))
(SEND $a "((REPLY instance $r)
($r status $decision))"))
is preparing to send the next message in an on-going sequence of exchanges or dialogue with another agent. The LHS indicates the agent believes it has now made a decision regarding a previous request and has created the REPLY record in its dialogue database. The RHS specifies a message to send to the agent referred to in the dialogue record. The message contains the reply as well as the message type. This simple form finesses the problem of choosing a set of communication operations all together by including the name of the communication operation as part of the message body. This form of the communication rule was derived
after hard coding communication forms involving domain specific verbs,
such as REQUEST, INFORM, REPLY, and so on, It has been our experience that
the c hoice and sequence of communication operations can vary a great deal
from one domain to the next, and that the communication protocol for agents
must easily evolve as we learn more about coordination and cooperation
in the domain. This new form allows us to abstract away from a particular
set of communication operations and allows for the open expression of communication
primitives, which the developer may design without restriction.
Belief Revision Rules
Belief Revision rules are optional and may be used to express knowledge
about groups of assertions that are incompatible 3.
<REVISE-rule> ::= ( REVISE-rule <Rule-Name> <Revise-Situation> ( <Preference-List> ) <Revise-Action> )
<Revise-Situation> ::=( <Believed-Clause>+ )
<Preference-List> ::= ( <Rule-Name> )
<Revise-Action> ::=( CONTRADICT ( <Clause>+ )
<Clause> ::=<fact> | <fact> <Clause>
<fact> ::= ( $Var <link> $Var ) | ( $Var <link> Value )
Table 4: BNF grammar for Coordination-Module REVISE-rules.
As shown in table 4 the LHS of the REVISE-rule form is a pattern of assertions that together are incompatible. The RHS consists of the form (CONTRADICT (fact- list)) where fact-list is the set of culprits, or facts, involved in the inconsistency. While this formulation of contradiction knowledge is inherently domain dependent, it gives the problem solver (in this case, the problem solver is the coordination KBS) finer control over the search for culprits. In fact, there is no searching.
3 This representation of contradiction knowledge flies in the face of those who would ground problem solving in logic, describe inconsistencies in logical terms rather than in domain terms, and attempt to formulate general mechanisms for determining logical inconsistencies. In practise, we find inconsistencies are often a result of domain semantics rather than logical formulations that are posed as panty. Hence, we prefer the term incompatible, rather than inconsistent, when referring to the problem of belief revision.
4 Belief Revision and The DATMS
Truth Maintenance Systems have proven to be of general utility in a
wide variety of problems including software requirements verification[5],user
modeling [12], circuit analysis [7], vision [22,2], signal interpretation
[20], scientific discovery[24], and analog circuit design [25]. Thus, a
TMS for CKBS architectures can greatly broaden the range of problems addressed
by the CKBS paradigm. A TMS system used in a CKBS context also plays an
important role in debugging and explaining the actions of a system- TMS
dependency records in a CKBS provide a mechanism by which the results derived
by the system as a whole may be traced back to each CKBS agent. The DATMS
was first described in [9]. Since that time a number of other TMS systems
have been designed to complement its functionality or address some of its
limitations (e.g. [1,3,4]).
In general, a number of different kinds of TMS are possible, allowing
for monotonic or non-monotonic just)fications, multiple or single just)fications
for a fact, multiple or single contexts examined at once, probabilistic
or non-probabilistic belief status, and so on. These various TMS "features"
define the dependency structures and the algorithms that maintain them
for a particular style of TMS, and hence directly influence the computational
expense of relying on a TMSbased system.
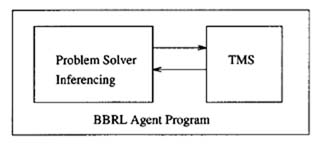
While TMSes seem to have taken on a life in themselves, it is important to keep the idea of a TMS in perspective. Namely, it relieves the problem solver from the burden of belief updating, and should serve as an efficiency mechanism for problem solving. The separation of inference (problem solving) from belief revision (truth maintenance) is largely a successful division and is adopted by the BBRL agent program. This notion is often depicted by the 2-component conceptual problem solver architecture.
