
|
This page describes my current and recent professional life. It is mostly about work examples and my portfolio, but I also included a bit of background as to why I am doing what I am doing, the leadership positions that I held recently and what I achieved in them, the functions I tend to have at these recent positions, and a concise summary of a typical modus operandi of mine in recent positions. In short At the very core, I am a Human-Computer Interaction (HCI) research scientist, inventor, and visionary. I dream up, create, research, design, develop, and patent systems with fundamentally novel user interfaces in the domains of human augmentation (social, knowledge, emotion, etc.), UX of autonomous vehicles (as occupant or pedestrian), augmented reality (visual, auditory, haptics of AR/VR/XR), advanced HCI and HMI, human-robot interaction, aerial robotics, gestural and conversational systems, cognitive and affect sensing, and more. My strengths are "engineering creativity," and connecting the dots of research and emerging technologies to create radically new products and services. I have 20+ years of experience in corporate and academic environments, including MIT, Samsung, Hewlett-Packard, and HARMAN International. Motivation: why, how, and what? Although I have been active in a multitude of (seemingly unrelated) domains, there is actually a common theme that spans most of my professional work: Human Augmentation. I will have to explain this a bit more to put it in context. From a global historical perspective, mankind has only just begun creating technologies with the explicit intention to directly enhance our bodies and minds. Although we have built tools to enhance our motor skills and perception for many millennia already (think "hammer" and "eye glasses"), I am referring to augmentation of higher level mental skills. The augmentation technologies that we do have already, however, have impacted us deeply: for example, mobile phones extend our conversational range and allow us to talk to people almost anywhere on the face of this earth. Mind you, although smartphones just seem like a sensory augmentation, they are actually rather an augmentation of our social interaction potential. This becomes clear when we look at today's smart devices, which intend on enhancing our knowledge, telling us where we are, what other people think and see, and many other useful things. Going way beyond that, it is foreseeable, however, that Human Augmentation technologies even in the near future will enhance us in much more extreme ways: perceptually, cognitively, emotionally, and on many other levels. I am intent on pushing the envelope in this direction, and creating technologies to serve this purpose. And I have been doing so for 35+ years: in order to understand the problem well, I have studied the human psyche in depth for eight years (and got a Psychology degree for it), and then worked on the engineering side at MIT for another eight years (during which I designed a multitude of high tech systems). After that, for the last 15 years in industry, I have put these two perspectives together in order to create technologies, systems, devices, and services. I strongly believe that to create technologies that immediately and explicitly enhance people, and allow us to interact with technology more intuitively, we need to combine deep engineering and deep psychology knowledge, and all shades in between. So, I have worked in the fields of mobile communication, augmented reality, virtual worlds, artificial intelligence, robotics, and many more, and created a series of systems, some as proof-of-concept and some close to a product, that each show how I think we will interact with future technologies. Positions held From 1997 to 2005, I was at the MIT Media Lab as research assistant and lead for about ten research projects in the domain of speech interfaces and mobile communication, conversational and communication agents, embodied agents, and wireless sensor networks. Below are summaries of my MIT projects. I supervised undergraduate researchers (software, robotics, circuit design). I was in close contact with the lab's 150+ industrial sponsors, and gave over 100 presentations, talks, and demonstrations. From 2005 to 2010, I was project leader and principal researcher at Samsung Research in San Jose, CA. I was part of SAIT, the Samsung Advanced Institute of Technology. I was in charge of initiating and managing HCI research projects, and headed a team of PhD level researchers, engineers, and innovators. I envisioned, designed, and developed fundamentally novel user interface concepts, based on original research in the domains of ubiquitous computing, mobile communication, artificial intelligence, robotics, virtual worlds, and augmented reality. One of my larger projects explored new ways how to interact naturally and intuitively with 3D content, such as AR content, virtual worlds, games, etc. I did this on mobile and nomadic devices from cellphones to tablets to laptops to unfolding display devices to portable projection devices and more. I built working prototypes that demonstrate key interaction methods and intelligent user interfaces for natural interaction. Below are summaries of my representative Samsung projects. From 2011 to 2012, I was with HP/Palm, as the director for future concepts and prototyping at Palm: I led, managed, and inspired teams of end-to-end prototyping and research engineers (hardware & software), UI prototyping engineers, and UI production developers (the latter only interim until August 2011) in the webOS Human Interface group. I created working systems of future interaction methods, filed for many patents, and contributed to strategic roadmaps across all of Palm/HP. My Palm projects were in the fields of wand and pen input (e.g., project 3D Pen), mobile 3D interfaces, remote multi-touch interfaces (e.g., project Ghost Fingers), and more. From 2012 to 2020, I was with HARMAN International (since 2018 part of Samsung), as Vice President of Future Experience and AI. My responsibilities included assembling and leading teams of advanced research and prototyping engineers in order to create working prototypes and IP of technologies that will enable radically new UX for future HARMAN products. I also founded and led a large AI team which developed cutting edge ML based solutions for all HARMAN divisions. I was future proofing the current UX of all HARMAN products, from Infotainment (automotive) to Lifestyle Audio (consumer audio) to Professional (professional audio and light). I worked out of Mountain View, California, in the middle of the Silicon Valley. Going beyond the mobile focus I had at Samsung and HP, my HARMAN projects also included future user experiences in cars, and UX synergies between home, mobile, and automotive platforms. I was applying my expertise in conversational systems and spatial interfaces, but was also able to include the interactive spatial audio domain since HARMAN is deeply involved in audio systems of any kind. During the last 3+ decades, I worked on many professional projects. One way to get an idea about the range of the projects I have done is to browse my patents and patent applications: they are essentially blueprints for many of the works I did. As of right now, I hold 180+ granted patents: 90+ U.S., and 90+ non-U.S. Another way is to look at my work samples, as described below. But let me briefly explain first the functions I held. My functions As an engineer, I am an inventor, builder, and implementer who uses software and hardware rapid prototyping tools to create systems from the lowest level (firmware, sensors, actuators) up to highest level applications with GUIs and networking capabilities. Systems I have built at MIT include palm-sized wireless animatronics with full duplex-audio, conversational agents interacting with multiple parties simultaneously, autonomously hovering micro helicopters, laser based micro projectors, and a drawing tool with built in camera and an array of sensors to pick up and draw with visual properties of everyday objects. As an HCI researcher, I can isolate relevant scientific problems, tackle them systematically by using my extensive training as a psychologist, and then come up with novel theories and visions to solve them. Then I integrate theories and technologies into working prototypes and innovative systems, and verify their validity with rigorous user testing, be it with ethnographic methodologies or in experimental lab settings. As a leader, I am able to assemble a team of world-class experts, lead and advise them on all research and engineering levels. I have a knack to inspire and enable team members, bringing out the best in them, and at the same time keeping strategic requirements in mind. So far I have supervised organizations with up to nearly 60 people, but I am very comfortable creating high impact systems and prototypes with smaller teams as well. Academics I have earned three degrees: both Master's and PhD in Media Arts & Sciences from MIT, and an additional Master's in Psychology, Philosophy, Computer Science (University of Bern, Switzerland). I have received my PhD in Media Arts & Sciences from MIT in June 2005. During my studies, I worked as an HCI research assistant at the Media Lab at MIT. I was part of the Speech + Mobility Group (then called "Speech Interface Group"), headed by Chris Schmandt, where we worked on speech interfaces and mobile communication devices. Although in a user interface group, my personal approach includes software and robotic agents to enhance those interfaces. My PhD work (as well as my Master's thesis) illustrate that, and my qualifying exams domain reflect these ideas as well. Portfolio My representative industry projects have been focusing on a wide range of domains, from user interface innovation (Samsung) to mobile device interaction (at Samsung and Palm) to AR/VR/XR (at Palm and Harman) to smart audio, to AI/ML, to autonomous driving, to automotive interfaces, to neural and brain interfaces (all at Harman) and many more. But in a wider sense, many of my works hinge around the idea of Human Augmentation (as described above). I have the mind of an engineer (have always had), but in the last 15 years, I was fortunate enough to direct teams and larger orgs which allowed me to execute projects on a larger scale and faster time frame, focusing on R&D and Innovation management. My representative MIT projects—mainly my doctoral work—focus on adding human-style social intelligence to mobile communication agents that are embodied both in the robotic and software domain. My past projects are diverse, and include projects such as autonomously levitating devices (yep, that's what they were called 40 years ago before drones became all the rage in the last decade). Some of these past projects, particularly before I attended MIT, are not in the engineering domain at all, but in social sciences, and often in the psychology and philosophy realm (where I have deep expertise as well). In an earlier life, I was even working in an entirely different domain (audio and video engineering), but here I want to focus on my most recent professional life. Typical Modus Operandi at recent positions I held Commonly, one can summarize their professional life with a CV or a Resume, or work samples like below. However, an alternative and more concise way of describing what I can do and how I contribute to the companies I work for would be as follows:
Leadership |
|  When I started working for HARMAN in 2012, it was already a long established company, founded in 1980. It went through some serious issues until Dinesh became CEO, who then hired IP Park in the CTO role, who in turn hired me. In 2017, HARMAN was bought by Samsung and became the fourth business unit of Samsung. Interestingly, for me this was a return to Samsung, since I already worked for Samsung from 2005-2010
When I started working for HARMAN in 2012, it was already a long established company, founded in 1980. It went through some serious issues until Dinesh became CEO, who then hired IP Park in the CTO role, who in turn hired me. In 2017, HARMAN was bought by Samsung and became the fourth business unit of Samsung. Interestingly, for me this was a return to Samsung, since I already worked for Samsung from 2005-2010
Vice President, Future Experience and AI | (part of HARMAN X, and reporting directly to the HARMAN CTO) I had a dual leadership role: first, I set up and led the Future Experience (FX) and the Corporate AI teams. The FX team, set up in 2012, did top-down vision driven research and engineering on systems with futuristic and advanced UX. I hired and inspired the team members, set up the group's projects, created concept videos, executed on proof-of-concept prototypes, iterated towards productization, patented all important IP, and interfaced with other R&D groups and the technology strategy teams at HARMAN. The Future Experience team's charter was to come up with systems that create and showcase new user experiences that span all business groups of HARMAN and beyond, exploring synergies, adjacencies, and new areas. Its sister group was the Corporate AI team: I initiated this team in 2018 and grew it quickly to 50 people. It was set up as an AI execution group, working on machine learning and deep learning projects which impacted all of HARMAN. My second leadership role was in advancing all things related to User Experience at HARMAN. In this role, I influenced roadmaps and R&D across all of HARMAN, from the automotive to consumer to professional divisions. I was in close contact with all HCI related teams at HARMAN, and worked on "future proofing" all products' UX. My achievements at HARMAN include:
Year: 2012 - 2020 Status: concluded Domain: engineering, management Type: research group, executive function Position: vice president Key team members USA:
Key team members Russia (leadership):
|  Palm was bought by HP in July 2010. In 2012, HP decided to stop producing hardware, but kept the OS called webOS. It was later sold to LG and got a successful second life as OS for TVs, watches, projectors, fridges, etc.
Palm was bought by HP in July 2010. In 2012, HP decided to stop producing hardware, but kept the OS called webOS. It was later sold to LG and got a successful second life as OS for TVs, watches, projectors, fridges, etc.
Director, Future Concepts and Prototyping | (part of the HI team in the webOS/Palm business unit of HP) I founded the team in January 2011. My focus was on leading and inspiring the team members, directing the group's research agenda, hiring new members, interfacing with external groups, and patenting. The team's charter was to do risky and holistic HCI research and end-to-end prototyping (spanning software and hardware) that pushes the edges of HCI. Our projects targeted future product releases, approximately 3-5 years from the current releases. This incredibly talented team consisted of Ph.D. level researchers with diverse backgrounds, from 3D virtual environments to robotics to architecture to speech interfaces. Each of them continued their career and had significant impact on the industry and our lives. I did lead two other teams at Palm: about 15 designers and coders who did UI development and software UI prototyping. Within Palm and HP, I worked with engineers (software and hardware), designers, researchers (e.g., HP Labs), and planners (roadmapping and strategic planning). My team's output consisted of working prototypes and patents of interaction methods that served as ground work for future releases. Our patenting efforts were significant, about one invention disclosure per week. My achievements at HP/Palm include:
Year: 2011 - 2012 Status: concluded Domain: engineering, management Type: research group Position: director Team members: Seung Wook Kim, Davide Di Censo
|
Project Lead and Team Lead, HCI Research Team | (part of the Computer Science Lab at Samsung R&D) I founded the team in 2008, and led it until my departure from Samsung at the end of 2010. The team size was between 3 and 5 members, with the staff researchers holding doctoral degrees in various fields, and interns from first tier universities. I was tasked to initiate and execute strategic HCI projects, both in collaboration with other Samsung groups and external groups. My duties included leading and inspiring the team members, setting the team's direction, creating strategic and feasible project plans, keeping the projects on track, hiring, and patenting. Our main accomplishments were working prototypes (see some projects below), evangelizing these prototypes to Samsung executives (up to chairman, CEO, and CTO), patenting core technologies, and technical reports of our research. My achievements at Samsung include:
Year: 2005 - 2010 Status: concluded Domain: engineering, management Type: research group Position: project and group leader Team members: Seung Wook Kim, Ph.D. (2008-2010), Francisco Imai, Ph.D. (2008-2009), Anton Treskunov, Ph.D. (2009-2010), Han Joo Chae (intern 2009), Nachiket Gokhale (intern 2010) Representative industry projects
|  Video of in-car Cognitive Sensing Technology
Video of in-car Cognitive Sensing Technology Data collection rig
Data collection rig HARMAN DMS product
HARMAN DMS product Overview slide
