How often do we go to a colleague or local guru to solve a seemingly intractable bug? Frequently they can locate in minutes a bug that we've spent days trying to track down. There is evidence (Marc Eisenstadt this issue) that the mere act of explaining a bug to a colleague can help in the bug tracking process. Often though the programmers we'd like to talk to are not available. They may be at home or working at a different site. Or maybe there is no local guru or anyone using the same language/hardware platform etc. In these cases one might think that the internet might be useful, but so far it has been under-utilised. In this paper we will describe our approach to fostering debugging communities on the World Wide Web, enabling programmers to collaboratively debug programs synchronously and asynchronously.
Over the past couple of years we have seen a significant number of communities benefit by interacting over the net using newsgroups and Web pages. Net based debugging communities would profit from:
free help 24 hours a day,
potential access to world-class experts (e.g. the people who created the language), and
help for niche areas where a language or particular configuration is not widely used,
Although newsgroups exist for most of the popular computer languages they tend to discuss general issues and problems rather than specific bugs. In the next section we shall discuss the reasons for the non-existence of net based debugging communities. The following section describes our approach using a small scenario. We then briefly outline related work before concluding and specifying our future directions.
Given the potential benefits for programmers it may be slightly surprising that no internet based community for describing and fixing bugs has sprung up. The reason is that, using current technology, the effort of describing a bug and the effort of understanding someone else's bug is too large.
In order to describe a bug a programmer needs to describe the code, the point in the execution where the symptom occurs and the context. The context includes pieces of information that are necessary in order to replicate or understand the bug which are not directly contained within the code (e.g. Marc Eisenstadt reports in this issue on a program that 'only goes wrong on Wednesdays'). Currently, programmers are limited to impoverished descriptions in plain ASCII text.
One way of alleviating some of the above problems is by sharing code, but this is not easy. Running another programmer's code can be prevented by differences of:
platform - hardware or operating system;
language variation - many computer languages have different dialects or syntactic variants. Some languages are not fully specified and implementations may have differences in, for example, they way they handle graphics or foreign function calls;
version - the local version of required software may be out of date, or the shared code may require a feature from an older version;
libraries - the code may require a particular library to be installed;
configuration - the code may require a particular system configuration;
cpu speed/memory requirements - your machine may not have a high enough specification to run the code within a reasonable time, or to run the code at all;
commercial interests - the program may require 'commercially sensitive' modules which can not be released.
Our aim is to make it easy for programmers to swap bug descriptions around the world. This means that our system must be platform independent, run on relatively modest hardware, not require the exchange of source code and not require high bandwidth or synchronous communication.
In order to address the points raised above there are two main issues we need to consider: what exactly is going to be shared, and what mechanisms are required to support the sharing process. For the first issue we need to think about what a bug description is and what the debugging process involves. Essentially, a bug description is a description of a) what the program did, and b) what the program should have done. The debugging process involves two main tasks. The first task is to find the mismatches between a) and b). The second task is to locate the points in the source code which correspond to the mismatches. As eloquently argued in the introduction, Software Visualization (SV) techniques can aid in displaying the execution of a program. Our approach to b) is to allow programmers to annotate their visualizations using simple drawing and labelling tools.
How best to support the sharing process? If we can encode our annotated visualizations as HTML files and Java code then Web and Java technology will enable us to share these without any of the 'program difference' problems mentioned earlier. The remaining problem is to provide a framework which facilitates the generation of visualizations encoded as HTML and Java. We describe how we solved this in the next section.
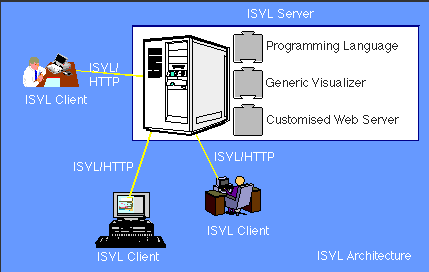
Our approach to solving the bug description sharing problem is the Internet Software Visualization Laboratory (ISVL). ISVL uses a client server architecture to deliver visualizations on any Java enabled Web browser. Figure 1 below shows the general framework.
Figure 1. The general architecture of the Internet Software Visualization Laboratory.