A large number of Truth Maintenance Systems have been developed for belief revision in single agents[6,8,14,21,23]. (the interested reader may wish to consult [13] for a complete bibliography.) The manner with which dependencies are recorded divides the TMS literature among two broad categories, single-context (just)fication-based) TMSes and multiple-context (assumption-based) TMSes 4. In single-context systems, each belief is explicitly labeled IN or OIJT to indicate it is (or is not) consistent with the current set of assumptions (context). Agents relying on a single-context TMS must reason with a knowledge base in which every belief must be consistent with a single set of assumptions (context). In multi-context systems, each belief has a label indicating the sets of assumptions (contexts) in which it is consistent. Agents relying on multi-context TMSes may retain several contexts in the knowledge base at once.
The selection of a particular type of TMS should make sense with how the problem solver needs to make inferences and explore the problem space. In CKBSes, we must also be concerned with the potential for global incoherency that can result from logical and physical inconsistency among agents that communicate beliefs which may subsequently be retracted. In order to design coherent multi-agent belief-revision systems, it is important to understand the roles of the problem solver reasoning component and the truth maintenance system in achieving logical and physical consistency.
Suppose we have a result-sharing network of two agents, A1 and A2. If A1 communicates a belief to A2 that, according to A2's perspectives, sensory data, or knowledge, is incompatible with the beliefs of A2, then there exists a logical inconsistency among A1 and A2 and either (a) one of A1 or A2 must revise its beliefs or (b) A2 must represent two distinct belief spaces - one representing its own beliefs and assumptions, and the other representing the beliefs and assumptions of A1. The decision as to whether or not to revise a belief and which of the agents should do so is exactly the issue of logical inconsistency. The responsibility for ensuring logical consistency lies with the problem solver designer and the problem solving reasoning component. Logical consistency may be defined on-line, as when agents A1 and A2 engage in negotiation to determine what they should believe, or off-line, according to domain knowledge, the relation between subproblems, the tolerance for inconsistency in solution synthesis, inter-agent control relationships, etc. The policy for detecting and dealing with logical inconsistencies is defined by the agent designer. Should the problem solver decide to revise a belief to resolve a logical inconsistency, there is now a second issue of coherency, namely, the problem of ensuring that all agents that hold copies of the affected belief(s) are informed about the revision - physical inconsistency. This is the responsibility of the DATMS.
4 A notable third category would be the LTMS, or Logic-based TMS [21].
A clear description of LTMS systems is presented in [23].
The basic idea of the DATMS is the following. Each agent may have a
number of belief spaces (assumptive contexts), the union of which may be
inconsistent. When agents share beliefs, each agent has belief spaces that
are shared. The task of the multi-context D-TMS is to ensure physical consistency
by (1) updating the labels of all facts so as to remove support for a derivation
containing the combination of inconsistent or NOGOOD assumptions, and thereby
prevent any further inferencing based on the incompatible assumptions,
and (2) informing all agents that share belief spaces when a belief space
(set of assumptions) becomes inconsistent so that their labels may be revised.
It is up to the problem-solver to determine when a (logical) inconsistency
arises and inform the DATMS. In this way, a multi-context D-TMS can provide
a general facility for all types of problem decompositions and subsequent
solution formation and synthesis.
A multi-context TMS presents a number of advantages over a single-context
TMS5 for belief revision in CDPS when agents must (1) consider multiple
perspectives (contexts) at once; (2) be able to switch quickly between
agent perspectives (contexts); and (3) allow for disagreement among agents.
Multiple competing views may arise among CKBS from the differing knowledge
each agent brings to a problem, from differing sensory inputs, or from
differing applications of the same knowledge. A single-context multi-agent
belief revision system, the DTMS, is presented in [3].
