MS in Media Arts and Sciences at MIT
Perceptual
Synthesis Engine:
An Audio-Driven Timbre Generator
A
real-time synthesis engine which models and predicts the timbre
of acoustic instruments based on perceptual features extracted from an
audio stream is presented. The thesis describes the modeling sequence
including the analysis of natural sounds, the inference step that finds
the mapping between control and output parameters, the timbre prediction
step, and the sound synthesis. The system enables applications such as
cross-synthesis, pitch shifting or compression of acoustic instruments,
and timbre morphing between instrument families. It is fully implemented
in the Max/MSP environment. The Perceptual Synthesis Engine was developed
for the Hyperviolin as a novel, generic and perceptually meaningful synthesis
technique for non-discretely pitched instruments. |
Submited
to the Program in Media Arts and Sciences,
School of Architecture and Planning,
in partial fulfillment of the requirements for the degree of
Master of Science in Media Arts and Sciences
at the
Massachusetts Institute of Technology
September 2001
Thesis
Supervisor : Tod Machover
Professor of Music and Media
MIT Program in Media Arts and Sciences
Thesis
Reader : Joe Paradiso
Principal Research Scientist
MIT Media Laboratory
Thesis
Reader : Miller Puckette
Professor of Music
University of California, San Diego
Thesis
Reader : Barry Vercoe
Professor of Media Arts and Sciences
MIT Program in Media Arts and Sciences
For more details, Download my Master's Thesis
Sound examples for the female singing voice:
Original female singing voice
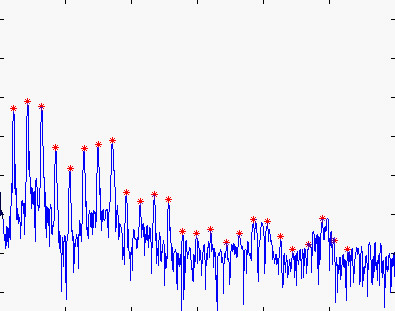
Watch a movie with the peak extraction of 25 harmonics (7.5 Mb)
Re-synthesized female singing voice
with 25 sinusoids
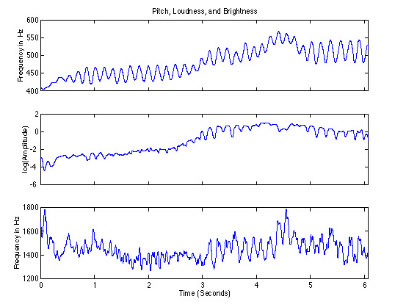
Estimation of three perceptual features: pitch, loudness, and brightness
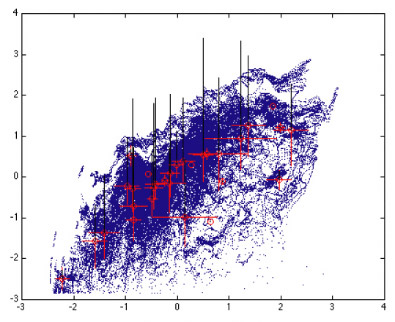
Unsupervized
learning between perceptual features, and spectrum.
Only two normalized axes are represented here: pitch (x), and loudness (y).
The gaussian distributions are depicted in red (height is in black).
Predicted female singing voice from 3
perceptual parameters (real time)
Original violin glissando sound
Predicted female singing voice from analysis
of the previous violin sound (real time)
Loudness control before prediction (real
time)
Brightness control before prediction
(real time)
Pitch modulation control before prediction
(real time, includes input)
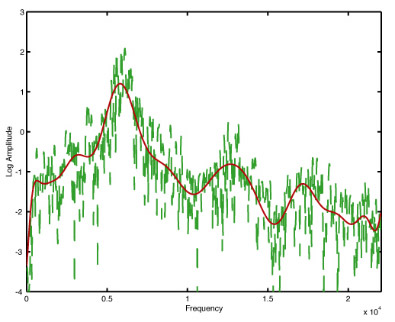
Residue (noise) is modeled with a 25-coefficient polynomial function.
Sound examples for the violin model:
Original
violin (a Stradivarius)
Predicted violin from 3 perceptual parameters
(real time, 30 sinusoids only)
Morphing from violin to female singing voice,
back to violin, with violin input
Special
thanks to Tara Rosenberger Shankar, Youngmoo Kim, Hila Plittman, Joshua
Bell, Nyssim Leford and Michael Broxton for their help with data collection. |