Overview slideClick on any thumbnail for more details!
Cognitive Sensing Systems (HARMAN) | Cognitive Sensing Systems do real-time non-invasive sensing of the brain�s cognitive load, stress, and emotional states by analyzing eye motions, facial & voice cues, and low-level physiological signals. Application areas include automotive safety, semi-autonomous driving, advertising, gaming, AR/VR/XR, and many more. My team's deep driver understanding technologies, developed over several years, are used for HARMAN's DMS products, which can make a vehicle adapt to the specific state of the driver, e.g., during autonomous vehicle hand-off events, to dynamically adjust ADAS parameters (such as increase warning times), to adapt and personalize the vehicle UI/HMI, etc. My team also developed the core DMS system for the HARMAN Aftermarket DMS products. This is one of the larger programs I have initiated and executed at HARMAN. My teams, both the FX group in California and the AI team in Nizhny Novgorod in Russia, have developed many prototypes and modules in multiple iterations. For our earliest systems named DriveSense, we worked with startup EyeTracking Inc. on pupillometry based prototypes, and HARMAN announced the effort in 2016 (and the awards we won), teased it, and we demoed it at CES 2016. This and more advanced systems, Neurosense, were shown at following CES shows and many OEM Tech Days, and created lots of media attention (e.g., the Discovery Channel did a nice piece). Complementing these previous efforts, my AI team started developing novel (industry-first) ML based DMS methods. By the end of 2019, working systems that measure cognitive load and stress from eye motion and heart rate data were successfully put in test vehicles and demonstrated to C-level executives. In parallel, we were building systems that combine cognitive load and emotional load (from face and voice cues) to sophisticated signals like driver readiness, and were planning large scale validation studies with external partners on all our new algorithms and methods. I want to add that this program had significant impact on HARMAN. Young Sohn, President and Chief Strategy Officer of Samsung Electronics, saw our Neurosense demo at McKinsey�s T-30 Silicon Valley CEO meeting in June 2016, and told my team and the HARMAN CTO that they should "connect with Samsung's automotive people". Five months later, Samsung (under the leadership of Young Sohn) announced the acquisition of HARMAN for $8 Billion. I claim we had something to do with that! Years: 2015 - 2020 Status: ongoing Domain: engineering Type: full range R&D effort from early PoC to near product-level systems; many patents; multiple concept videos; various demonstrators (software and hardware); systems shown at OEM Technology Days, Auto Shows (e.g., Geneva), and Consumer Shows (e.g., CES), invited paper My position: project and team leadCollaborators: all FX and AI team members
|  Concept Video 2016
Concept Video 2016 Shape-shifting controller (SSC) v1
Shape-shifting controller (SSC) v1 UX demo of SSCv1
UX demo of SSCv1 Design of SSCv2
Design of SSCv2 Mechanics of SSCv2
Mechanics of SSCv2 UX demo of SSCv2
UX demo of SSCv2
Shape-Shifting Interfaces, part I (HARMAN) | Shape-Shifting Interfaces robotically change their shapes, surface textures, and rigidity to communicate with users on a semi-conscious and subtle level. Such systems use the human proprioceptive sense, not competing with vision and hearing, thus enabling "load-balancing" of the human senses. Primarily used for automotive interfaces in standard and semi-autonomous vehicles, our effort was announced by HARMAN, and our systems are currently being evaluated by a leading German OEM for productization. Shape-Shifting Interfaces is a large-scale long-term effort which has delivered many systems and prototypes. Our Shape-Shifting Rotary Controllers (SSC) are amazing pieces of technology, and create a low distraction, yet super obvious user experience, such as controlling infotainment systems eyes-free. (The videos on the left show the user experience.) We refined these controllers to near product level. The HARMAN Fact Sheet describes the product reasonably well. All shape-shifting interfaces create a never seen before and highly futuristic UX for vehicles of all kinds, including eVTOLs, space crafts, and beyond. As an experience, it is unlike anything else consumers have experienced before, be it in the automotive domain or anywhere else. We were planning user studies to verify our assumption that such interfaces do not add to the information overload, and are largely processed in parallel to all other human senses. Year: 2016 - 2020 Status: ongoing Domain: engineering Type: full range research and development from early PoC to near product-level systems, many patents, multiple concept videos, various demonstrators, presented at OEM Technology Days (e.g., for Toyota, Alfa Romeo, JLR, Volvo, Renault, VW, GM, BMW), Auto Shows (e.g., Shanghai Auto Show, Geneva Motor Show), Consumer Shows (e.g., CES Las Vegas) My position: project and team leadCollaborators: all FX team members
|  Steering Wheel Prototype
Steering Wheel Prototype Making of SSSW
Making of SSSW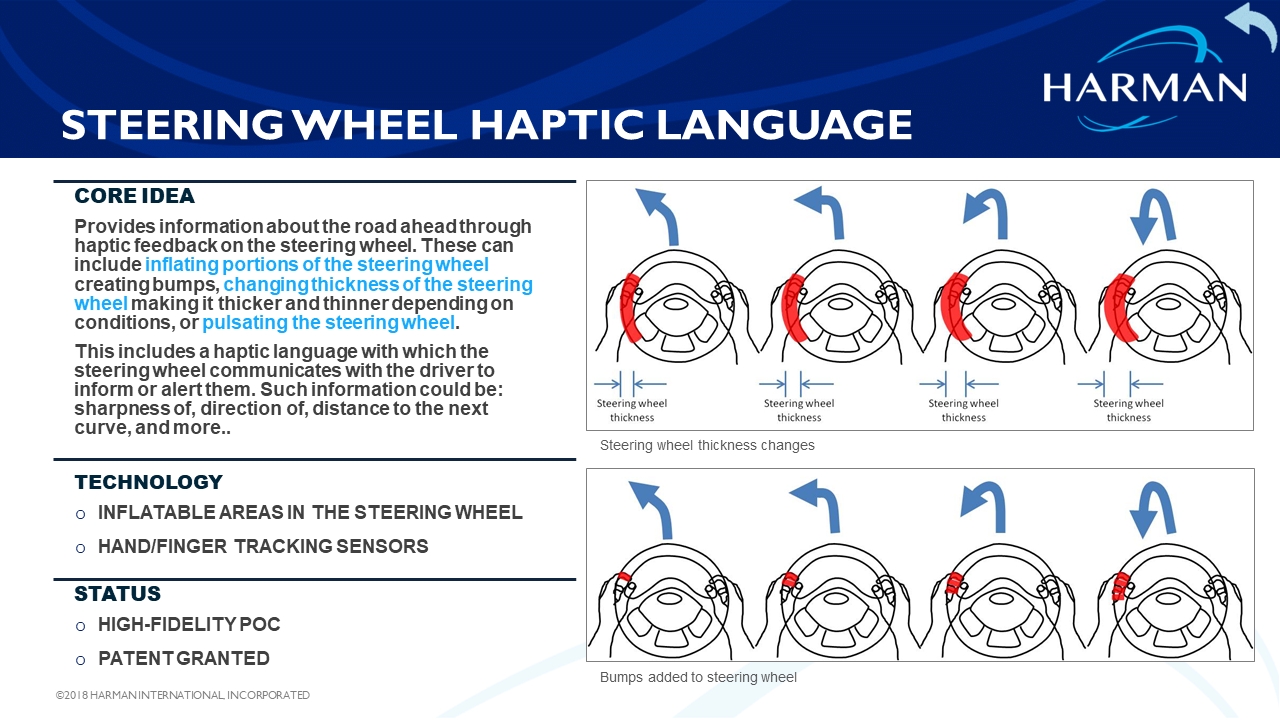 Haptic Language
Haptic Language Steering Wheel Cover
Steering Wheel Cover Shape-Shifting Surfaces Prototypes
Shape-Shifting Surfaces Prototypes Early Prototyping
Early Prototyping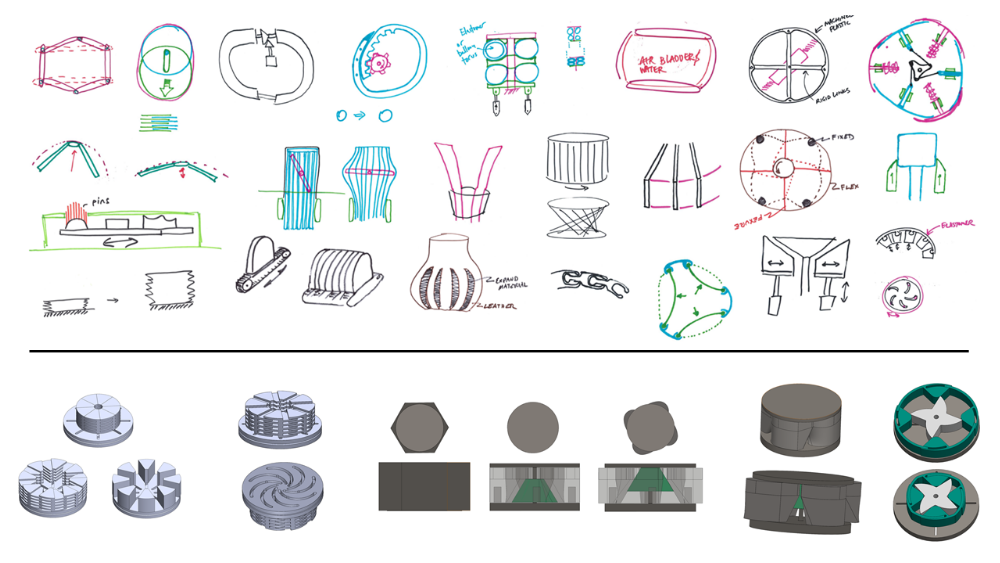 Design Iterations
Design Iterations
Shape-Shifting Interfaces, part II (HARMAN) | The concept of Shape-Shifting can be applied to other automotive interfaces: in particular, to the steering wheel, and to the arm and hand rest. Our Shape-Shifting Steering Wheel (SSSW) is one of the most intuitive demonstrators I have ever built. It is a no-brainer as a product, either fully integrated into a steering wheel (and offered to an OEM), or as a steering wheel cover (to be sold as aftermarket solution to end consumers). The idea of a shape-shifting steering wheel is that it changes its thickness underneath the hands of the driver, to subtly give feedback to the driver. The simplest product would be a steering wheel cover that inflates slightly on the right or the left side, telling the driver to turn in that direction. We have built a more sophisticated system where the steering wheel's built-in robotic actuators can slightly lift each finger, separately or the whole hand at the time (see videos on the left). We have developed a whole new language to communicate with the driver, and can use this for many more applications: merger and blind spot alerts, countdown to turns, frontal collision alerts, pedestrian alerts, hidden object alerts, and many more. The HARMAN Fact Sheet has further details. The Shape-Shifting Surfaces apply the concept to hand and arm rests. These efforts are a bit earlier in the productization cycle, but we have already iterated through many solutions (see videos on the left). A primary application area would be a semi-autonomous vehicle where the user is in a �co-driving� situation with the car. In one application example, the user would rest their hand on a robotically improved arm rest. They then would get an almost subconscious understanding of the environment around the vehicle, without having to look at a display. Furthermore, if the user perceives the vehicle to drive too close to another vehicle or the curb, they may push with their hand laterally against the �obstacle�, and therefore move the car away from it—all while leaving the car in autonomous driving mode. This specific use case is a primary concern of users of semi-autonomous vehicles, and was confirmed in a thorough user study my group did with CMU. (Note that their solution to the problem does not use shape-shifting interfaces since we prompted them to find other potential solutions.) Year: 2016 - 2020 Status: ongoing Domain: engineering Type: full range research and development from early PoC to near product-level systems, many patents, multiple concept videos, various demonstrators, presented at OEM Technology Days (e.g., for Toyota, Alfa Romeo, JLR, Volvo, Renault, VW, GM, BMW), Auto Shows (e.g., Shanghai Auto Show, Geneva Motor Show), Consumer Shows (e.g., CES Las Vegas) My position: project and team leadCollaborators: all FX team members
|  AAR concept video
AAR concept video AAR MVP headphones
AAR MVP headphones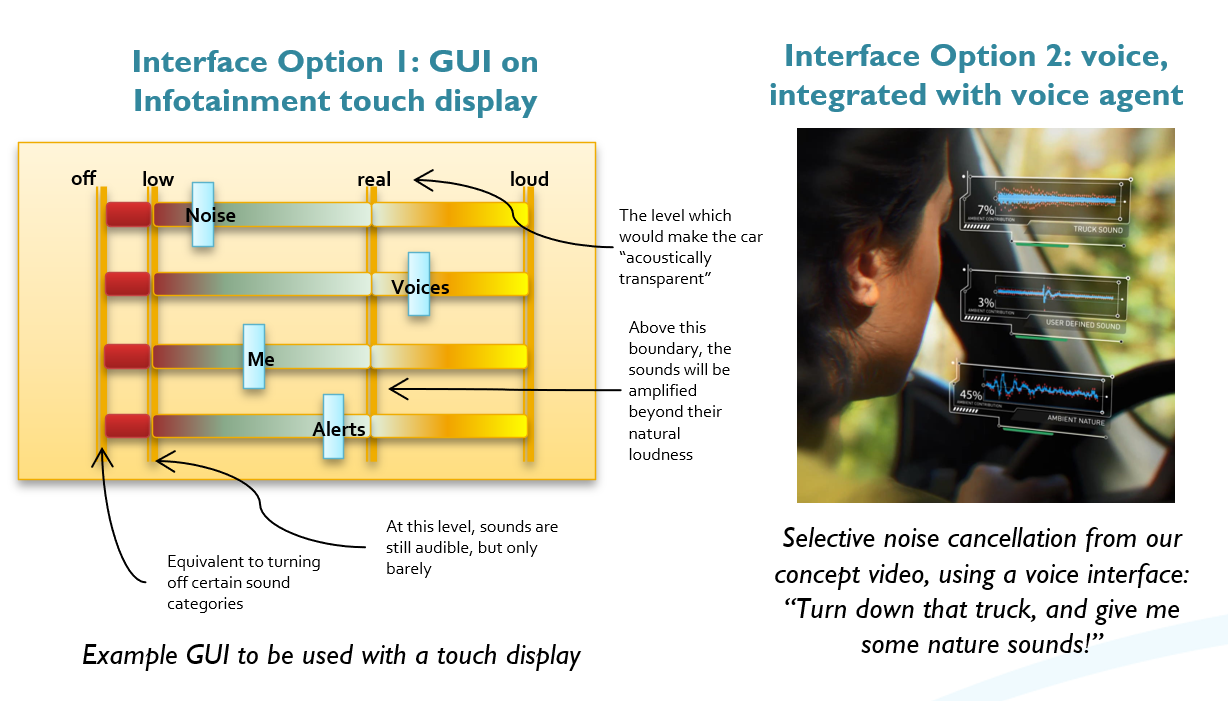 AAR UIs
AAR UIs AAR in cars
AAR in cars Indiegogo video
Indiegogo video
Click on any thumbnail for more details!
Auditory Augmented Reality for Super Human Hearing (HARMAN) | We want control of what we hear. Noise cancellation headphones are ok, but not selective enough. We need a product which not only cancels exactly what we don�t want to hear, but also emphasizes what we like. This leads to a kind of SUPER-HUMAN HEARING. Auditory Augmented Reality, short AAR, allows users to customize their auditory environment: selectively cancel unwanted sounds, increase or decrease the volume of other sounds, or add new sound sources to their sound scape. We apply AAR to products such as headphones, ear buds, Hearables, in-car audio systems, AR/VR/XR gear, etc., redefining what these sound systems can do, beyond listening to music. To explain the idea, we created a concept video for earbuds use, made AAR part of our portfolio video for automotive projects, and a headphones MVP video (the crowd sourcing campaign it was made for did not get corporate approval). Over the years, we created many prototypes and modules that showcase AAR, such as Name-Sensitive Headphones (shown at CES 2016, which got lots of attention), machine learning based modules for Audio Event Classification, Sound and Music Source Separation, UX demonstrators, and many more, all protected by 20+ patents. And our AAR efforts have impacted HARMAN products directly: e.g., JBL headphones and ear buds with Ambient Aware (estimated 5M sold so far) are based on AAR. Beyond HARMAN, I also provided significant thought leadership by coining the term in 2012. Still, AAR is just starting to become a �trend�, e.g., it is featured in Amy Webb�s 2020 Tech Trends Report where she describes now what we have been working on for 8 years already. Years: 2013 - 2020 Status: dormant Domain: engineering Type: PoC of MVP, various ML based modules, concept video for AAR earbuds, concept video for in-cabin AAR, MVP video for AAR headphones, 20 patents My position: project and team leadCollaborators: all FX team and some AI team members
|  Illustration of PFT Method
Illustration of PFT Method Windshield display illustration
Windshield display illustration IC display illustration
IC display illustration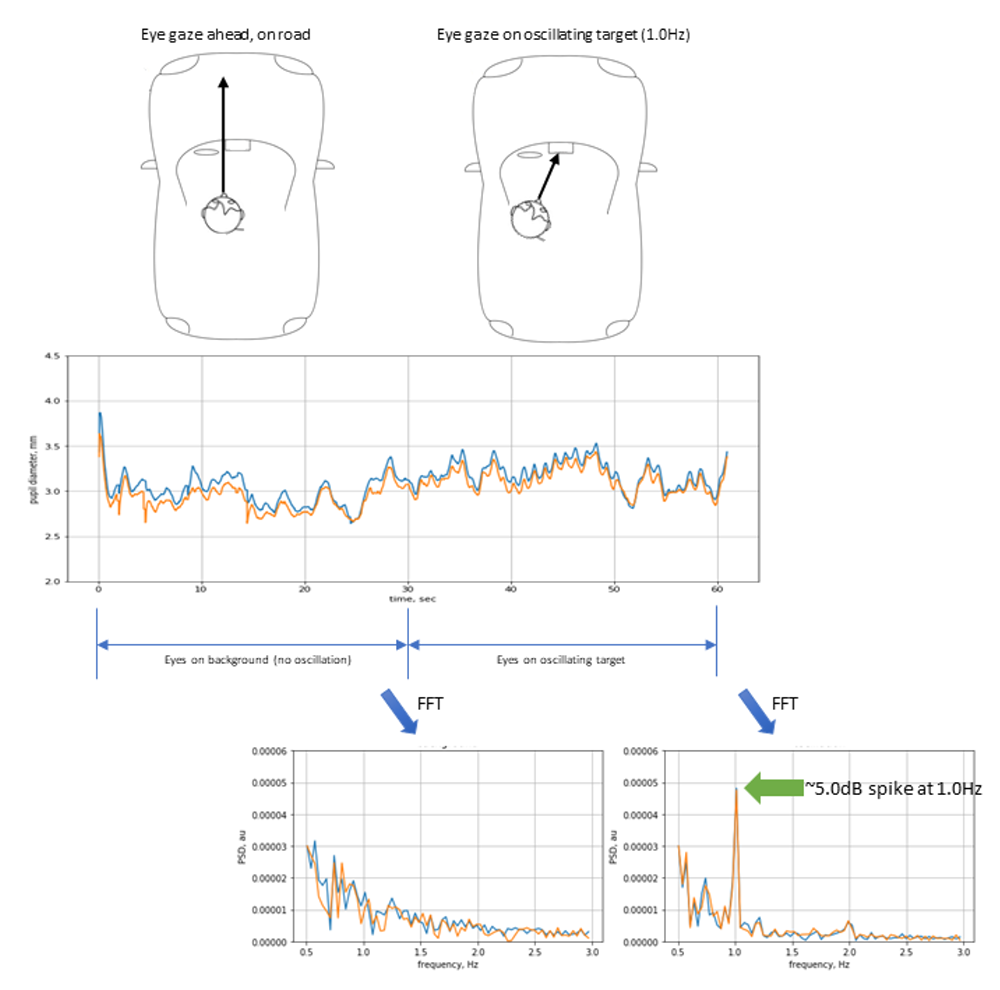 Example data
Example data
True User Attention Sensing (HARMAN) | Today's cars often alert their drivers visually, e.g., a low tire pressure indicator lighting up on the dash. However, a car cannot determine if the driver has actually paid attention to such signals. (And no, requiring the driver to acknowledge an alert by pressing a button, like it would be done on cellphones or laptops, is not an option since that would distract a driver from driving. And no, a driver having made eye contact with an indicator does not mean they also paid attention to it.) We built a truly industry-first proof-of-concept prototype which can determine if a driver looked at a specific visual alert (e.g., low gas indicator), but then can also distinguish between the driver simply having glanced at it, vs. having actually noticed it. This project is based on published scientific findings of the Pupil Frequency Tagging effect (not invented by us), which determines a user's true attention to an alert by measuring physiological signals such as pupil fluctuations or brain signals. This method is super exciting because it goes beyond measuring that a user simply looked at an alert (which could relatively easily be done by measuring eye gaze direction), but requires the user to actively pay attention to the alert. Our MVP software module only needs access to a car's DMS camera (which will become mandatory soon anyway) and an interface to the HMI controls. If the car uses warning lights and needs confirmation of the driver's true attention, the system oscillates the warning lights' brightness (separate frequencies for each), and at the same time looks for corresponding pupil oscillations. A more sophisticated product can use a head-up display (HUD), windshield projection, or instrument cluster display (IR, thermal, or night vision) which can �outline� objects ahead such as pedestrians or animals or any road obstacle, and oscillate the outline's brightness subtly. If the driver actually paid attention to the object outlined, the pupils would oscillate with the same frequency as the visual cue. The oscillating cue can even be located in the human peripheral sight and still cause pupil oscillations, as long as the person cognitively paid attention. Our early stage exploratory PoC consists of a software module, a COTS DMS camera, and a mock IC display. In our work, we confirmed experimentally that the PFT effect exists, identified the optimal oscillation frequency, a minimum size for the target, the minimum acquisition time, and the amount of degradation of the PFT effect depending on the peripheral vision angle. Year: 2019 Status: concluded Domain: engineering Type: early PoC, study, report, pending patent application My position: team lead Project lead: Evgeny Burmistrov
|  Automotive system
Automotive system Portable demonstrator
Portable demonstrator Concept video
Concept video Overview slide
Overview slide Audio applications
Audio applications
Mid-Air Haptic Feedback Systems (HARMAN) | This technology, based on an array of ultrasonic transducers, can create a haptic effect at a distance, which is a highly unusual sensation with tremendous product potential in a variety of domains, from automotive to AR/VR/XR to 3D interfaces to wearables to gaming, and many more. This effect, sometimes called "touchless haptics," can be used for many interaction scenarios. One of them is to make in-car gesture interfaces useful so that the driver does not have to check visually if their gesture was successful. My FX team created various prototype systems, the most recent one integrated into our test vehicle. The core technology is by UltraLeap, a startup which we have worked with closely. My team developed the automotive interaction design, and closed the gap between the startup's basic modules and a Tier-1 automotive product. HARMAN announced this collaboration, and shortly after we were in discussions with a dominant German OEM about HARMAN becoming the provider of mid-air haptic automotive systems, integrated with the rest of the infotainment systems. Beyond automotive applications, we also applied mid-air haptics to support gestures with speakers, and showed a system at CES 2016 (with interesting reviews). Years: 2016 - 2018 Status: dormant Domain: engineering Type: full range research and development from early PoC to near product-level systems, many patents, multiple concept videos, various demonstrators (software and hardware), presented at OEM Technology Days (e.g., for Toyota, Alfa Romeo, JLR, Volvo, Renault, VW, GM, BMW), Auto Shows (e.g., Shanghai Auto Show, Geneva Motor Show), Consumer Shows (e.g., CES Las Vegas), invited paper My position: project and team leadCollaborators: all FX team members
|  Google I/O
Google I/O The Verge
The Verge Engineering
Engineering Design and collaboration
Design and collaboration
Gesture Enabled Speaker (Soli) (HARMAN and Google) | The FX team worked extremely closely with the Google Soli team for several months to create a working prototype of a speaker that allowed for interaction via micro and finger gestures. The loudspeaker was shown at Google I/O on May 20th, 2016. HARMAN announced our collaboration a few days earlier. Arguably, HARMAN's stock price reacted quite positively to this collaboration: financial news outlets noted that HAR stock gained 4.81% right after our joint live presentation at Google I/O 2016. This project was a co-development project between HARMAN's FX team, the Soli team at Google�s Advanced Technology and Projects group (ATAP), led by Dr. Ivan Poupyrev, and IXDS who did user research on the project. We integrated the Soli radar based sensing technology in a connected home speaker to enable people to control audio without touching a button, knob, or screen. This collaboration with Google ATAP not only resulted in integrating the high-performance radar-based gesture sensor into a JBL speaker, but also in designing a novel light-feedback based user interface to communicate with the user. We also got two patent grants, for HARMAN and Google-HARMAN joint patents for several aspects of this work, enabling and facilitating productization. Year: 2016 Status: concluded Domain: engineering Type: several demonstrators, video from Google I/O 2016, granted patent (joint with Google), granted design patent My position: team leadProject lead: Joey Verbeke, Davide Di Censo
|  Video of PoC
Video of PoC Eye vergence patent
Eye vergence patent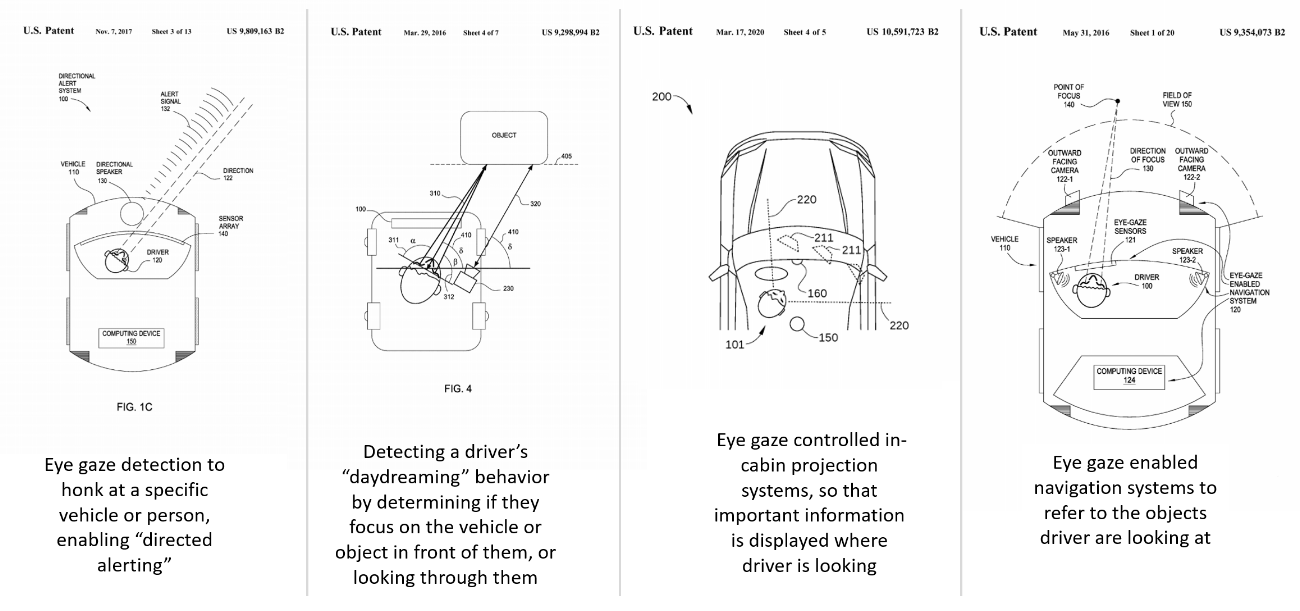 Other Eye gaze patents
Other Eye gaze patentsClick any thumbnail for more details!