5 The DATMS
The DATMS uses monotonic just)fications, relies on a non-probabilistic
belief status, allows for the representation of multiple just)fications,
relies on the communication of assumption sets and a record of communication
history of communicated facts to achieving global physical consistency,
and relies on the problem solver to detect logical or domain contradictions.
When inconsistencies are detected, the DATMS uses the communication history
to transmit NOGOOD messages to the affected agents.
Like the belief revision systems of ART and KEE, the DATMS represents each instance of a fact derivation in a separate node. Although we originally developed our fact labels this way for efficiency reasons 6 it has allowed us to maintain the full history of a fact's belief status, and therefore allows the agent to refer to a history of its problem solving. Hence the agent may not only refer to the set of currently believed facts, but also to those which are no longer believed, those which are neither either believed or disbelieved, and those which are disbelieved or unknown.
5 Single-context TMSes are known to incur sign)ficant costs when switching contexts.
6 We were interested in generating all solutions, but wanted a solution to be available as soon as possible, as the problem solver was presenting solutions to a user interface window for review by domain experts. Our profiler showed that when we implemented labels as in deKleer's original ATMS, label manipulation accounted for over half of the CPU time. As a result, we mod)fied the label in this fashion. It is worth noting that by avoiding complex labels we lose the advantage of parallel inference that comes with deKleer's label, but also avoid the "focusing" problem
Representing Beliefs As with a single-agent TMS, the internal
representation for a problem-solver fact is the TMS node. The TMS node
acts as a referent to the inference history and also to the assumptions
supporting a fact asserted by or communicated to the problem-solver. It
is used by the truth maintenance system in determining the fact's belief
status. In the DATMS, an individual TMS-node has the form
< Fact-ID, Justification, Assumption-Set-Los >
where Fact-ID is a globally-unique identifier, Justification is the
inference history for the fact, and Assumption-Set-Los is a set of indices
into the Assumption Data Base. The Assumptions Data Base contains the assumption
sets (contexts) that support problem solver facts. The Fact-ID is a complex
entity comprised of a locally unique fact identifier followed by the identity
of the agent originating the data item.
Fact-lD=<identifier: agent>
Contrary to the distributed operating system goals of viewing objects
independently of their hosts, this identifier is explicitly associated
with the agent responsible for deriving the result. For example, the problem-solver
fact, I, may be represented in the DATMS as < 12: At >, where
12 is the data base index for fact f in problem-solving agent A1.
The identification of a fact
_ gives uniform identification for internally and externally generated results for the purpose of building assumption sets and just)fications from a mixture of internally deduced and communicated facts.
_ provides a way to trace a fact back to each individual agent, supporting global belief revision and an explanation facility.
_ allows an agent to assimilate beliefs of other agents while keeping its own results distinct from those beliefs.
The Justification for an internally deduced fact is the set of facts that directly derive the fact. Communicated facts have Justification "EXTERNAL" since the antecedents reside in an external agent.
The Assumption Data Base contains an assumption set, a communication history, and a label indicating belief status for each fact inferred by or communicated to the agent. Each item in the Assumption Data Base has the form:
< Assumption-Set, Status, Comm-Hist>
The assumption set for a fact indicates the assumptions upon which its
belief ultimately depends (i.e., a fact is believed if its assumption set
is CONSISTENT). These assumption sets correspond to deKleer's environment.
More formally, an assumption set is defined to be a subset of the known
facts. The set of all possible assumption sets is the power set of the
union of known facts in each agent.
Let F = {f i1, f i2, ... f ini}
be the set of known facts in agent i. Then the set of known facts among
a group of k agents is
F = U k i=1 Fi
and F* is the power set. In general, for any assumption set, A, in any agent,
A C F and A e F*
Comm-Hist is a list of agent identifiers that share facts depending on this assumption set. This list is updated each time the problem solver issues a communication to another agent(s).
Problem Solver Interface When the problem-solver creates a new fact, it provides the DATMS with the fact, and the set of antecedents that directly derive the fact, the just)fication. The problem solver interface operations for retrieving belief statuses consists of the "fetch" operators, 'BELIEVED', 'DISBELIEVED', ..., as described in BBRL grammar and previous examples. The problem solver informs the DATMS of inconsistencies it has detected through the CONTRADICT operator. DATMS nodes for communicated facts are created as a result of receiving externally derived facts. The support for these facts exists outside of the receiving agent's world. It makes sense then that the assumption set for a transmitted fact is commit as well 7
7It is unclear how a multi-context multi-agent system could enforce physical consistency without the transmission of assumption sets for shared facts, as locally generated labels for
Contradictions and Truth Maintenance When the problem-solver determines a contradiction among facts has occurred, the function CONTRADICT is invoked to inform the DATMS of the contradiction. The problem-solver provides the DATMS with a list of the culprit facts involved in the contradiction. For example, suppose the DATMS receives the following: (CONTRADI CT '( fi,f2, f3)) The DATMS unions the assumption sets of the culprit facts, f1, f2, f3, and inserts the resulting assumption set into the Assumption Data Base with belief status INCONSISTENT. The assumption set U3=l A(fi) is marked INCONSISTENT. Furthermore, if any assumption set, A, in the Assumption Data Base is such that A ~ U3=l A(fi), then A is marked INCONSISTENT as well. The DATMS then uses the Comm-Hist list to propagate the effects of the contradiction throughout the problem-solving network with a message containing the INCONSISTENT assumption set.
Upon receiving a contradiction message, the received INCONSISTENT assumption
set is treated as though it were locally derived and entered into the Assumption
Data Base; any assumption sets containing it are marked as INCONSISTENT.
In this way agents maintain global consistency - the belief spaces of all
agents could be merged into one multi-context knowledge base with agreement
on the status of any beliefs.
6 MATE - THE MULTI-AGENT TEST ENVIRONMENT
The MATE (Multi-Agent Test Environment) testbed is a collection of experiment management tools for the design, testing, and evaluation of distributed CKBS experiments. MATE provides automatic experiment execution, monitoring, and archiving of results, thus relieving much of the work involved in monitoring and organizing the execution of a collaborative problem solving system. Using MATE, an agent designer can run a series of experimental problem solving scenarios without human intervention through the program "AUTO-MATE" which finds a set of eligible machines and executes pre-configured experimental trial descriptors. Alternatively, the agent designer may run an individual experiment manually, allowing for interaction between the agent designer and one or more single agent debugging environments. MATE tools use several UNIX-based
communicated facts would not contain the assumption sets for which belief
in the fact is valid. As a result, any further inferences involving such
communicated facts could not represent their reliance on the external assumptions,
making it virtually impossible to guarantee physical consistency. In theory,
one might consider devising a system where agents would make requests for
the belief status of external assumption sets each time an inference involving
the fact was attempted, however, in systems where belief revision may occur
during pattern matching, such as when RETE-networks are used, this would
make each inference quite time consuming.
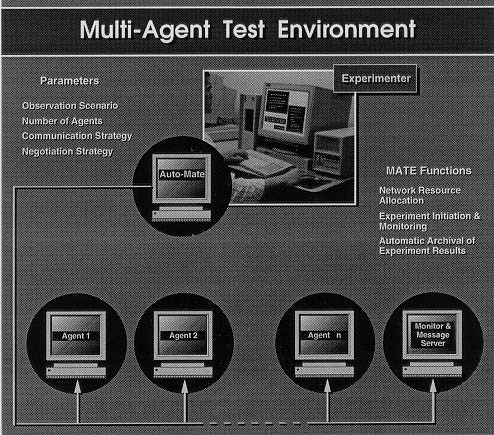
Figure 1: The Multi-Agent lest Environment, MATE, provides a platform
to study cooperative problem solving.
workstations networked via ethernet in a large local-area network (although some workstations did require hops across LANs.) As shown in Figure 1, each workstation runs a single agent that communicates via the local-area network, except for a special workstation that serves as the MATE control center and communication server.