Eye Vergence and Gaze Sensing for controlling transparent displays (HARMAN) | In vehicles with head-up displays (HUDs) or windshield projection displays, our system not only measures the driver's eye gaze direction, but also their vergence (eye focus level), allowing the user interface of the car to adapt instantly and context-aware to the driver's needs, without the driver having to do anything specific (or even be aware of the system). The video on the left shows our working system, and how it is used. This was an early prototype, but based on the expertise gained, we kept developing many more systems afterwards. E.g., one of our efforts was detecting a driver's interest in billboards on the road side. Another effort was about using eye gaze to honk at a specific vehicle or person (directed alerting). We also continued using eye gaze and vergence in a multitude of DMS prototypes and efforts that are incorporated in current and upcoming HARMAN products: from detecting a driver's �daydreaming� behavior (by determining if they actually focus on the vehicle or object in front of them, or looking through them); to eye gaze controlled in-cabin projection systems (important information shows up inside the cabin right beside where the driver is currently looking at); to eye gaze enabled navigation systems (system monitors the driver's eye gaze and can refer to the objects they are looking at to give super contexualized navigation guidance). In a very large recent project, we even use eye motion data to calculate a driver's stress and cognitive load. Eye gaze and vergence is also used in many of our AR/VR/XR related systems, e.g., to enable super enhanced conversations across crowded rooms triggered by mutual eye contact. Year: 2013 (this prototype) Status: concluded Domain: engineering Type: demonstrator, video, granted patent (this system) My position: team lead Project lead: Davide Di Censo
|  Early PoCs
Early PoCs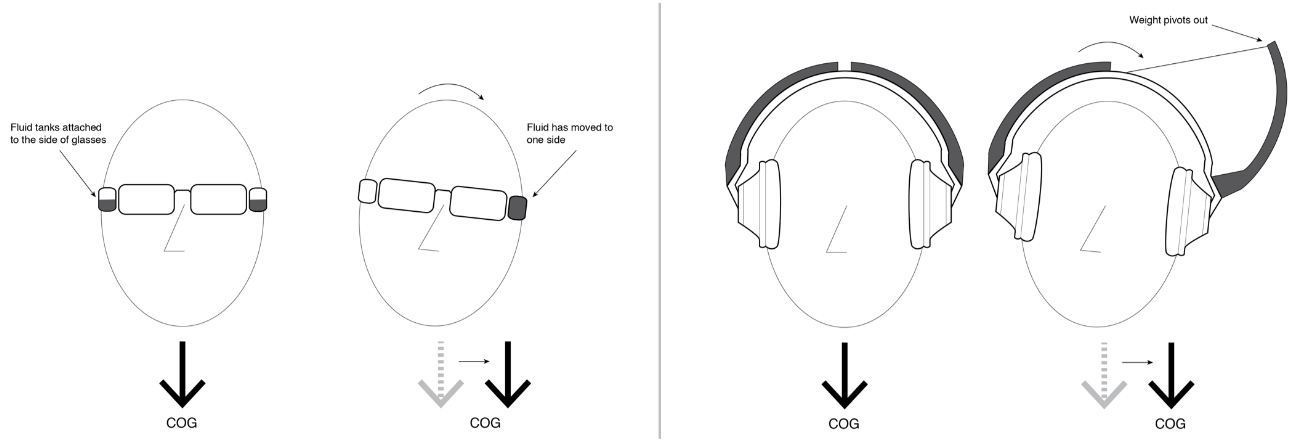 Method A: shifting CoG
Method A: shifting CoG CoG prototype
CoG prototype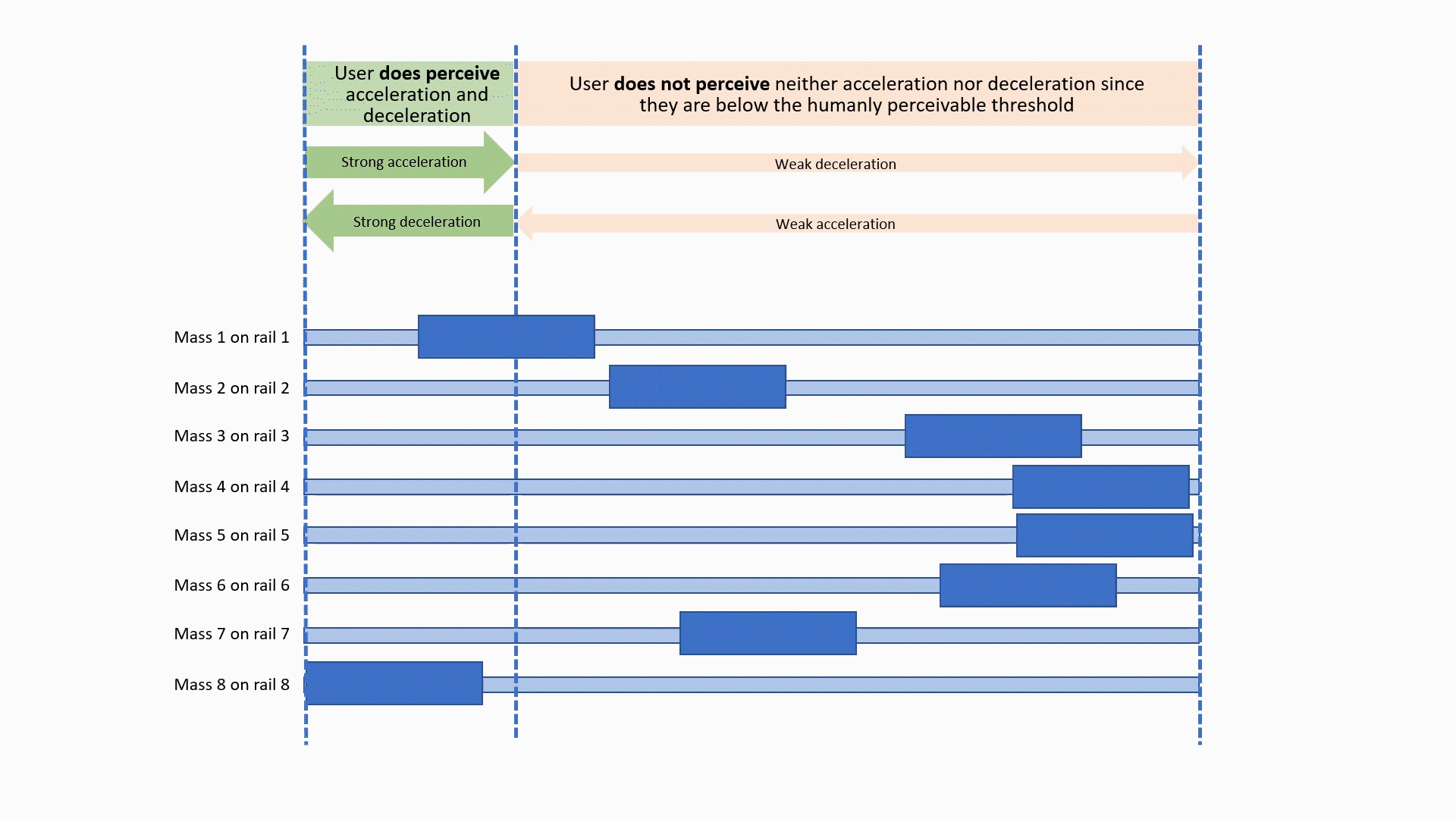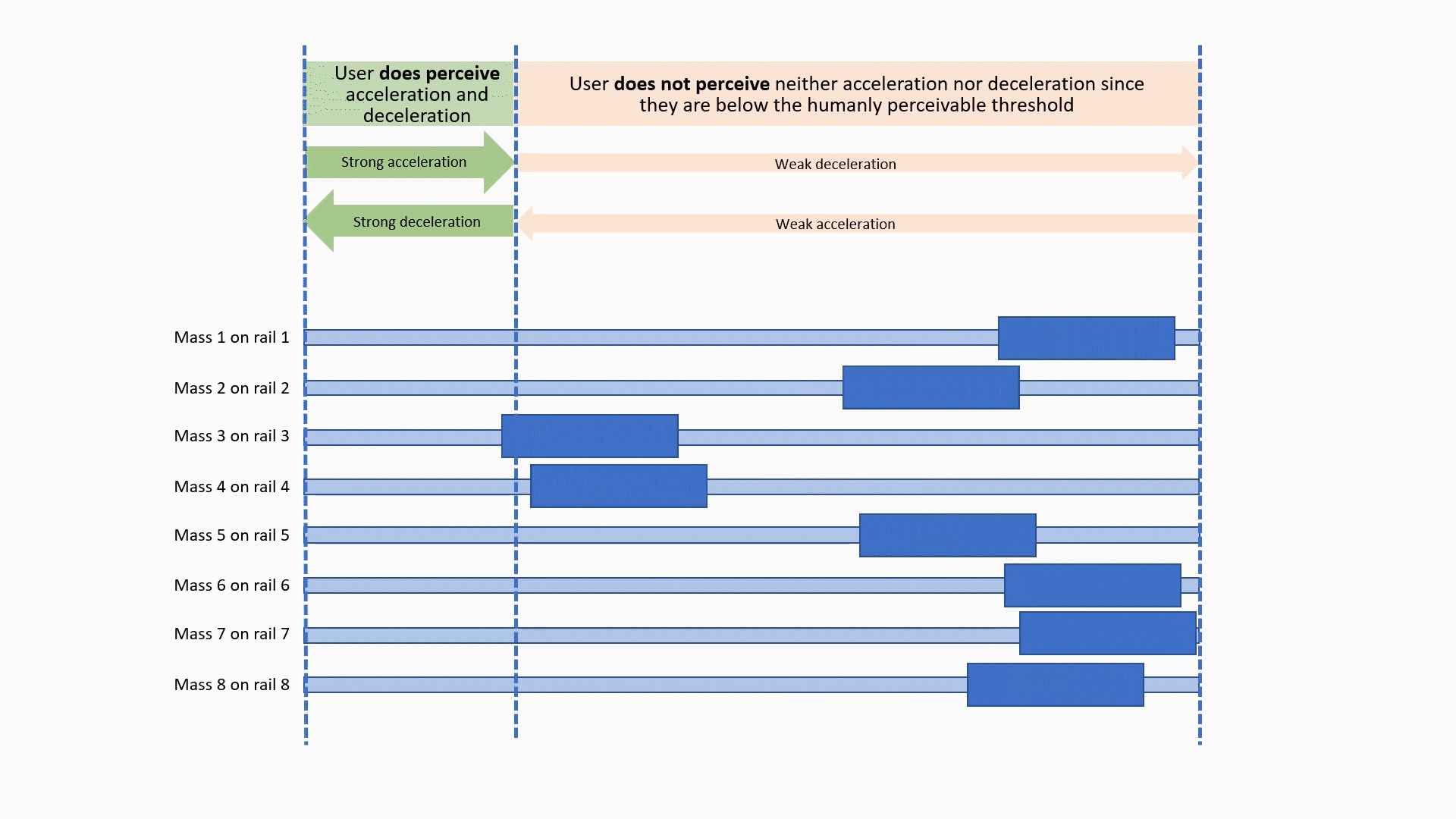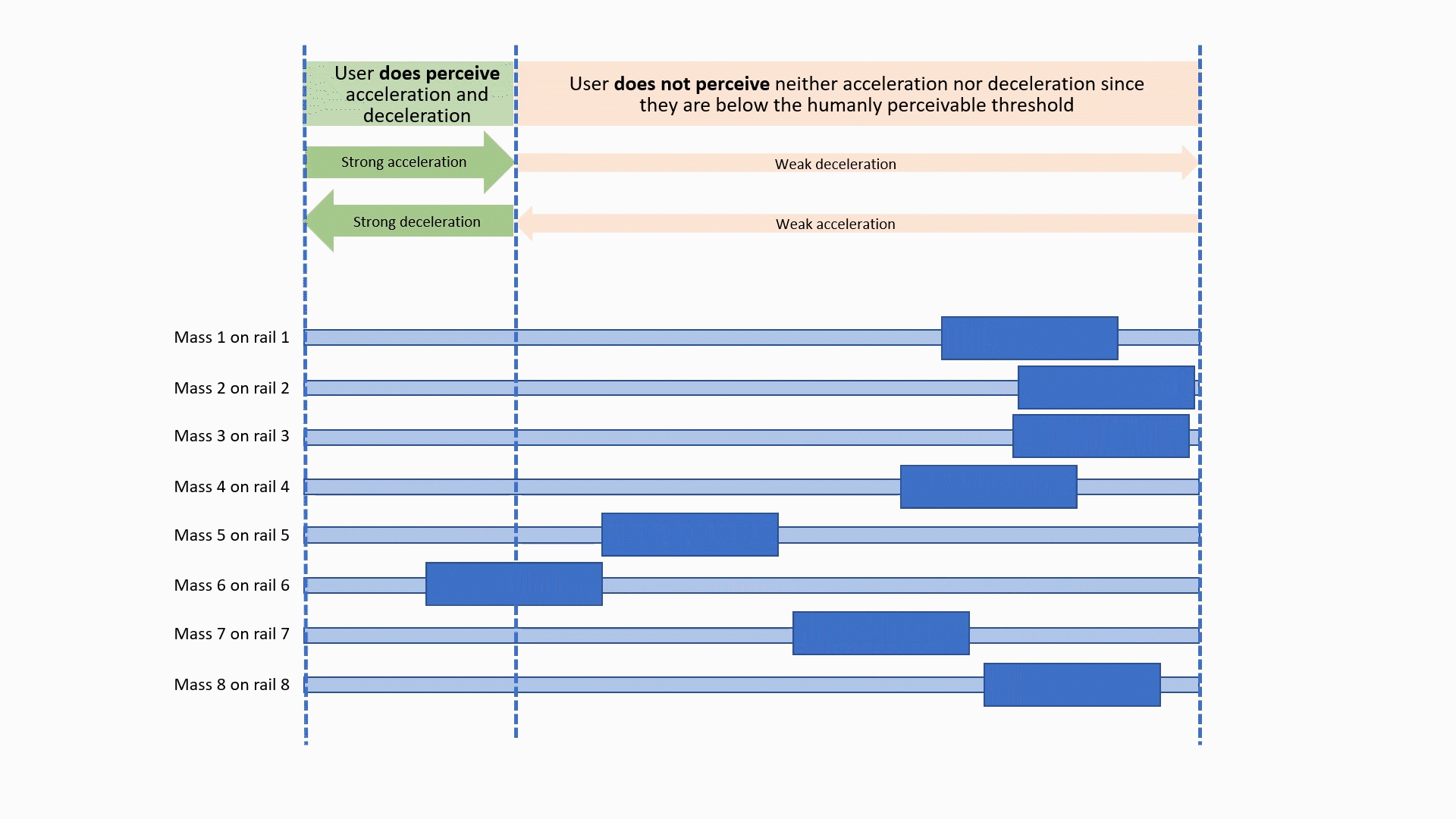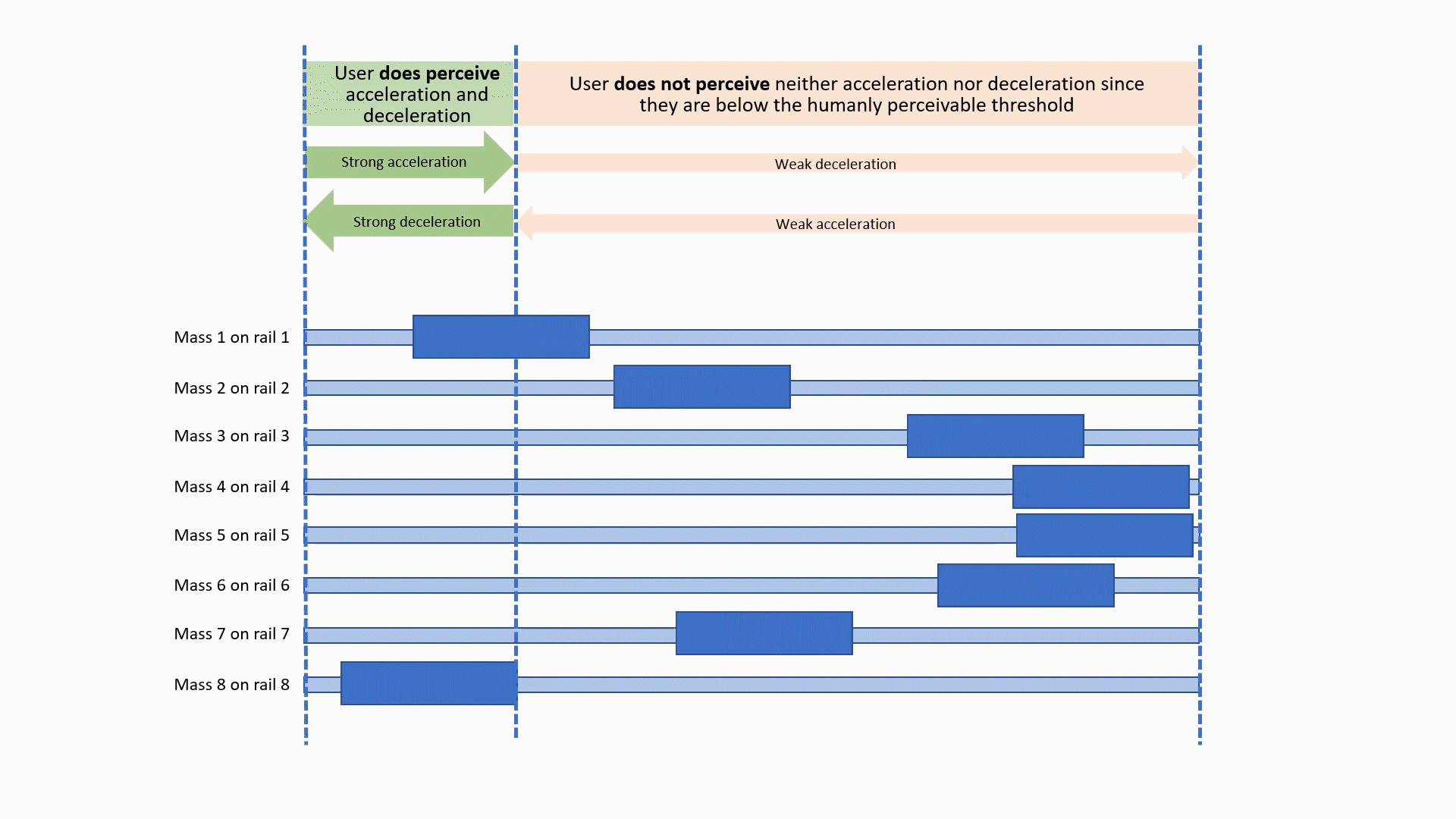 Method B: asymmetric accelerations
Method B: asymmetric accelerations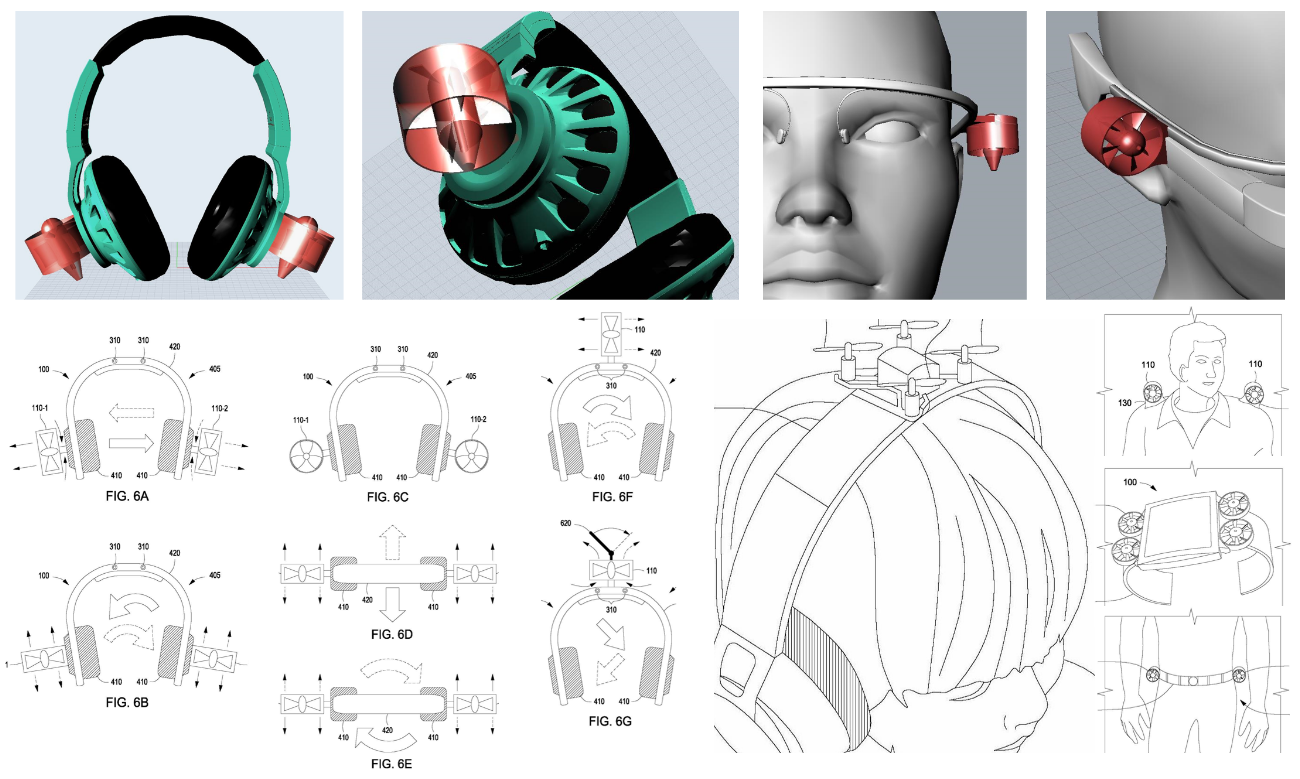 Method C: air flow
Method C: air flow
Nudging Headphones and AR/VR/XR gear (HARMAN) | This effort is about creating PoCs for products that give the user the feeling of being gently �pushed� (or pulled) in a specific direction. This effect can be almost subconscious, and often feels quite unreal. Such gentle "nudging" can be used for headphones, Hearables (aka, smart ear buds), AR/VR/XR gear, and all kinds of wearables. Applications include pedestrian navigation systems, directional warnings and alerting (e.g., used by a VPA), gaming, and many uses for AR/VR/XR. We worked on 3 different methods: Method A: Dynamically change the center of gravity on headphones by shifting weights mechanically or pneumatically to the left, right, or front/back. This method does work, is simple, but is not particularly sophisticated (which should not be a reason against productization, to the contrary!) Method B: Use linear asymmetric acceleration of multiple small masses: this method is non-trivial to explain, so please refer to the illustrations on the left. The effect is amazing, and feels pretty unreal. The mechanical elements needed are not simple, though, and make it likely more expensive as a product. Method C: Use miniaturized fans and jets "mounted" on the user to nudge them in the desired direction. the effect comes from air and gas flow from axial fans and similar propulsion systems such as propellers, ducted fans, micro and MEMS turbines, and micro propulsion systems. For all these methods, we filed patents, and two of them got granted so far. Year: 2016 Status: concluded Domain: engineering Type: multiple early PoC, 3 patents: Fan-Driven Force Device (granted), Center of Gravity Shifting Device (pending), Pseudo Force Device (granted) My position: project and team leadCollaborators: Tanay Choudhar, and all FX team members
|  Video of working PoC
Video of working PoC Brief concept video
Brief concept video Preliminary product sheet
Preliminary product sheet Gestures to move sounds on headphones
Gestures to move sounds on headphones
Bare-Hand Gesture Control of Spatialized Sounds (HARMAN) | We developed multiple proof-of-concept prototypes for products which allow a user to move sounds (or �sound objects�), such as alerts or music, with their bare hands. We applied this interaction method to automotive in-cabin interaction, as well as to headphones, AR/VR gear, and wearables in general. This is a great example for a unified interaction method which allows the same intuitive sound control for when the user is in their car, or is wearing headphones, or is using AR/VR gear, smartphones/tablets, or laptops. Note that the user is moving sounds, not visible objects, so there is no display involved. (Our 3D display and gestures combines them.) Our in-cabin PoC is shown in the video on the left. A preliminary automotive product was called GESS, �Gesture Enabled Sound Space� (early product sheet). Our interaction system complements well HARMAN's Individual Sound Zones product. In parallel to these automotive efforts, we also worked on systems for headphones: our working PoC has a sensor on the headband that tracks the wearer�s hands and gestures. This allows the user to use gestures for typical media control (volume up/down and next song), but more importantly, bare-hand control over the spatial distribution of sound events in their sound scape. Years: 2013 - 2015 Status: concluded Domain: engineering Type: early demonstrators, brief demo video, preliminary product sheet, 2 granted patents: wearables, automotive, invited paper My position: project and team leadCollaborators: Davide Di Censo, Joey Verbeke, Sohan Bangaru (intern)
|  Concept
Concept Video of PoC
Video of PoC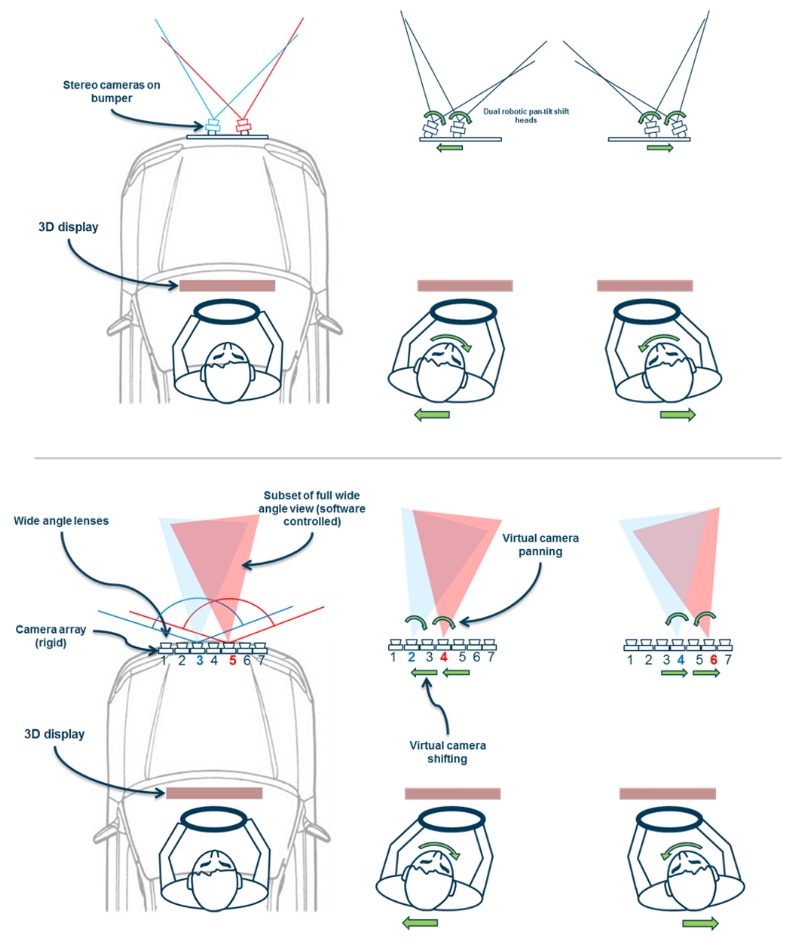 System components
System components
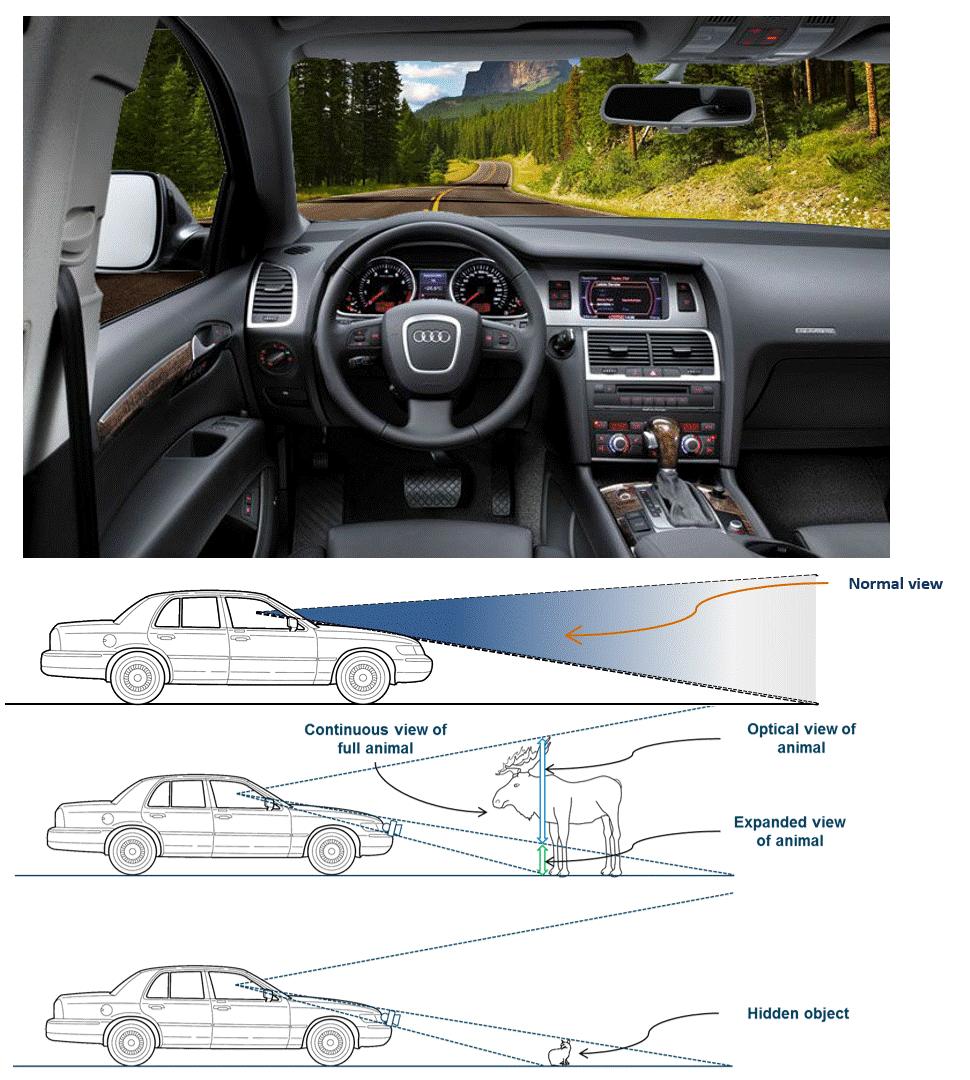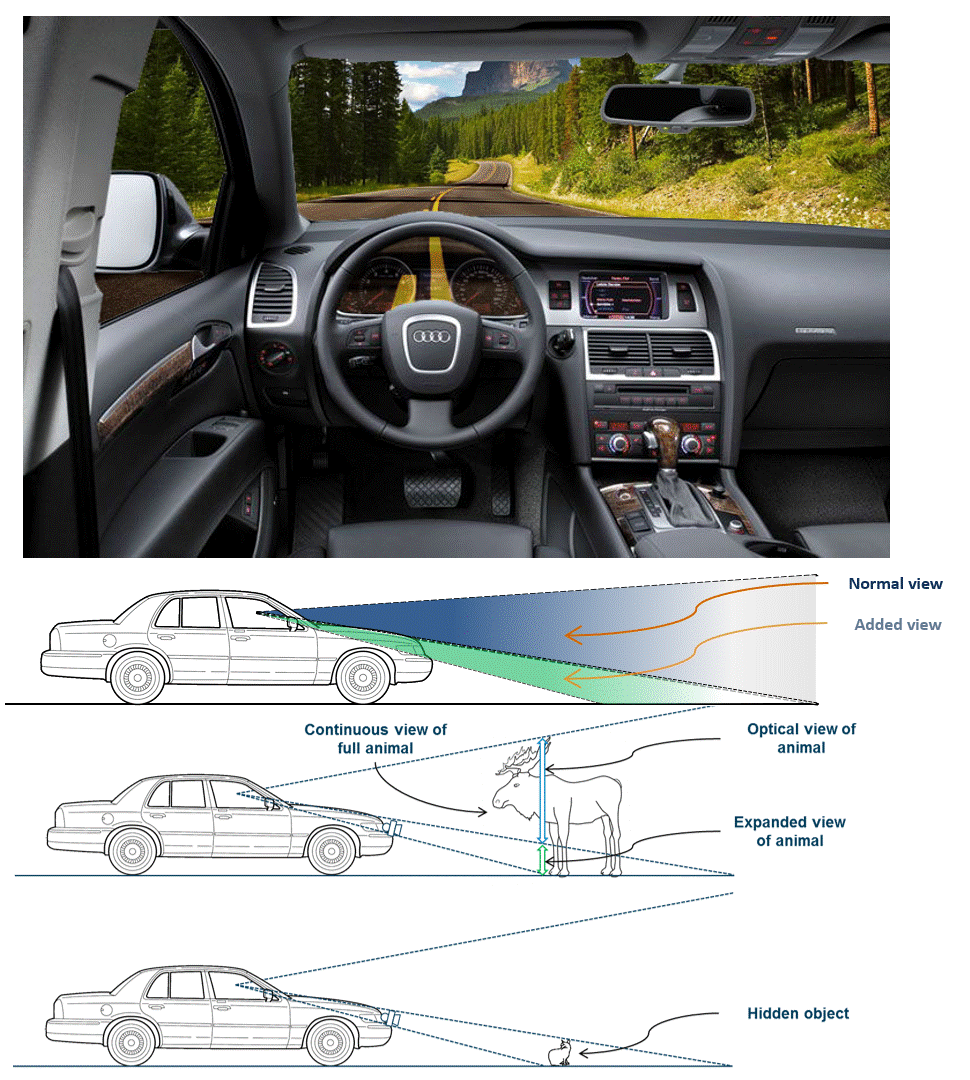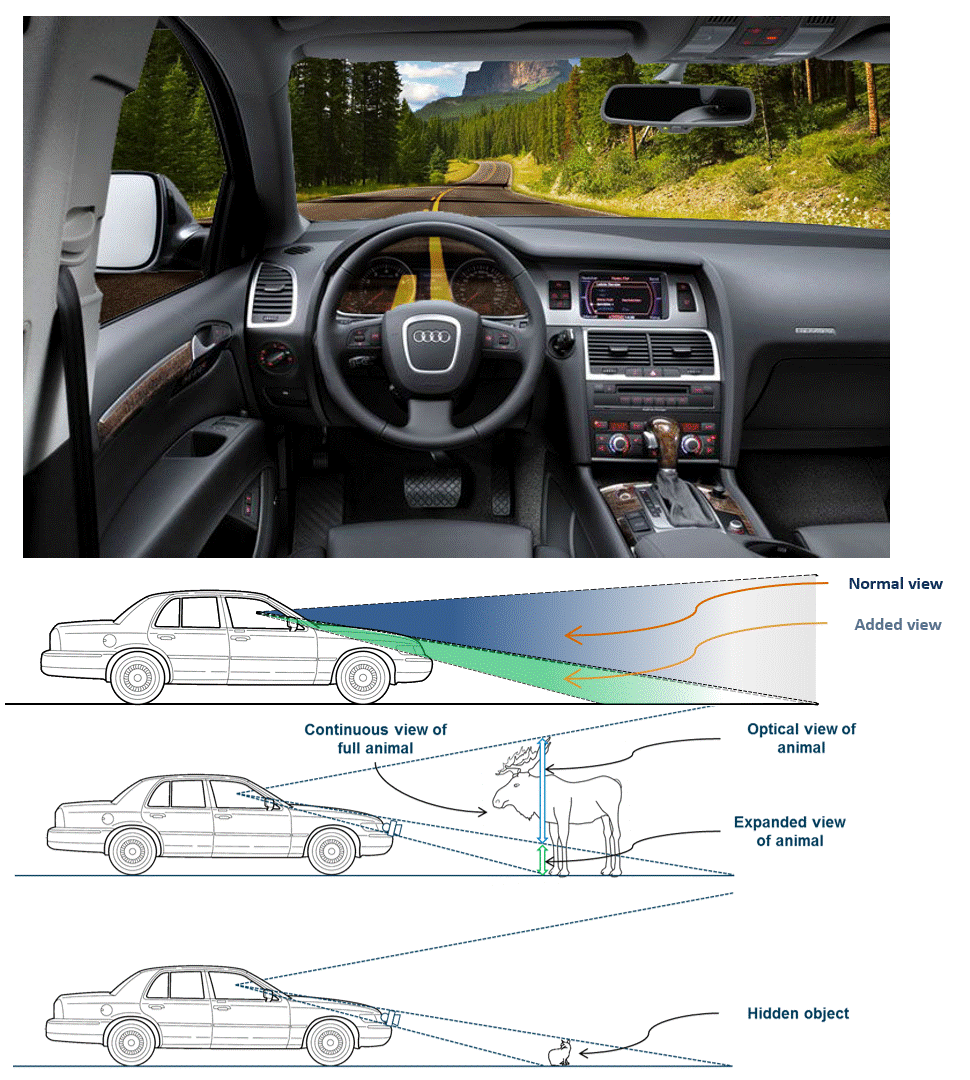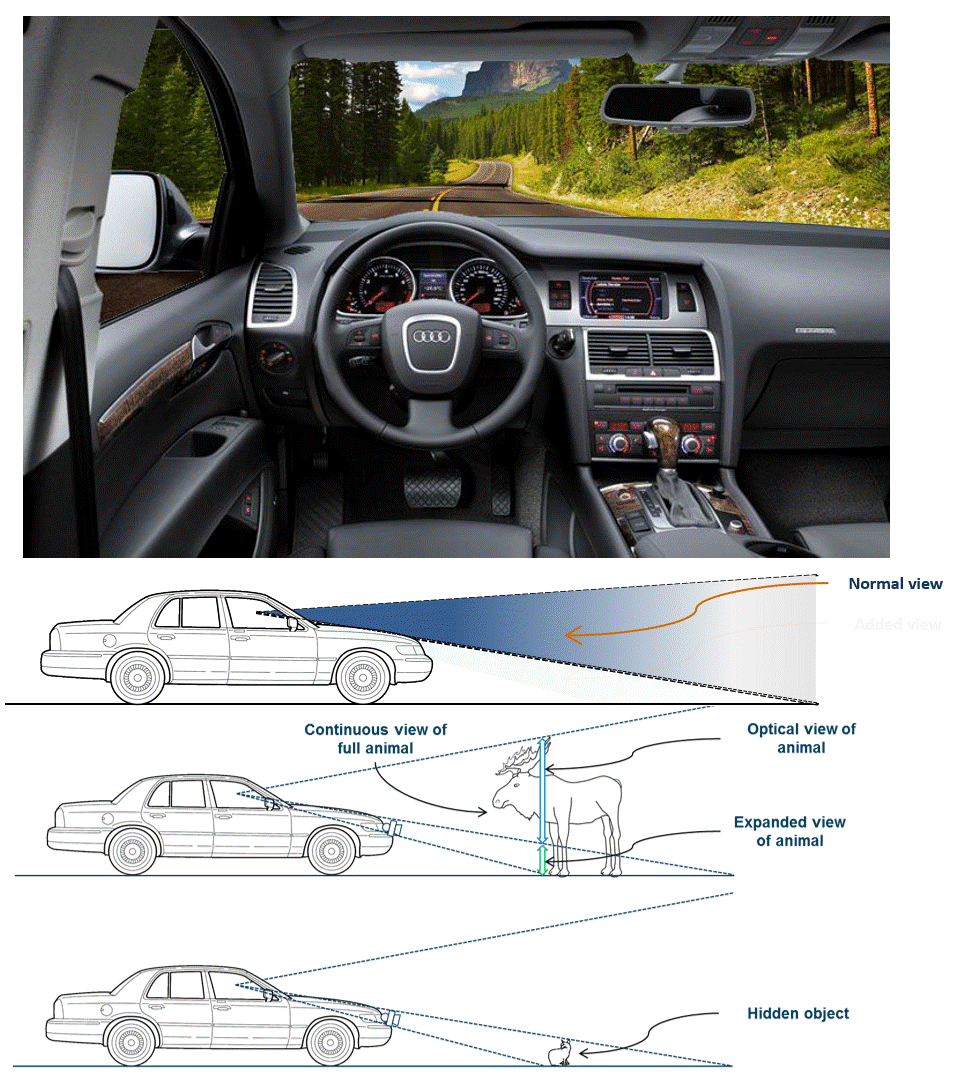
See-Through Dashboard (HARMAN) | The purpose of such a product would be to give a driver a better visual awareness of their vehicle�s environment, in particular close and low. It expands a driver's view through the windshield downwards through the instrument cluster (wider vertical view) using a 3D-capable instrument cluster display and robotically actuated stereo cameras (or a solid state camera array) mounted on the car's bumper. It creates the user experience of a "transparent cockpit," and makes driving and parking safer. We built proof-of-concept prototypes that have mechanically actuated cameras, view dependent rendering, and stereoscopic 3D rendering on zSpace displays. Year: 2014 Status: concluded Domain: engineering Type: PoC demonstrator, demo videos, 2 granted patents: one, two, invited paper My position: team lead Project lead: Davide Di Censo
|  Concept video (2013)
Concept video (2013) PoC using HMD (2017)
PoC using HMD (2017) PoC using HMD (2018)
PoC using HMD (2018) Early PoC of HMI on 3D display (2013)
Early PoC of HMI on 3D display (2013) Overview slide
Overview slide
Pseudo-Holographic Instrument Cluster with Gesture Control (HARMAN) | This project is about the user experience of in-cabin 3D capable displays, combined with gesture control. Such systems can use the space between the steering wheel and driver to dynamically render contextual information. One example is to move important alerts to the focus of the driver (closer to the driver's face) to get her attention. At the beginning was a concept video to show the novel user experience. In multiple engineering iterations, we created working systems, first based on auto-stereoscopic displays, then based on head-mounted AR gear. Our Hololens based working prototypes show the UX of the concept video very well, but we had to adapt the HMD hardware to the moving vehicle situation. The most likely path to productization would be via light-weight AR glasses, either brought-in (as a consumer owned device, like a smartphone), or glasses that are part of the car (tethered, which would make them super light-weight since neither battery nor compute need to be on the glasses, just the light engine). Our sister project Bare-Hand Gesture Control of Spatialized Sounds has more details on the gesture interaction technology. Years: 2013 - 2018 Status: dormant Domain: engineering Type: multiple demonstrators, concept video, multiple demo videos (2013, 2017, 2018), granted patent, invited paper My position: project and team leadCollaborators: Davide Di Censo, Joey Verbeke, as well as interns Brett Leibowitz, Ashkan Moezzi, and Raj Narayanaswamy