The role of MATE in solving a particular problem solving instance can be described by envisioning the collaborative problem solving software in terms of three layers, the agent, the communications or network support layer, and MATE. An "agent" is composed of an interactive process, such as a Lisp interpreter, the data set(s), and a communication interface.
The communications layer provides four services to the agents: 1) pointto-point,
multi-cast, and broadcast message delivery, 2) transparent translation
between symbolic agent name and physical workstation address, 3) experiment
start synchronization, and 4) experiment termination not)fication.
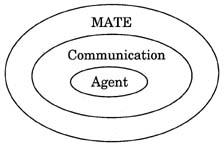
Figure 2: An agent consists of the individual Agent layer, a Communications layer, and the MATE control layer.
The MATE layer serves to orchestrate the execution of the agents and
monitor communications among agents. The MATE layer may also be viewed
as containing all the tools necessary for automating network resource allocation,
experiment monitoring and execution, and automatically archiving experiment
logs and performance information. Currently, we have run experiments with
up to 20 workstations/KBSs. There are 3 main activites associated with
using MATE to conduct experiments: Experiment Configuration, Network Resource
Allocation, and Experiment Execution and Recording.
Experiment Configuration
In manual mode, the developer is guided by an X-window system interface
to select single-agent debugging or a multi-agent problem-solving scenario
where selections are made regarding number of agents, choice of knowledge
bases, inference engines, data sets, and communication strategies. The
interface drives the selection of Lisp load files containing references
to the selected program modules. Alternatively, the developer may specify
a a set of preconfigured experimental trials along with an experiment start
and end time to be run automatically via the program "AUTO-MATE."
Network Resource Allocation
Workstations in the local area network(s) are selected for the experiments by the program, "NOSE". The program NOSE may be executed from the interface,
or from AUTO-MATE. To find suitable workstations, NOSE consults a list
of known available workstations and examines suitability factors such as
cpu load profiles, available working memory, operating system version,
file system, etc. Profiles of the various selected machines are written
to an intermediate file and used by subsequent loading programs to reference
appropriate versions of program modules. In AUTO- MATE, NOSE may be run
as little as once per experimental trial. As many workstations are vacated
in an evening, this was found to be quite sufficient and much less expensive
than more frequent testing such as would occur in a WORM program, for example.
Experiment Execution and Recording
Once the experiment configuration is in place, and a list of capable
machines is created, the CKBS may be initiated by invoking the AUTO-MATE
control program or manually via menu selections. Typically, manual invocation
of the system is performed while debugging new rule sets, inference engines,
etc., as the experimenter is given finer control over execution and can
interact with the Lisp interpreter, run single step, and watch rule tracings
and assumptions data base creation, etc.
For each experimental trial, AUTO-MATE begins by starting the communication
server, watching to ensure it executes successfully. Should the server
have any errors, AUTO-MATE will persistently re-startthe server until it
runs successfully. At this point AUTO-MATE releases a number of remote
shell commands that, after killing off any other stray agent processes,
creates agents on each of n workstations, copying the proper load files,
data sets, communication rules, and so on, for this particular trial.This
part of the experiment system is subject to several types of failures (e.g.
a machine has crashed, the network went down, there is not enough memory
available to start Lisp) so AUTO-MATE closely monitors log files for the
agents. If necessary, AUTO-MATE will try to restart one or more agents
that did not start, and may re-run NOSE looking for other available machines.
REFERENCES
[1] C. Beckstein, et. al. "Supporting Assumption-Based Reasoning in a Distributed Environment," Proceedings of the 12th International Workshop on Distributed Artificial Intelligence, Hidden Valley, Pennsylvania, USA, 1993.
[2] J. Bowen and J. MayLew. "Consistency Maintenance in the REV-graph Environment," TR AIVRU 020, University of Sheffield, 1986.
[3] D. M. Bridgeland and M. N. Huhns. "Distributed Truth Maintenance", Proc. American Association of Artificial Intelligence, Vol. 1, pp. 72-77, 1990.