|  Video of demo
Video of demo Mockup of interaction
Mockup of interaction Side view
Side view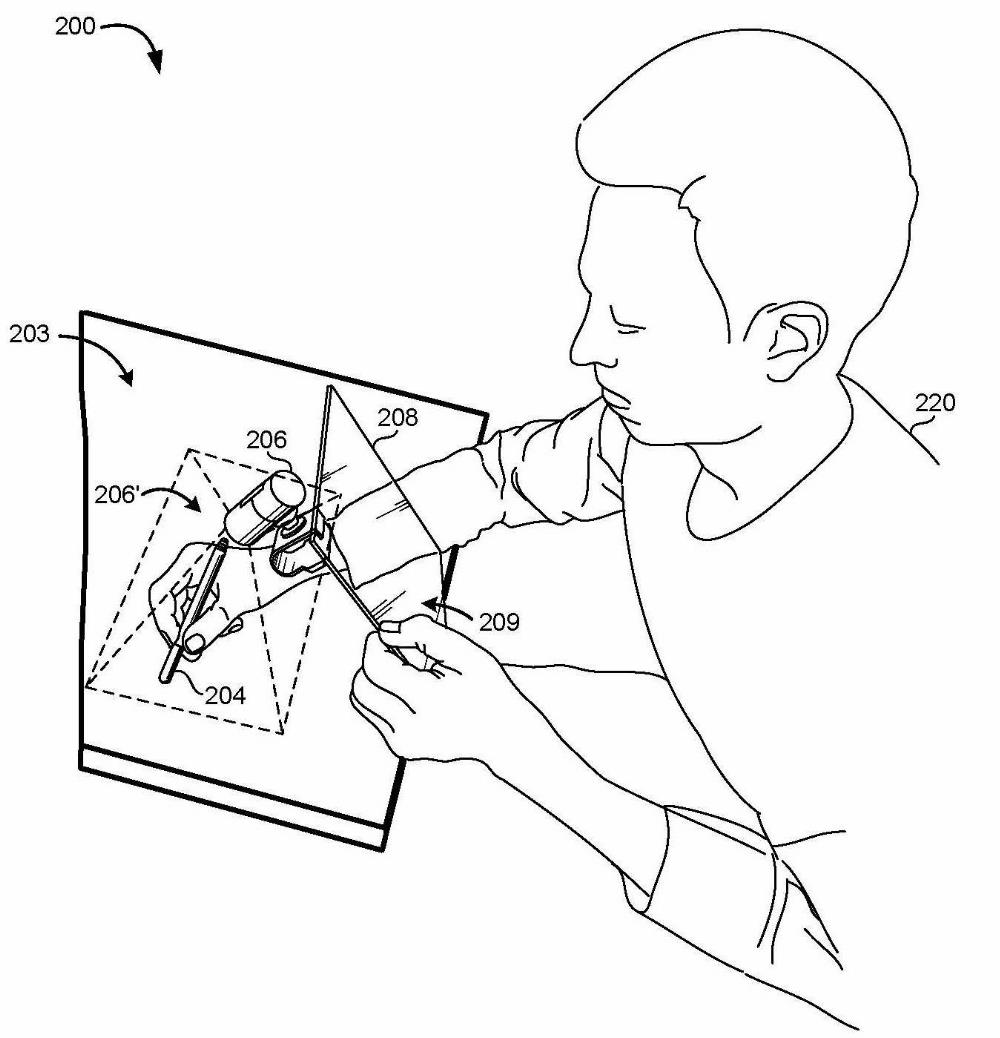 Patent drawing
Patent drawing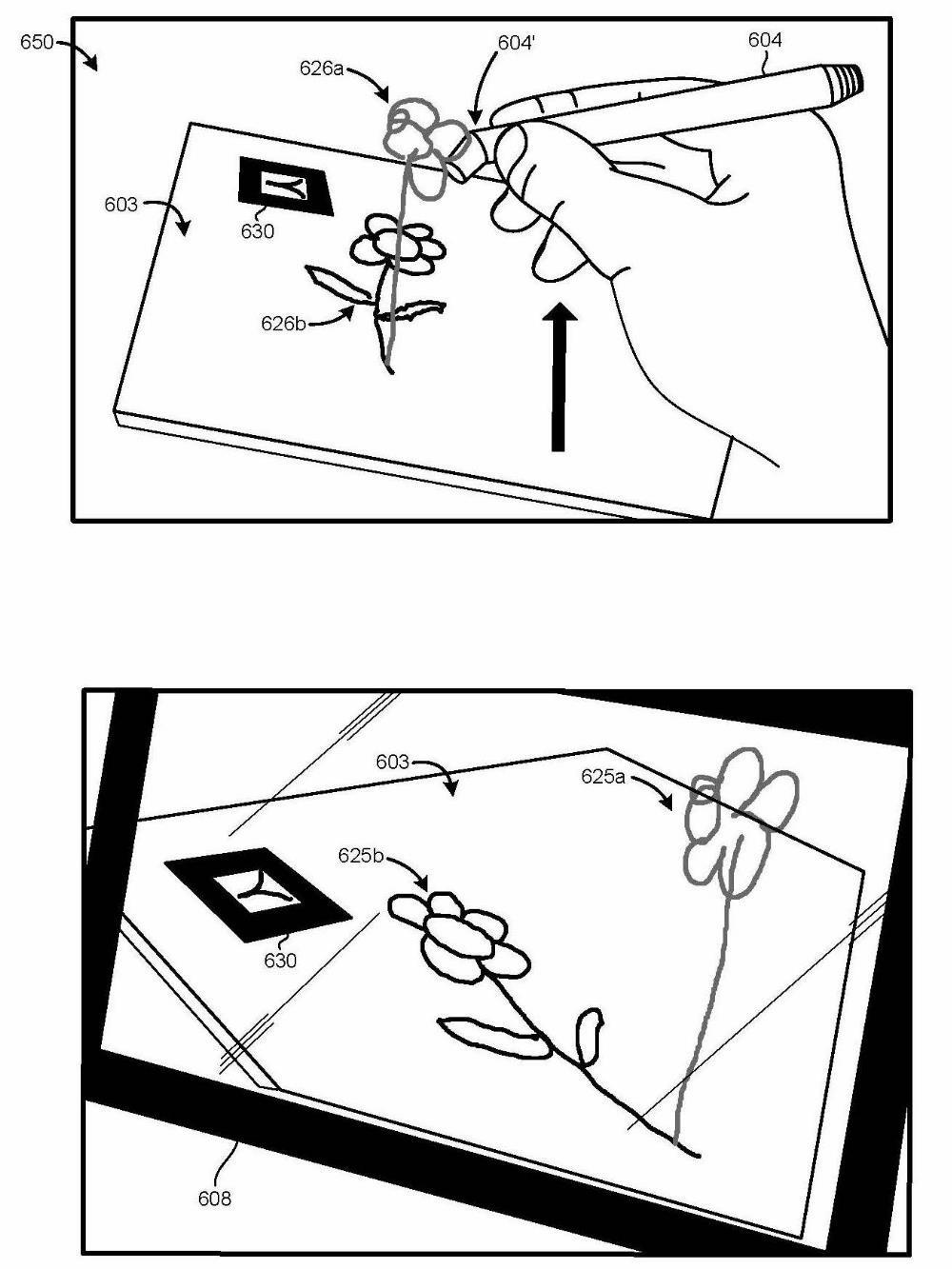 Patent drawing
Patent drawing
3D Pen: augmented reality writing behind tablet (HP/Palm) | Wouldn't it be great to draw and write in mid air? With this project, we explored the interaction design and UX engineering of a pen capable of writing on surfaces and in air, as seen by the user via video see-through device (aka, any tablet these days). This results in a three-dimensionally capable pen, which can create persistent drawings on surfaces and, more importantly, in 3D space. The user (or multiple users) can see these drawings using a tablet or smart phone, using them as a Mobile AR device (MAR). A fiducial marker anchors the virtual rendering in the real world, making is persistent. An additional feature was that the pen could pick up colors before drawing (a feature inspired by I/O Brush). Our prototype, as seen in the video, worked surprisingly well, and the UX was excellent. For our prototype system to work, we did require external sensors (OptiTrack) to track the pen and the tablet. We believe that was an acceptable compromise for an initial prototype. The goal was, though, to replace these external sensors with on-device sensors for a production device. We do have a granted patent on this system: the patent process took 6.5 years, though! Year: 2011 Status: concluded Domain: engineering Type: fully working demo, video of demo, granted patent Position: project and team lead Collaborators: Davide Di Censo, Seung Wook Kim
|  Video of demo
Video of demo Visualization video
Visualization video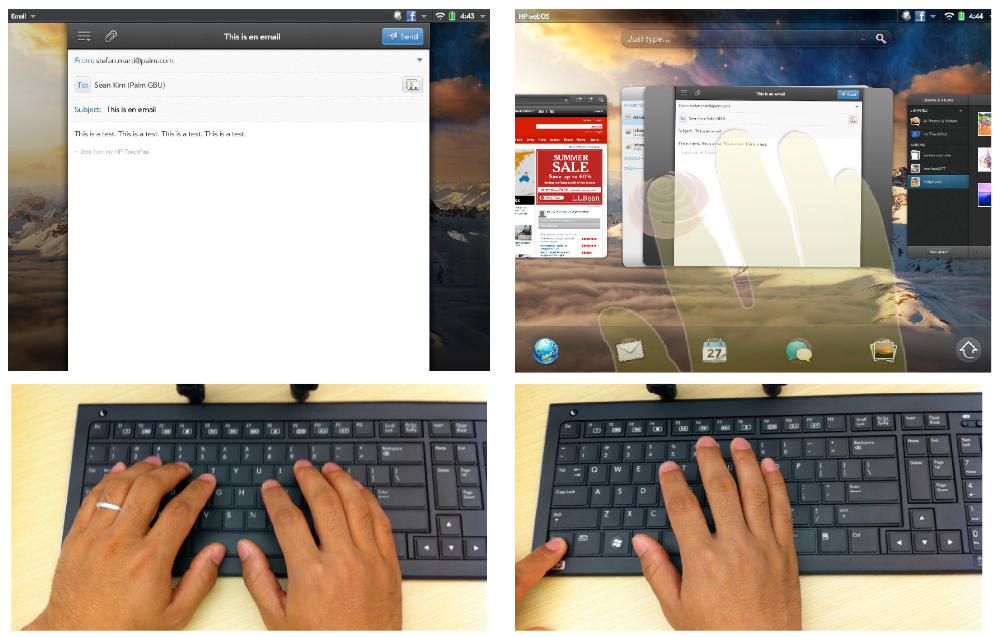 Typical use case
Typical use case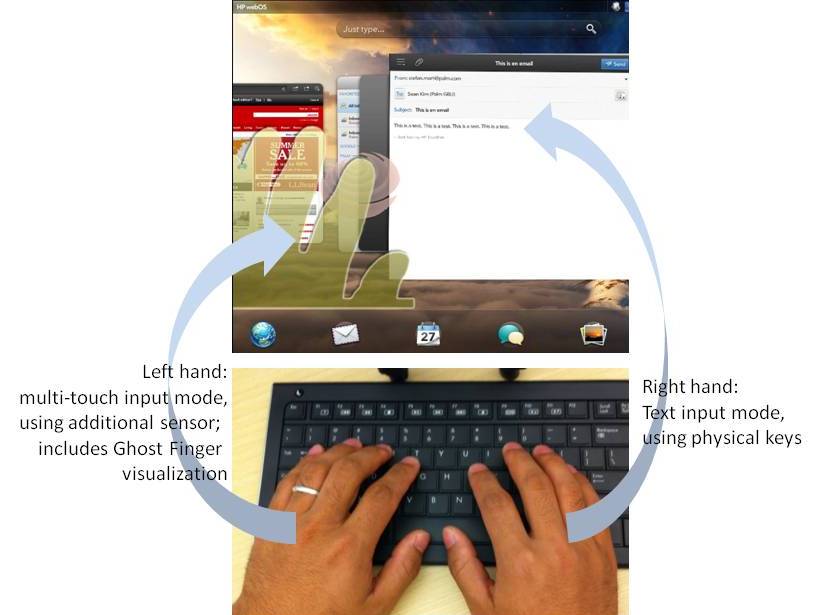 Bi-manual use case
Bi-manual use case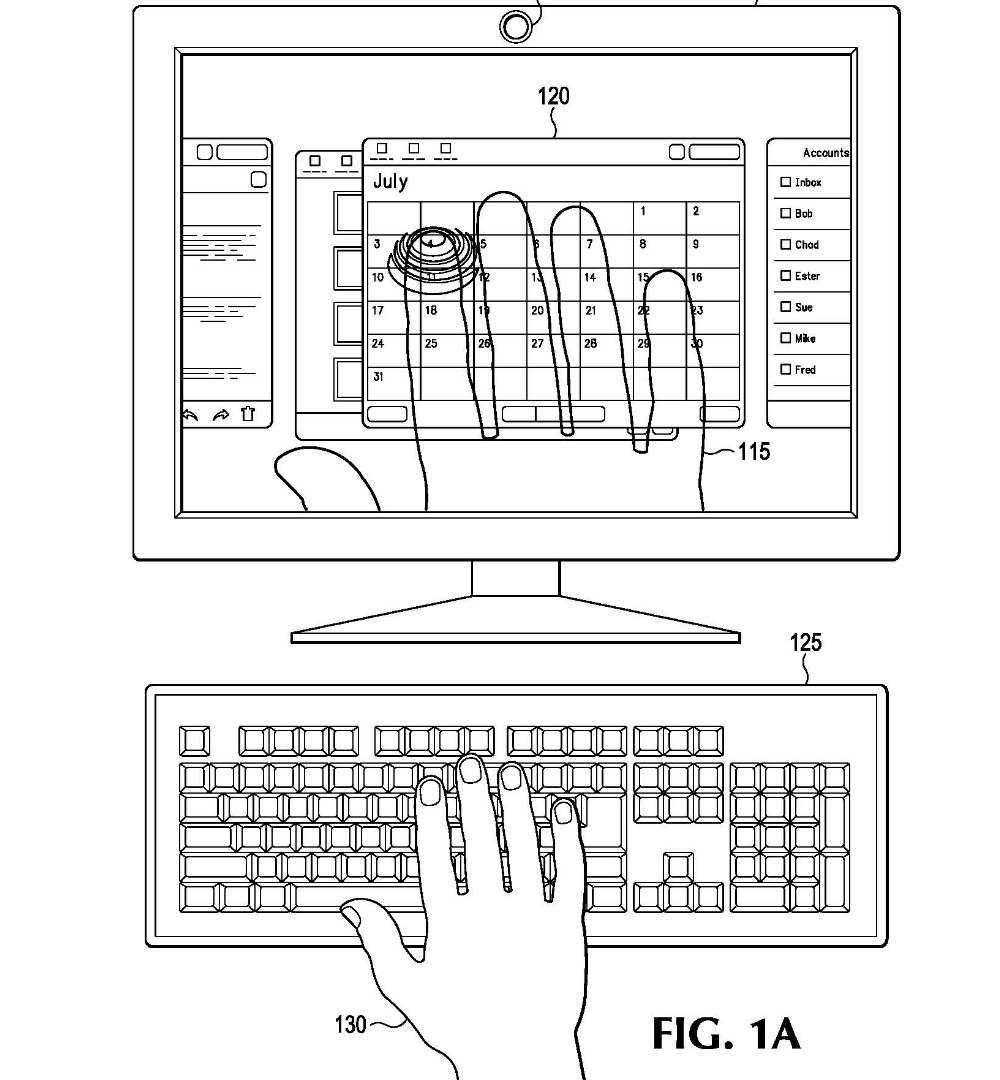 Patent drawing
Patent drawing Ghost Fingers poster
Ghost Fingers poster
Ghost Fingers (HP/Palm) | For our project "Ghost Fingers" we created multiple working prototypes for a novel interaction method that enables efficient and intuitive switching between keyboard and multi-touch input on systems where the display is out of arm's reach: check out the videos on the left for how this actually looks and feels. Ghost Fingers provided a translucent real-time visualization of the fingers and hands on the remote display, creating a closed interaction loop that enables direct manipulation even on remote displays. One of our prototypes consisted of a wireless keyboard with attached micro camera facing the keys, and which was used for two purposes: first, to determine the position of the user�s hand and fingers on the keyboard; and second, to provide a real-time translucent overlay visualization of hand and fingers over the remote UI. Our prototypes worked very well, and the user experience was quite amazing. We wrote a paper about the system, but not before patenting all novel elements in two separate patent applications. The paper got accepted for publication, and both patents got granted, yay! The patent applications were sold to Qualcomm, as part of a large transfer of IP. However, even though the two patents got granted by the USPTO (you can look this up on Public PAIR), Qualcomm decided to abandon them by not paying the fees. I contacted Qualcomm's lawyers about this unusual step, and they said it was simply a business decision. Too bad! On the positive side, this IP is now publicly available, and is not protected, so a forward thinking company could create a product based on the descriptions in the two patent applications. Year: 2011 Status: concluded Domain: engineering Type: working demos, video 1, video 2, paper, poster, patent 1, patent 2 (both granted, but inactive) Position: project and team lead Collaborators: Seung Wook Kim, Davide Di Censo
|  Video of PoC
Video of PoC Photos of PoC
Photos of PoC
Augmented Glass (HP/Palm) | The project "Augmented Glass" was an exploratory project about the interaction design, ergonomics, and usability of thin transparent handheld displays, a potentially whole new product category that could transcend tablets. It was inspired by our vision that a truly useful tablet device should be optical see-through (like seen in many Sci-Fi movies from Avatar to Iron Man), in order to accommodate super realistic and immersive mobile AR experiences. Our work was about exploring what kind of transparent handheld display was possible, with as little bezel (frame) as possible. Also, how would one hold such a thin slab of transparent material (handle). We created mechanical prototypes of tablet-sized glass panels (sheets of glass), modified with a coating that allowed back-projection from a tiny portable projector (pico projector). Two cameras would be included eventually, one pointing forward (scene camera), one towards the user to track their face and do view dependent rendering. Year: 2011 Status: concluded Domain: engineering Type: early PoC, brief video Position: project and team lead Collaborators: Davide Di Censo, Seung Wook Kim
|  Concept
Concept Early demo video
Early demo video
iVi: Immersive Volumetric Interaction (Samsung R&D) | This is one of the larger projects that I created for the HCI research team. The core idea was to invent and create working prototypes of future consumer electronics devices, using new ways of interaction, such as spatial input (i.e., gestural and virtual touch interfaces) and spatial output (i.e., view dependent rendering, position dependent rendering, 3D displays). Platform focus was on nomadic and mobile devices (from cellphones to tablets to laptops), novel platforms (wearables, AR appliances), and some large display systems (i.e., 3D TV). We created dozens of prototypes (some described below) covered by a large number of patent applications. A very successful demo of spatial interaction (nVIS) was selected to be shown at the prestigious Samsung Tech Fair 2009. One of our systems with behind-display interaction (DRIVE) got selected for the Samsung Tech Fair 2010. Yet another one used hybrid inertial and vision sensors on mobile devices for position dependent rendering and navigating in virtual 3D environments (miVON). Year: 2008 - 2010 Status: concluded Domain: engineering, management Type: portfolio management Position: project and group leader Collaborators: Seung Wook Kim (2008-2010), Francisco Imai (2008-2009), Anton Treskunov (2009-2010), Han Joo Chae (intern 2009), Nachiket Gokhale (intern 2010)
|  Video of interaction
Video of interaction Concept
Concept Prototype
Prototype Patent drawings
Patent drawings
DRIVE: Direct Reach Into Virtual Environment (Samsung R&D) | This novel interaction method allows users to reach behind a display and manipulate virtual content (e.g., AR objects) with their bare hands. We designed and constructed multiple prototypes: some are video see-through (tablet with an inline camera and sensors in the back), some are optical see-through (transparent LCD panel, depth sensor behind the device, front facing imager). The latter system featured (1) anaglyphic stereoscopic rendering (to make objects appear truly behind the device), (2) face tracking for view-dependent rendering (so that virtual content "sticks" to the real world), (3) hand tracking (for bare hand manipulation), and (4) virtual physics effects (allowing completely intuitive interaction with 3D content). It was realized using OpenCV for vision processing (face tracking), Ogre3D for graphics rendering, a Samsung 22-inch transparent display panel (early prototype), and a PMD CamBoard depth camera for finger tracking (closer range than what a Kinect allows). This prototype was demonstrated Samsung internally to a large audience (Samsung Tech Fair 2010), and we filed patent applications. (Note that anaglyphic rendering was the only available stereoscopic rendering method with the transparent display. Future systems will likely be based on active shutter glasses, or parallax barrier or lenticular overlays. Also note that a smaller system does not have to be mounted to a frame, like our prototype, but can be handheld.) Year: 2010 Status: concluded Domain: engineering Type: demo, paper (MVA2011), paper (3DUI2011), video Position: project and group leader Collaborators: Seung Wook Kim, Anton Treskunov
|  Video of demo
Video of demo Prototype
Prototype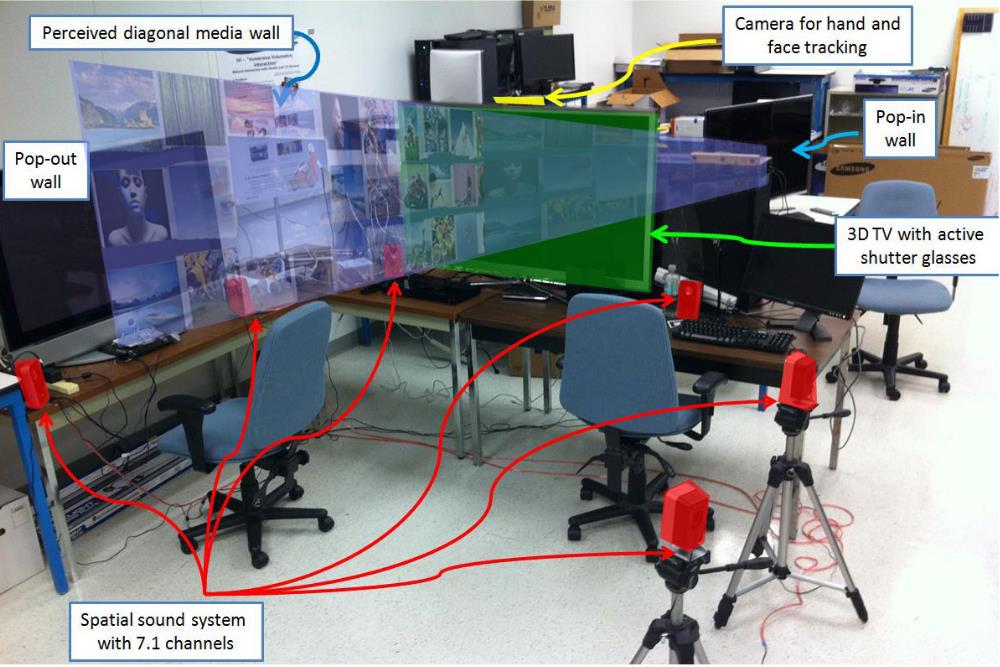 System setup
System setup
Spatial Gestures for 3DTV UI (Samsung R&D) | This project demonstrates new media browsing methods with direct bare hand manipulation in a 3D space on a large stereoscopic display (e.g., 3D TV) with 3D spatial sound. We developed a prototype on an ARM-based embedded Linux platform with OpenGL ES (visual rendering), OpenAL (spatial audio rendering), and ARToolKit (for hand tracking). The main contribution was to create multiple gesture interaction methods in a 3D spatial setting, and implement these interaction methods in a working prototype that includes remote spatial gestures, stereoscopic image rendering, and spatial sound rendering. Year: 2010 Status: concluded Domain: engineering Type: demo, video, report Position: project and group leader Collaborators: Seung Wook Kim, Anton Treskunov
|  Complete demo video
Complete demo video Curved displays
Curved displays Mobile & static
Mobile & static Walk-in sized
Walk-in sized
nVIS: Natural Virtual Immersive Space (Samsung R&D) | This project demonstrates novel ways to interact with volumetric 3D content on desktop and nomadic devices (e.g., laptop), using methods like curved display spaces, view-dependent rendering on non-planar displays, virtual spatial touch interaction methods, and more. We created a series of prototypes consisting of multiple display tiles simulating a curved display space (up to 6), rendering with asymmetric view frustum (in OpenGL), vision-based 6DOF face tracking (OpenCV based and faceAPI), and bare hand manipulation of 3D content with IR-marker based finger tracking. The system also shows a convergence feature, by dynamically combining a mobile device (e.g., cellphone or tablet) with the rest of the display space, while maintaining spatial visual continuity among all displays. One of the systems includes upper torso movement detection for locomotion in virtual space. In addition to desktop based systems, we created a prototype for public information display spaces, based on an array of 70-inch displays. All final systems were demonstrated Samsung internally at the Samsung Tech Fair 2009. Year: 2008-2010 Status: concluded Domain: engineering Type: demos, videos, technical reports [CHI 2010 submission], patents Position: project and group leader Collaborators: Seung Wook Kim, Anton Treskunov
|  Concept (2008)
Concept (2008) Multiple devices
Multiple devices Egomotion sensing
Egomotion sensing Phone demo
Phone demo
miVON: Mobile Immersive Virtual Outreach Navigator (Samsung R&D) | This project is about a novel method for interacting with 3D content on mobile platforms (e.g., cellphone, tablet, etc.), showing position-dependent rendering (PDR) of a 3D scene such as a game or virtual world. The system disambiguates shifting and rotating motions based on vision-based pose estimation. We developed various prototypes: a UMPC-version using optical flow only for pose estimation and a Torque3D game engine, a netbook based prototype that used up to four cameras to disambiguate imager-based 6DOF pose estimation, and a cellphone based prototype that combined inertial and vision based sensing for 6DOF egomotion detection (see videos on the left). Multiple patents were filed, and our code base was transferred to the relevant Samsung business units. Year: 2008-2010 Status: concluded Domain: engineering Type: demo, video, SBPA 2009 paper, patent Position: project and group leaderCollaborators: Seung Wook Kim, Han Joo Chae, Nachiket Gokhale
|  System concept
System concept Dome mockup
Dome mockup Nubrella mockup
Nubrella mockup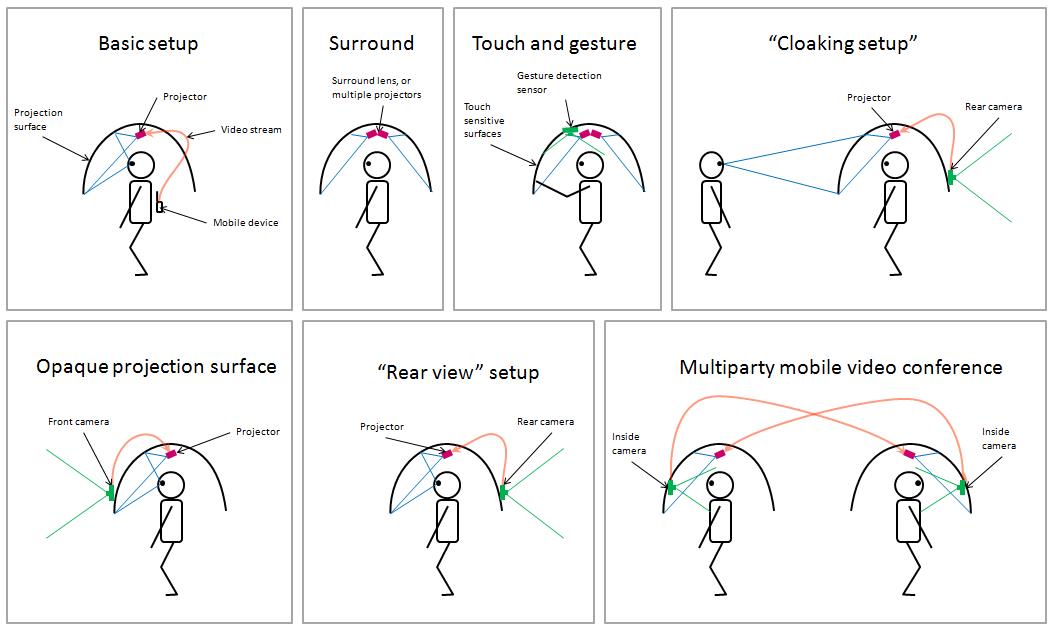 Patent drawings
Patent drawings
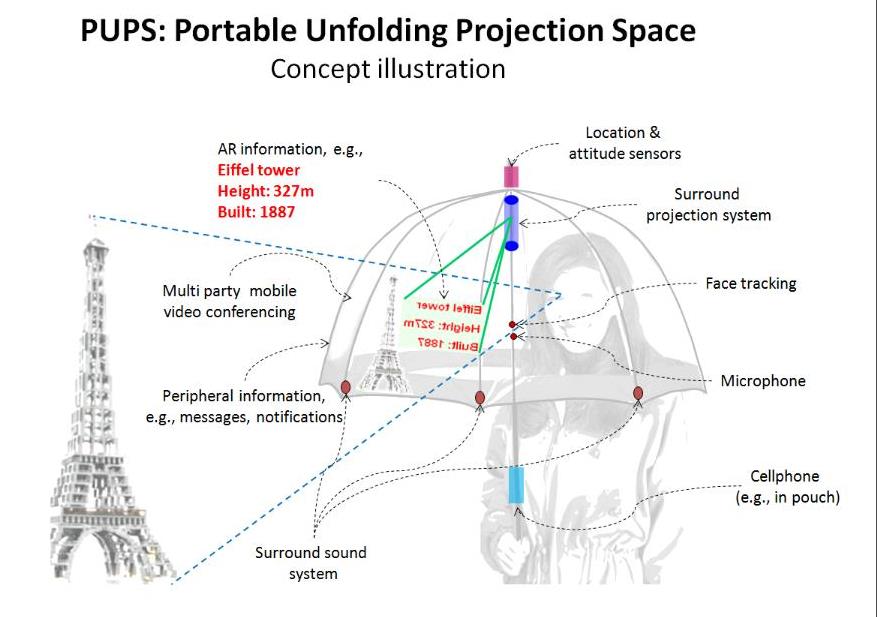
PUPS: Portable Unfolding Projection Space (Samsung R&D) | This project is about mobile projection display systems, to be used as a platform for AR systems, games, and virtual worlds. The technology is based on "non-rigid semi-transparent collapsible portable projection surfaces," either wearable or backpack mounted. It includes multiple wearable display segments and cameras (some inline with the projectors), and semi-transparent and tunable opacity mobile projection surfaces which are unfolding in an origami style, adjusting to the eye positions. There is a multitude of applications for this platform, from multiparty video conferencing (conference partners are projected around the user, and a surround sound system disambiguates the voices), to augmented reality applications (the display space is relatively stable with regards to the user, and AR content will register much better with the environment than handheld or head worn AR platforms), to cloaking and rear view applications. The portable display space is ideal for touch interactions (surface is at arm's length), and can track the user's hands (gestures) as well as face (for view dependent rendering). This early stage project focused on patenting and scoping of the engineering tasks, but did not go much beyond that stage. Year: 2008-2009 Status: concluded Domain: engineering Type: project plan, mockup, reports, patent application Position: project and group leader Collaborators: Seung Wook Kim, Francisco Imai
|  Pet robotics
Pet robotics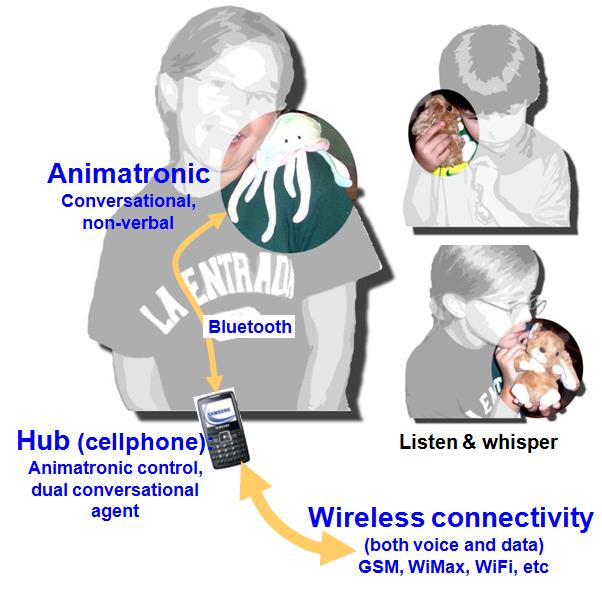 Animatronic mediator
Animatronic mediator
Pet Robotics and Animatronic Mediators (Samsung R&D) | Pets are shown to have a highly positive (therapeutic) effects on humans, but are not viable for all people (allergies, continued care necessary, living space restrictions, etc.) From a consumer electronics perspective, there is an opportunity to create robotic pets with high realism and consumer friendliness to fill in, and create high emotional attachment by the user. Our approach emphasizes the increase of lifelikeness of a pet robot, by employing (among others) emotional expressivity (expresses emotion with non-verbal cues, non-speech audio), soft body robotics (silent and sloppy actuator technologies; super soft sensor skin), and biomimetic learning (cognitive architecture and learning methods inspired by real pets). My in depth analysis of the field covered the hard technical problems to get to a realistic artificial pet, the price segment problem (gap between toy and luxury segments), how to deal with the uncanny valley, and many other issues. This early stage project focused on planning and project scoping, but did not enter engineering phase. However, it is related to my dissertation field of Autonomous Interactive Intermediaries. Year: 2008 Status: concluded Domain: engineering Type: report Position: project leader
|  Patent drawing 1
Patent drawing 1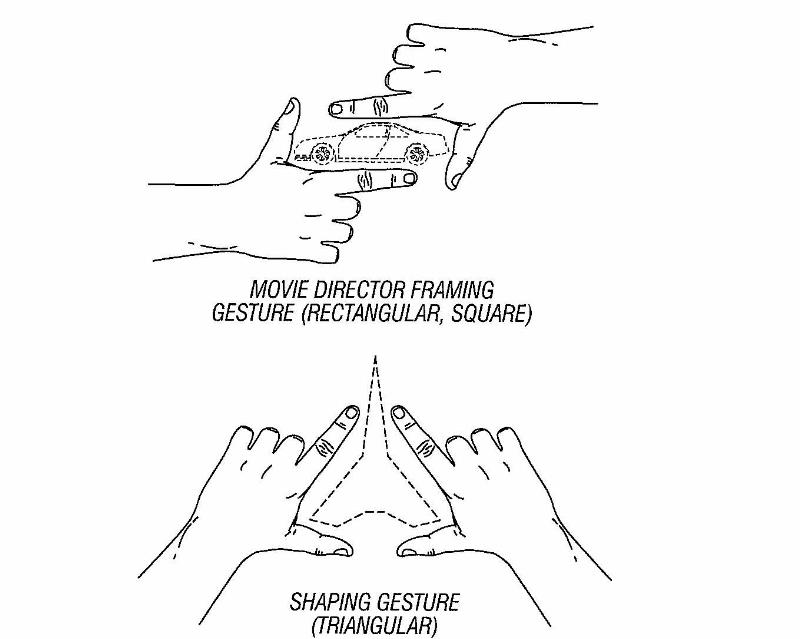 Patent drawing 2
Patent drawing 2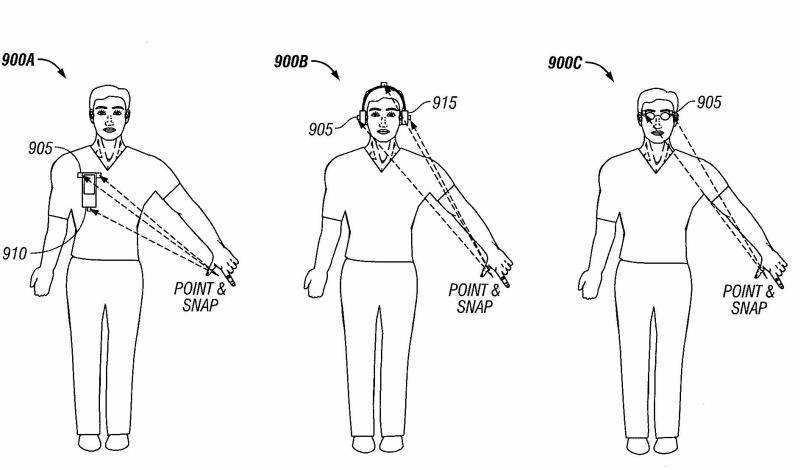 Patent drawing 3
Patent drawing 3
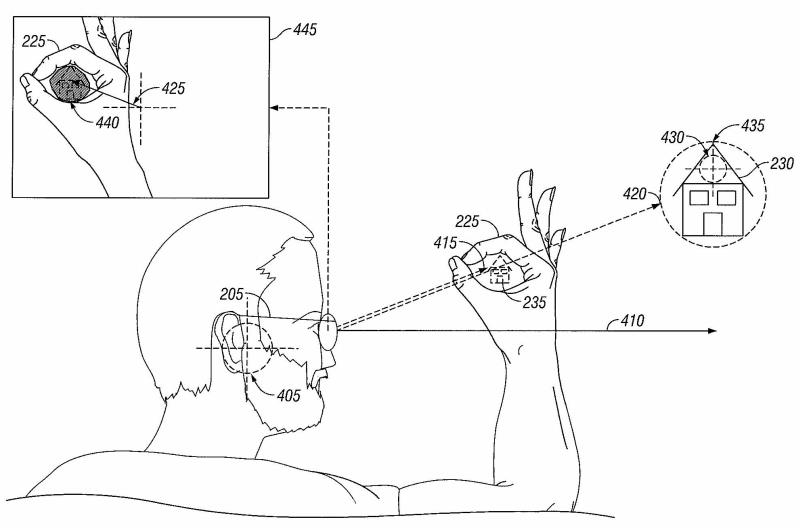
Googling Objects with Physical Browsing (Samsung R&D) | This project is about advanced methods of free-hand mobile searching. I developed two novel interaction methods for a localized in-situ search. The underlying idea is that instead of searching for websites, people who are not sitting in front of a desktop computer may search for information on physical objects that they encounter in the world: places, buildings, landmarks, monuments, artifacts, products—in fact, any kind of physical object. This "search in spatial context, right-here and right-now," or physical browsing, poses special restrictions on the user interface and search technology. I developed two novel core interaction methods, one based on manually framing the target object with hands and fingers (using vision processing to detect these gestures), the other based on finger pointing and snapping (using audio triangulation of the snapping sound) as an intuitive "object selection" method. The project yielded two granted patents. Year: 2006-2007 Status: concluded Domain: engineering Type: report, 2 granted patents: point and snap, finger framing Position: project leader Representative projects done at MIT |
| 