[4] Alison Cawsey, et. al. "Conflict and Cooperation in a Heterogeneous System," 1992 AAAI Workshop on Cooperation Among Heterogeneous Intelligent Systems, San Jose, California, USA, 1992.
[5] C. Chandra. "Applications of Truth Maintenance Systems to the Development
of Evolutionary Software," Unpublished paper, Dept. of Computer Science,
University of California, Berkeley, 1991.
[6] J. deKleer. "An Assumption Based TMS," Artificial Intelligence
28 (1986), 197- 224.
[7] J. deKleerandB.C. Williams. "Diagnosing Multiple Faults," Artificial Intelligence, 32, No. 1, 1987, 97-130.
[8] J. Doyle. "A Truth Maintenance System," Artificial Intelligence 12, No. 3, November 1979, 495-516.
[9] Les Gasser and Michael Huhns. Distributed Artificial Intelligence, Vol. II., Pitman-Morgan Kaufman, 1989.
[11] N. Jennings. "Towards A Cooperative Knowledge Level For Collaborative Problem Solving," Proc. 10th European Conference on Artificial Intelligence, Vienna, Austria, 1992.
[12] J. Jones and M. Millington. "Modeling Unix Users with an AssumptionBased
Truth Mantenance System: Some Preliminary Findings," in Reason Maintenance
Systems and their Applications, Smith and Kelleher (Eds.), Ellis Horwood
Limited, Chichester, UK. 1988, 134-154.
[13] J. Martins. "The Truth, The Whole Truth, and Nothing But the Truth,"
AI
Magazine,Winter 1990.
[14] J. P. Martins and S. C. Shapiro. "A Model for Belief Revision," Artificial Intelligence 35 (1988).
[15] C. Mason. "MATE: An Experiment While You Sleep Test Bed," AAAI Workshop on Collaborative Design, AAAI Press, 1993.
[16] C. Mason. "Cooperative Assumption-Based Reasoning for Comprehensive Test Ban Treaty Verification," Ph. D. thesis, University of California - Lawrence Livermore National Laboratory, IJCRL Technical Report.
[17] C. Mason and R. Johnson. "DATMS:AFramework for Distributed As
sumption Based Reasoning", Distributed Artificial Intelligence, Vol.
II.,
Eds. Gasser and Huhns, Pitman-Morgan Kaufman, 1989.
[18] C. Mason. "Collaborative Networks of Independent Automatic Telescopes", Astronomy for the Earth and Moon, Ed. D. Pyper-Smith, Astronomical Society of the Pacific Publications, 1993.
[19] C. Mason. "Introspection As Control in Result-Sharing Assumption-Based Reasoning Agents," Distributed Artificial Intelligence Workshop, Seattle, Washington, 1994, in press.
[20] C. Mason, R. Johnson, R. Searfus, D. Lager, and T. Canales, "A
Seismic Event Analyzer for Nuclear Test Ban Treaty Verification" Proc.
Third Intl. Conf on Applications of Artificial Intelligence in Engineering,
August
1988, Stanford, CA.
[21] J. McAllester. "A Three Valued Truth Maintenance System," AI Memo
551, AI Lab, MIT, Cambridge, MA, 1980.
[22] G. Provan. "Efficiency Analysis of Multiple-Context TMSs in Scene
Representation" Proc. Sixth National Conference on Artificial Intelligence,!,
1987.
[23] E. Rich and K. Knight. Introduction to Artificial Intelligence,
2nd
Edition, McGraw-Hill Publishing Co., 1991.
[24] D. Rose and P. Langley. "Chemical Discovery as Belief Revision," in Machine Learning 1, Kluwer Academic Publishers, Boston, Massachusetts, 1986, 423- 451.
[25] R. Stallman, and G. Sussman. "Forward Reasoning and DependencyT)irected- Backtracking In a System For Computer Aided Circuit Analysis," A'lificial Intelligence 9(2):135-196.