Autonomous Interactive Intermediaries (MIT Media Lab) | An Autonomous Interactive Intermediary is a software and robotic agent that helps the user manage her mobile communication devices by, for example, harvesting �residual social intelligence� from close by human and non-human sources. This project explores ways to make mobile communication devices socially intelligent, both in their internal reasoning and in how they interact with people, trying to avoid, e.g., that our advanced communication devices interrupt us at completely inappropriate times. My Intermediary prototype is embodied in two domains: as a dual conversational agent, it is able to converse with caller and callee—at the same time, mediating between them, and possibly suggesting modality crossovers. As an animatronic device, it uses socially strong non-verbal cues like gaze, posture, and gestures, to alert and interact with the user and co-located people in a subtle but public way. I have built working prototypes of Intermediaries, embodied as a parrot, a small bunny, and a squirrel—which is why some have called my project simply "Bunny Phone" or "Cellular Squirrel". However, it is more than just an interactive animatronics that listens to you and whispers into your ear: When a call comes in, it detects face-to-face conversations to determine social groupings (see Conversation Finder project), may invite input ("vetos") from the local others (see Finger Ring project), consults memory of previous interactions stored in the location (called Room Memory project), and tries to assess the importance of the incoming communication by conversing with the caller (see Issue Detection project). This is my main PhD thesis work. More... Year: 2002 - 2005 Status: dormant (not active as industry project, but I keep working on it) Domain: engineering Type: system, prototypes, paper, another paper,short illustrative videos, dissertation, demo video [YouTube], patent 1, patent 2 Press: many articlesPosition: lead researcher Advisor: Chris Schmandt PhD Thesis committee: Chris Schmandt, Cynthia Breazeal, Henry Lieberman Collaborators: Matt Hoffman (undergraduate collaborator)
| 

Prototype (top), dual PCB (middle), alignment example (bottom)
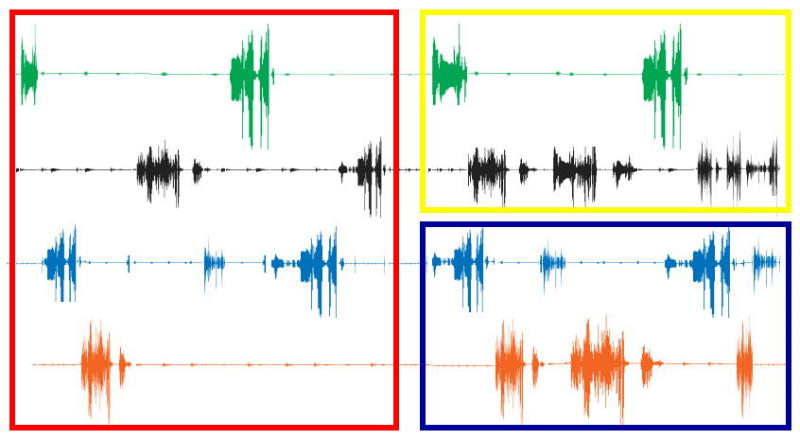
Conversation Finder (MIT Media Lab) | Conversation Finder is a system based on a decentralized network of body-worn wireless sensor nodes that independently try to determine with who the user is in a face-to-face conversation with. Conversational groupings are detected by looking at alignment of speech—the way we take turns when we talk to each other. Each node has a microphone and sends out short radio messages when its user is talking, and in turn listens for messages from close-by nodes. Each node then aggregates this information and continuously updates a list of people it thinks its user is talking to. A node can be queried for this information, and if necessary can activate a user's Finger Ring (see Finger Ring project). Depending on my conversational status, my phone might or might not interrupt me with an alert. This system is a component of my PhD work on Autonomous Interactive Intermediaries, a large research project in context-aware computer-mediated call control. Year: 2002 - 2005 Status: dormant Domain: engineering Type: system, prototypes, papers, brief explanatory video 2003 [YouTube] Position: lead researcher Advisor: Chris Schmandt Collaborators: Quinn Mahoney (undergraduate collaborator 2002-2003), Jonathan Harris (undergraduate collaborator 2002)
| 

Working prototype (top), wired rings used for user tests (middle, bottom)
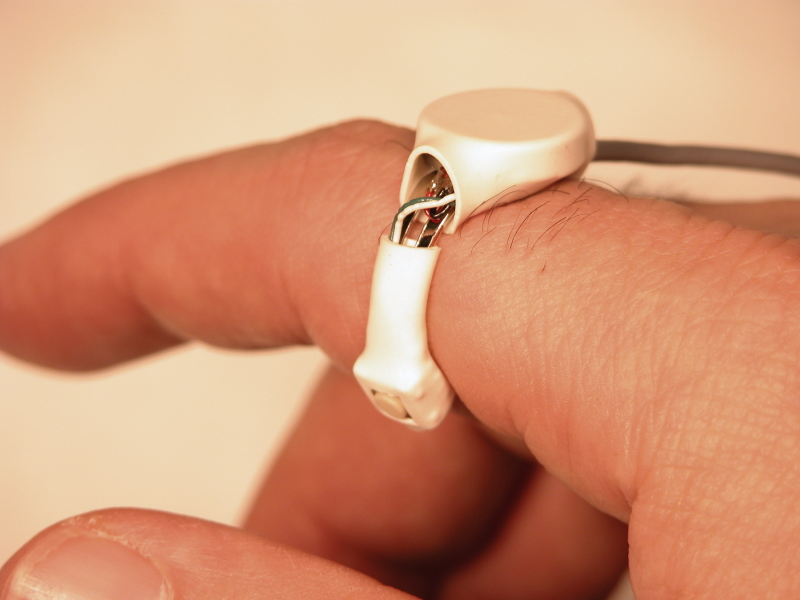
Finger Ring, "Social Polling" (MIT Media Lab) | Finger Ring is a system in which a cell phone decides whether to ring by accepting votes from the others in a conversation with the called party. When a call comes in, the phone first determines who is in the user's conversation (see Conversation Finder project). It then vibrates all participants' wireless finger rings. Although the alerted people do not know if it is their own cellphones that are about to interrupt, each of them has the possibility to veto the call anonymously by touching his/her finger ring. If no one vetoes, the phone rings. Since no one knows which mobile communication device is about to interrupt, this system of �social polling� fosters collective responsibility for controlling interruption by communication devices. I have found empirical evidence that significantly more vetoes occur during a collaborative group-focused setting than during a less group oriented setting. This system is a component of my PhD work on Autonomous Interactive Intermediaries, a large research project in context-aware computer-mediated call control. Year: 2002 - 2005 Status: dormant Domain: engineering Type: system, prototypes, paper Position: lead researcher Advisor: Chris Schmandt
|
Issue Detection (MIT Media Lab) | Issue Detection is a system that is able to assess in real-time the relevance of a call to the user. Being part of a conversational agent that picks up the phone when the user is busy, it engages the caller in a conversation using speech synthesis and speech recognition to get a rough idea for what the call might be about. Then it compares the recognized words with what it knows about what is currently �on the mind of the user�. The latter is harvested continuously in the background from sources like the user's most recent web searches, modified documents, email threads, together with more long term information mined from the user's personal web page. The mapping process has several options in addition to literal word mapping. It can do query extensions using Wordnet as well as sources of commonsense knowledge. This system is a component of my PhD work on Autonomous Interactive Intermediaries, a large research project in context-aware computer-mediated call control. Year: 2002 - 2005 Status: dormant Domain: engineering Type: system Position: lead researcher Advisor: Chris Schmandt
| 
Illustration of channel sequence
Active Messenger (MIT Media Lab) | Active Messenger (AM) is a personal software agent that forwards incoming text messages to the user's mobile and stationary communication devices such as cellular phones, text and voice pagers, fax, etc., possibly to several devices in turn, monitoring the reactions of the user and the success of the delivery. If necessary, email messages are transformed to fax messages or read to the user over the phone. AM is aware of which devices are available for each subscriber, which devices were used recently, and if a message was received and read by the user by exploiting back-channel information and by inferring from the users communication behavior over time. The system treats filtering as a process rather than a routing problem. AM is up and running since 1998, serving between 2 and 5 users, and has been refined over the last 5 years in a tight iterative design process. This project started out as my Master's thesis at the MIT Media Lab (finished 1999), but has been continued until the present time. More... Year: 1998 - 2005 Status: system stable (was in continuous use until 2007 or 2008!) Domain: engineering Type: system, thesis, paper (HCI), paper (IBM), tech report Position: lead researcher Advisor: Chris Schmandt
| 

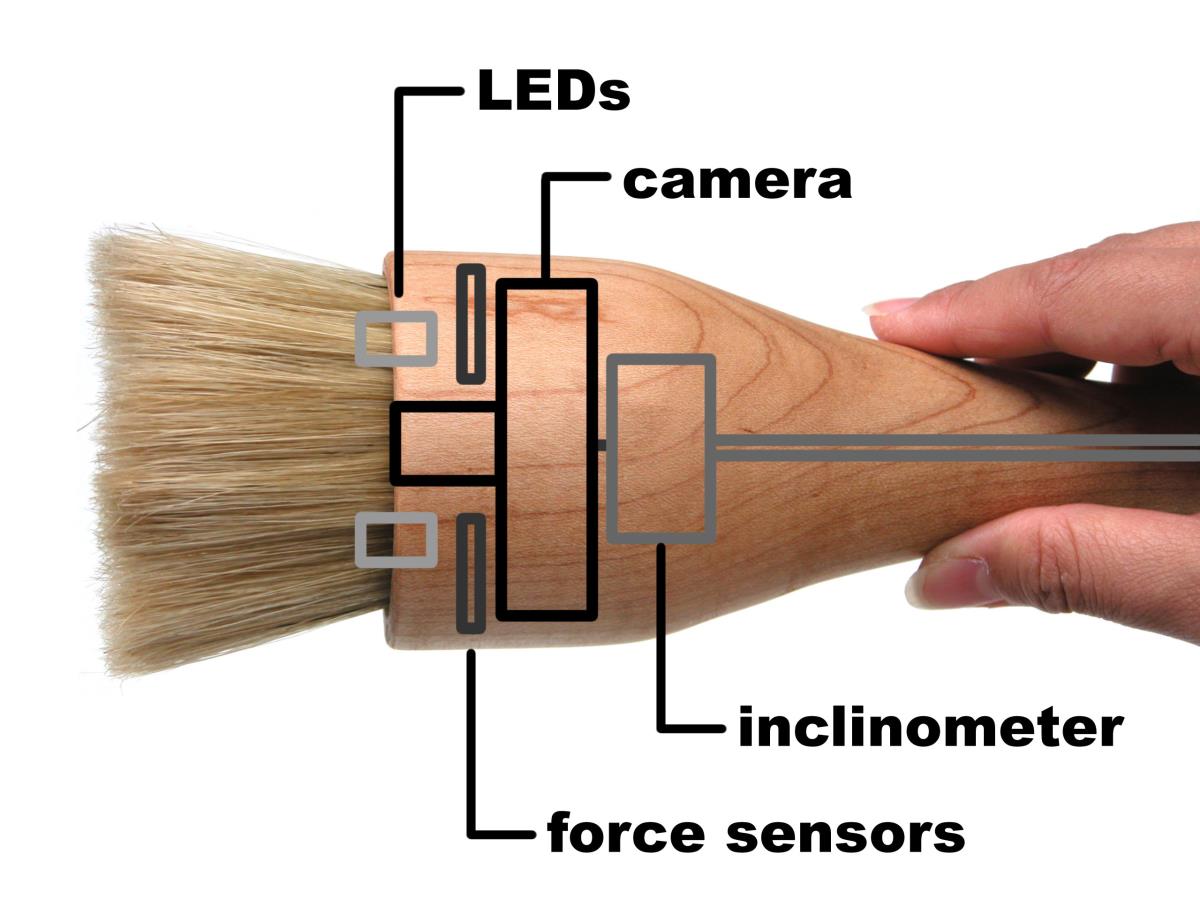

I/O Brush (MIT Media Lab) | I/O Brush is a new drawing tool to explore colors, textures, and movements found in everyday materials by "picking up" and drawing with them. I/O Brush looks like a regular physical paintbrush but has a small video camera with lights and touch sensors embedded inside. Outside of the drawing canvas, the brush can pick up color, texture, and movement of a brushed surface. On the canvas, artists can draw with the special "ink" they just picked up from their immediate environment. I designed the electronics on the brush (sensors, etc), the electronics �glue� between the brush and the computers, and wrote the early software. This project is the PhD work of Prof. Kimiko Ryokai, and has been presented at many events, including a 2-year interactive exhibition at the Ars Electronica Center in Linz, Austria. More... Year: 2003 - 2005 Status: active Domain: engineering Type: system, prototypes, paper, paper (design), video [MPEG (27MB)] [MOV (25MB)] [YouTube], manual, handling instructions Position: collaboratorCollaborators: Kimiko Ryokai (lead researcher), Rob Figueiredo (undergraduate collaborator), Joshua Jen C. Monzon (undergraduate collaborator) Advisor: Hiroshi IshiiEarly projects at MIT and before |
| 

Robotic F.A.C.E. (MIT Media Lab) | Robotic F.A.C.E., which stands for Facial Alerting in a Communication Environment, explored the use of a physical object in the form of a face as a means of user interaction, taking advantage of socially intuitive facial expressions. We have built an interface to an expressive robotic head (based on the mechanics of a commercial robotic toy) that allows the use of socially strong non-verbal facial cues to alert and notify. The head, which can be controlled via a serial protocol, is capable of expressing most basic emotions not only in a static way, but also as dynamic animation loops that vary some parameter, e.g., activity, over time. Although in later projects with animatronic components (Robotic P.A.C.E., Autonomous Interactive Intermediaries) I did not reverse engineer a toy interface anymore, the experience gained with this project was very valuable. More... Year: 2003 - 2004 Status: done Domain: engineering Type: system Position: lead researcher Collaborators: Mark Newman (undergraduate collaborator)
| 

Robotic P.A.C.E. (MIT Media Lab) | The goal of the Robotic P.A.C.E. project was to explore the use of a robotic embodiment in the form of a parrot, sitting on the user's shoulder, as a means of user interaction, taking advantage of socially intuitive non-verbal cues like gaze and postures. These are different from facial expressions (as explored in the Robotic F.A.C.E. project), but at least as important as them for grabbing attention and interrupting in a socially appropriate way. I have built an animatronic parrot (based on a hand puppet and commercially available R/C gear) that allows the use of strong non-verbal social cues like posture and gaze to alert and notify. The wireless parrot, which can be controlled from anywhere by connecting to a server via TCP which in turn connects to a hacked R/C long range transmitter, is capable of quite expressive head and wing movements. Robotic P.A.C.E. was a first embodiment for a communication agent that reasons and acts with social intelligence. Year: 2003 - 2004 Status: done Domain: engineering Type: system, illustrative video (2 minutes) [ Quicktime 7,279kb] [YouTube] Position: lead researcher
| 

Tiny Projector (MIT Media Lab) | Mobile communication devices get smaller and smaller, but we'd prefer if the displays would get larger instead. The solution to this dilemma is to add projection capabilities to the mobile device. The basic idea behind TinyProjector was to create the smallest possible character projector that can be either integrated into mobile devices like cellphones, or linked wirelessly via protocols like Bluetooth. During this 2-year project, I have built ten working prototypes; the latest one uses eight laser diodes and a servo-controlled mirror that "paints" characters onto any surface like a matrix printer. Because of the laser light, the projection is highly visible even in daylight and on dark backgrounds. More... Year: 2000 - 2002 Status: done Domain: engineering Type: prototypes, report Position: lead researcher
| 
2-way pagers like this were used for the Knothole system
Knothole (MIT Media Lab) | Knothole (KH) uses mobile devices such as cellphones and two-way pagers as mobile interfaces to our desktop computers, combining PDA functionality, communication, and Web access into a single device. Rather than put intelligence into the portable device, it relies on the wireless network to connect to services that enable access to multiple desktop databases, such as your calendar and address book, and external sources, such as news, weather, stock quotes, and traffic. In order to poll a piece of information, the user sends a small message to the KH server, which then collects the requested information from different sources and sends it back as a short text summary. Although development of KH has finished 1998, it is currently used by Active Messenger, which it enhances and with which it interacts seamlessly. More... Year: 1997 - 1998 Status: system stable and in continuous use Domain: engineering Type: system, prototypes, paper (related) Position: lead researcher Advisor: Chris Schmandt
| 

Early prototype (top), later designs (middle, bottom)
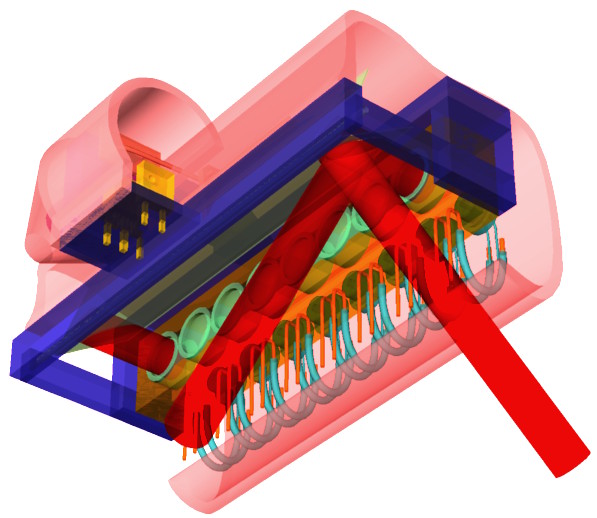
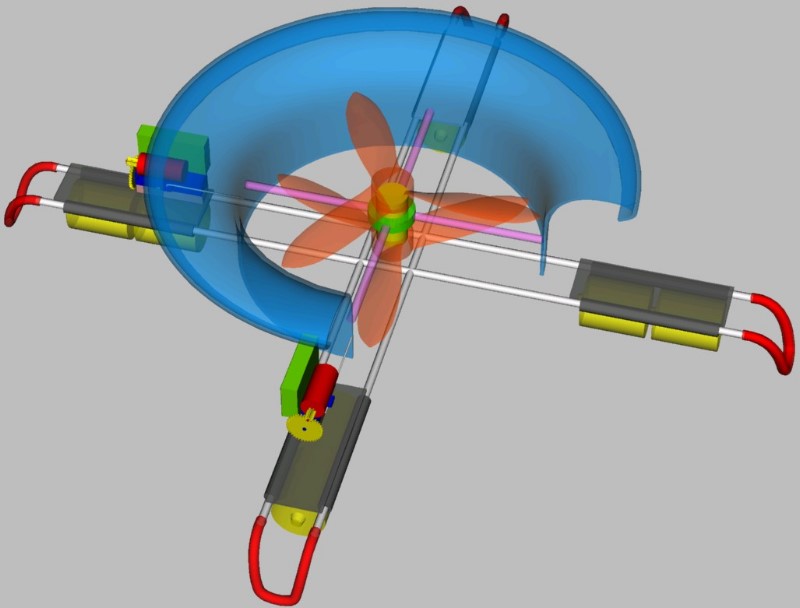
Free Flying Micro Platforms, "Zero-G Eye" (MIT Media Lab) | A Free Flying Micro Platform (FFMP) is a vision for small autonomously hovering mobot with a wireless video camera that carries out requests for aerial photography missions. It would operate indoors and in obstacle rich areas, where it avoids obstacles automatically. Early FFMPs would follow high level spoken commands, like "Go up a little bit, turn left, follow me, and would try to evade capture. Later it would understand complex spoken language such as "Give me a close up of John Doe from an altitude of 3 feet" and would have refined situational awareness. The Zero-G Eye is a first implementation of a FFMP that was built to explore ways of creating an autonomously hovering small device. The sensor-actuator loop is working, but flight times were highly constrained because of a too low lift-to-weight ratio. Later prototypes are in different planning stages, and profit from experiences made with earlier devices. As a side note, I have been virtually obsessed with small hovering devices for a very long time already, and have designed such devices since I was 12 years old. More... Year: 1997 - 2001 Status: prototypes developed; project dormant Domain: engineering Type: prototypes, report 1, report 2, report 3, paper, paper (related) Position: lead researcher
|  One of the early platforms
One of the early platforms
Autonomous Helicopter Robot (MIT Media Lab) | The MIT Aerial Robotics Club advanced the field of Aerial Robotics within the MIT community through the physical construction of flying robots. It was the intention of this Club to assist its members to learn about the details of constructing Aerial Robots by active participation in competitions and projects which can be solved or will benefit by the use of autonomous flying vehicles. Over the years, the team built several aerial robots based on large R/C controlled helicopters. For a brief time, I was part of the GNC/Ground Station group, and my job was testing, calibration, and integration of the compass module. Year: 1998 - 1999 Status: club discontinued Domain: engineering Type: system, prototypes, paper Position: collaborator of MIT Aerial Robotics Club Collaborators: many
| 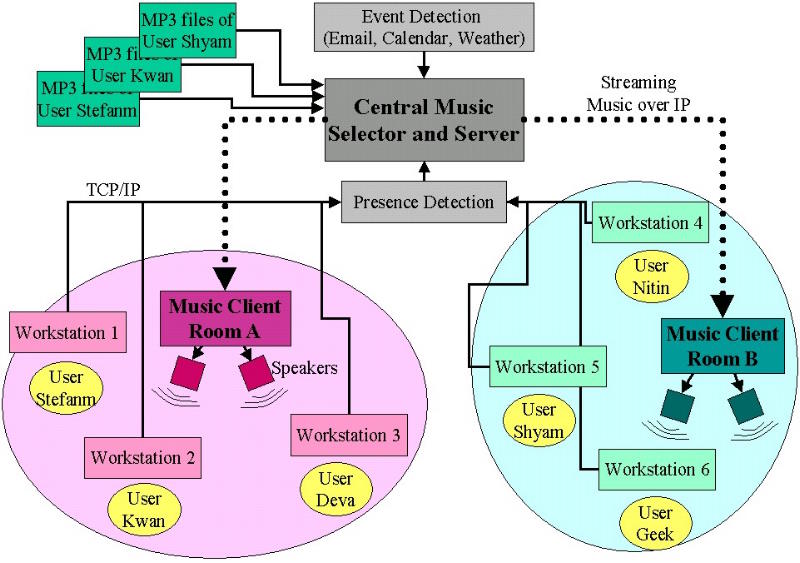
ASSOL (Adaptive Song Selector Or Locator) (MIT Media Lab) | The Adaptive Song Selector Or Locator (ASSOL) is an adaptive song selection system that dynamically generates play lists from MP3 collections of users that are present in a public space. When a user logs into a workstation, the ASSOL server is notified, and the background music that is currently played in this space is influenced by the presence of the new user and her musical preferences. Her preferences are simply extracted from her personal digital music collection, which can be stored anywhere on the network and are streamed from their original location. A first time user merely has to tell the ASSOL system where her music files are stored. From then on, the play lists are compiled dynamically, and adapt to all the users in a given area. In addition, the system has a Web interface that allows users to personalize certain songs to convey certain information and alert them without interrupting other people in the public space. More... Year: 2000 Status: done Domain: engineering Type: system, prototype, report Position: researcher Collaborators: Kwan Hong Lee (co-researcher)
| 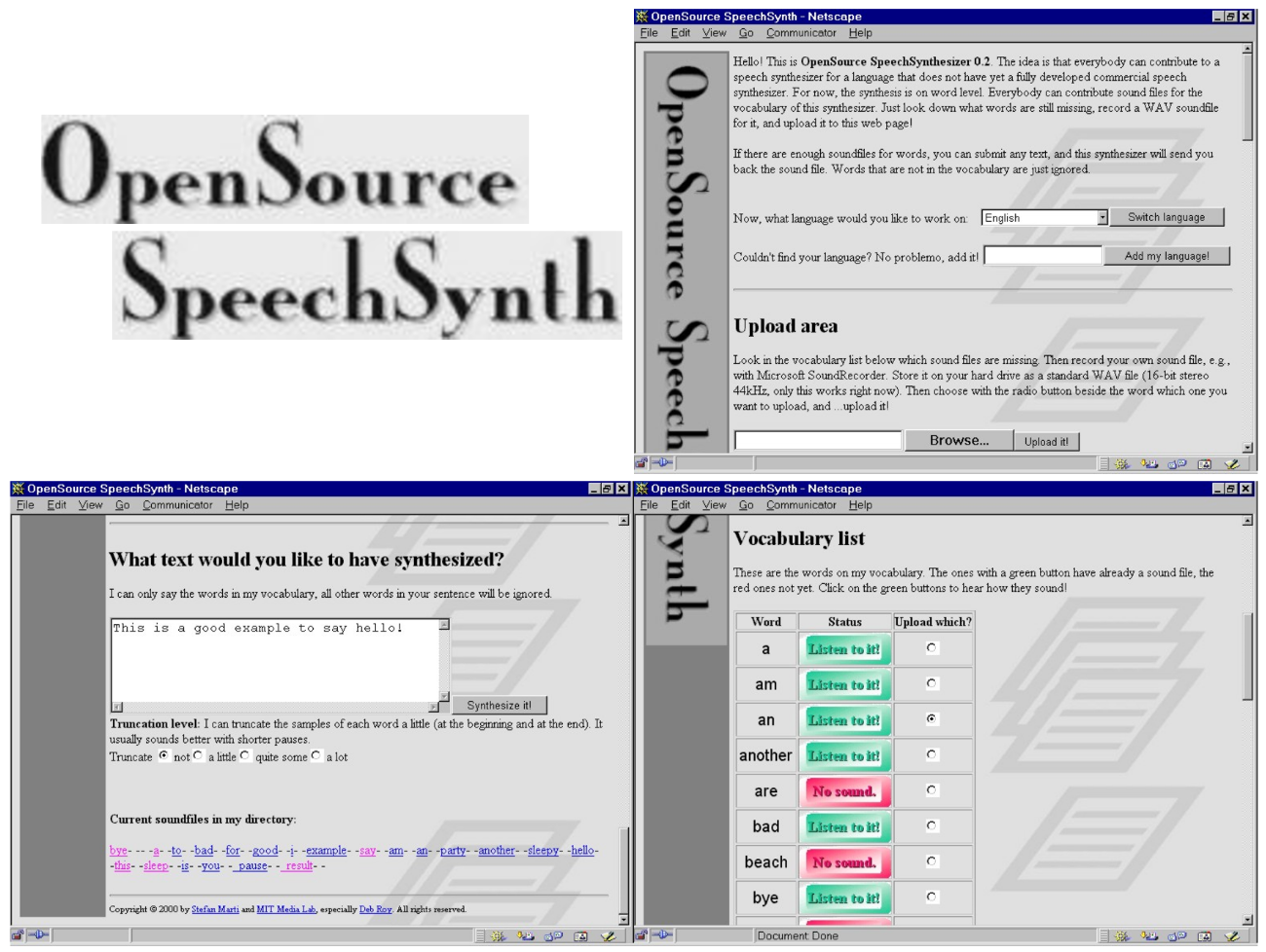
OpenSource SpeechSynth (MIT Media Lab) | The OpenSource SpeechSynth (OSSS) is a purely Web based text-to-speech synthesizer for minority languages, for which no commercial speech synthesizer software is available, e.g., Swiss German. It is based on a collaborative approach where many people contribute a little, so that everybody can profit from the accumulated resources. Its Web interface allows visitors to both upload sound files (words), as well as synthesize existing text. The speech synthesizing method used in this project is word based, which means that the smallest sound units are words. Sentences are obtained by waveform concatenation of word sounds. Due to the word concatenation approach, the OSSS works with any conceivable human language. It currently lists 90 languages, but users can easily add a new language if they wish, and then start adding word sounds. During the 4 years the OSSS is online, it has been tested by many Web visitors, specifically by the Lojban community. More... Year: 2000 - 2001 Status: done; up and running Domain: engineering Type: system, report Position: lead researcher
| 


Various weather conditions
WeatherTank (MIT Media Lab) | WeatherTank is a tangible interface that looks like a tabletop sized vivarium or a diorama, and uses everyday weather metaphors to present information from a variety of domains, e.g., "a storm is brewing" for increasingly stormy weather, indicating upcoming hectic activities in the stock exchange market. WeatherTank represents such well-known weather metaphors with desktop sized but real wind, clouds, waves, and rain, allowing users to not only see, but also feel information, taking advantage of our skills developed through our lifetimes of physical world interaction. A prototype was built that included propellers for wind, cloud machines, wave and rain generators, and a color-changing lamp as sun mounted on a rod that can be used to move the sun along an arc over the tank, allowing the user to manipulate the time of day. Year: 2001 Status: done Domain: engineering Type: system, report (short), report, video of demo (1:14) [YouTube], unedited demo video (18.5 minutes) [RealVideo] [YouTube] Position: researcherCollaborators: Deva Seetharam (co-researcher)
|  Screenshot of UI
Screenshot of UI
Impressionist visualization of online communication (MIT Media Lab) | This system provides an intuitive, non-textual representation of online discussion. In the context of a chat forum, all textual information of each participant is transformed to a continuous stream of video. The semantic content of the text messages is mapped onto a sequence of videos and pictures. The mapping is realized on the side of the receiver, because a simple text line like "I love cats" means different things to different people. Some would associate this with an ad for cat food, some other would be more negative because they dislike the mentality of cats and would therefore see pictures like a dog chasing a cat. For this purpose, each participant has a personal database of semantic descriptions of pictures and videos. If the participant scans the messages of a group, this textual information is transformed automatically to a user specific multiple stream of video. These video snippets have purely connotative meanings. I have built a proof-of-concept system with live video streams. More... Year: 1998 Status: done Domain: engineering, art installation Type: system, report Position: lead researcher
| 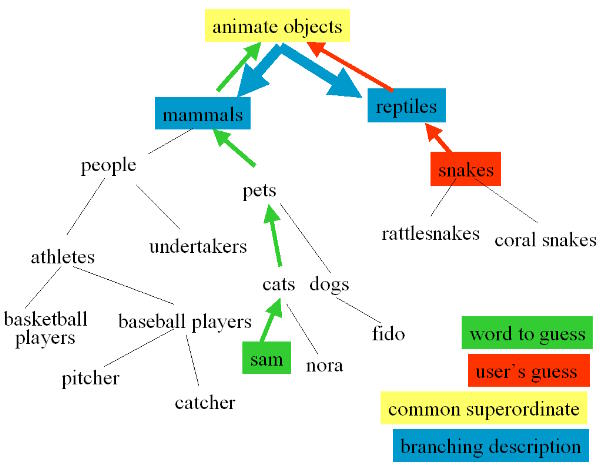 System reasoning tree
System reasoning tree Game example
Game example
Daboo (MIT Media Lab) | Daboo is a real time computer system for the automatic generation of text in the specific context of the word guessing game Taboo. To achieve the game�s goal—let the user guess a word as fast as possible without using certain taboo word—our system uses sophisticated algorithms to model user knowledge and to interpret semantically the user input. The former is very important to gradually enhance the performance of the system by adapting to the user's strongest "context" of knowledge. The latter helps bridge the gap between a guess and the actual word to guess by creating a semantic relationship between the two. For this purpose we rely on the semantic inheritance tree of WordNet. Daboo acts effectively as the clue giving party of a Taboo session by interactively generating textual descriptions in real time. More... Year: 1997 Status: done Domain: engineering Type: system, report Position: researcher Collaborators: Keith Emnett (co-researcher)
|  Illustration of relationships between core parameters, immediacy of communication channel, and user preference for communication channel
Illustration of relationships between core parameters, immediacy of communication channel, and user preference for communication channel
Psychological Impact of Modern Communication Technologies (University of Bern) | In this two-year study, I examined both the communicative behavior in general and the use of communication technologies of eight subjects in detail using extensive problem-centered interviews. From the interview summaries, a general criterion for media separation was extracted, which allows the systematic separation of all media into two groups: on one side the verbal-vocal, realtime-interactive, and non-time-buffered media like telephone, intercom, and face-to-face communication; on the other side the text-based, asynchronous, and time-buffering media like letter, telefax, and email. The two media answering machine and online chatting (realtime communication via computer monitor and keyboard) occupy exceptional positions because they cannot be assigned to either group. Therefore, these two media were examined in detail. Through analyzing them under the aspects of both a semiotic ecological approach and a privacy regulation model, important characteristics and phenomena of their use can be explained, and future trends be predicted. This work was part of my first Master's thesis in Psychology. Year: 1993 Status: done Domain: psychology Type: study, thesis, paper Position: researcher Advisor: Urs Fuhrer
|  Title page of the 163-page report on the main results of the study
Title page of the 163-page report on the main results of the study
Influence of Video Clip on Perception of Music | (University of Bern) This study explored the question if music is perceived and rated differently when presented alone versus when presented together with a promotional video clip. Thirty-six subjects filled out semantic differentials after having listened to tree different songs, each under one of the following conditions: the song was presented without video; the song was presented with the corresponding promotional video clip; the song was presented with random video. We found that subjects instructed to evaluate music do this in similar ways, independent from the presence of a matching or mismatching video clip. However, presenting a song together with a corresponding video clip decreases the possibility for the listeners/viewers to interpret the music in their own way. Furthermore, our data suggests that it is difficult and perhaps arbitrary to rate an incompatible or unmotivated music video mix, and that an appropriate video clip makes the "meaning" of the song more unequivocal. Year: 1989 Status: done Domain: psychology Type: study, report Position: researcher Advisor: Alfred Lang Collaborators: Fränzi Jeker und Christoph Arn (co-researchers)
|  Main data table showing the self-report real-time user behaviors
Main data table showing the self-report real-time user behaviors
Physiological Reactions to Modern Music (University of Bern) | This half-year study was motivated by our subjective experiences of a striking physiological reaction ("goose pimples") when listening to some modern pop and rock songs. We hypothesized that this physiological reaction, possibly caused by adrenaline, is the most important factor that determines if a song pleases an audience: it can lead to massive sales of records and high rankings on music charts. This project explores if an accumulation of such "pleasing spots" can be found when listening to specific songs. Our experimental results from 33 subjects prove the existence of such accumulations; additionally, we examined if we were able to predict these accumulations ahead of the experiment. Our results show also that we were able to predict them intuitively, but not all of them and not without errors. Only assumptions can be made about the criteria for passages that attracted attention as accumulations of conjectured physiological reactions. There are four factors: increase of musical density (for example, chorus passages); musical intensification of melody or harmony; increase of rhythm; increase of volume. Year: 1986 Status: done Domain: psychology Type: study, report Position: researcher Advisor: Alfred Lang Collaborators: Sibylle Perler, Christine Thoma, Robert Müller, and Markus Fehlmann (all co-researchers) | ||||||
){kind=link}
© 1997 - 2020 by Stefan Marti & MIT Media Lab. Send comments to:
 . Last updated: February 3, 2022
. Last updated: February 3, 2022home | research | writings | courses | personal