Using a Java enabled Web browser programmers can connect to the ISVL server and download the ISVL client. Using the client, programmers can upload and run their programs on the server and receive back a visualization. Programmers can also use the client to debug programs collaboratively. We shall give a short example of a collaborative debugging session in the following section. First we shall briefly describe the components of ISVL.
The ISVL server is composed of a customised Web server, a generic software visualizer and a specific programming language. The customised Web server is based on LispWeb [10] a specialised HTTP server written in Common Lisp. In addition to implementing the standard HTTP protocol, the LispWeb server offers a library of high-level Lisp functions to dynamically generate HTML pages, a facility for dynamically creating image maps, and a server-to-server communication method.
The generic visualizer is an extension of our framework for creating software visualizations called Viz [5]. Within the Viz framework, we consider program execution to be a series of history events happening to (or perpetrated by) players. To allow SV system builders considerable freedom, a player can be any part of a program, such as a function, a data structure, or a line of code. Each player has a name and is in some state, which may change when a history event occurs for that player. A player may also contain other players, enabling groups of players to be formed. History events are like Brown's [3] "interesting events" in BALSA-each event corresponds to some code being executed in the program or some data changing its value. These events are recorded in the history module, which allows them to be accessed by the user and "replayed." Events and states are mapped into a visual representation which is accessible to the end-user (the programmers who need to use the SV system, not the SV system builder). But the mapping is not just a question of storing pixel patterns to correspond to different events and states-we also need to specify different views, and ways of navigating around them. The main ingredients of Viz are:
Histories: a record of key events that occur over time as the program runs, with each event belonging to a player; each event is linked to some part of the code and may cause a player to change its state (there is also some pre-history information available before the program begins running, such as the static program source code hierarchy and initial player states).
Views: the style in which a particular set of players, states or events is presented, such as using text, a tree, or a plotted graph; each view uses its own style and emphasises a particular dimension of the data that it is displaying.
Mappings: the encodings used by a player to show its state changes in diagrammatic or textual form on a view using some kind of graphical language, typography, or sound; some of a player's mappings may be for the exclusive use of its navigators.
Navigators: the tools or techniques making up the interface that allows the user to traverse a view, move between multiple views, change scale, compress or expand objects, and move forward or backward in time through the histories.
The Viz framework is equally at home dealing with either program code or algorithms, since a player and its history events may represent anything from a low-level (program code) abstraction such as "invoke a function call" to a high level (algorithm) abstraction such as "insert a pointer into a hash table."
The mapping module within Viz has been interfaced with LispWeb so that plain ASCII representations are sent to the client thus reducing the required bandwidth.
A programming language is interfaced to Viz by inserting 'create player' and 'note interesting event' hooks. To date we have created over a dozen visualizations using Viz (see [5] for a sample).
On the client side a transformation module converts the ISVL HTTP stream into textual and graphical representations. These representations are then transformed and presented on the screen by the navigator. The user interacts with the visualization using the navigator. The navigator controls panning, zooming, local compression and expansion, and moving forward and backward in time through the program execution space.
We now describe our first system which is currently being used and evaluated within a teaching context: we are currently running an internet version of our Master's level Intensive Prolog course [7] using a visualization based on the Transparent Prolog Machine (TPM) [6]. In this section we shall describe an interaction between two hypothetical programmers Bill and Ingrid. Because the purpose of the scenario is to show how ISVL supports SV based collaborative debugging and not to show off the debugger itself we have deliberately chosen a trivial program. It should be noted however that ISVL contains numerous features which allow it to scale up to cope with arbitrarily large programs.
Figure 2 below shows a labelled figure describing the parts of
the ISVL Prolog client. A user can obtain the view below by typing
a query into the Prolog Query window (1). The result of the query
"NO" (indicating that the query has failed) and a TPM
style visualization are returned (2). The user can then step through
the execution using the  button in the control
panel until she reaches the point shown in figure 2. A fine-grained
view of the arrowed node can be obtained by clicking on the node
(3).
button in the control
panel until she reaches the point shown in figure 2. A fine-grained
view of the arrowed node can be obtained by clicking on the node
(3).
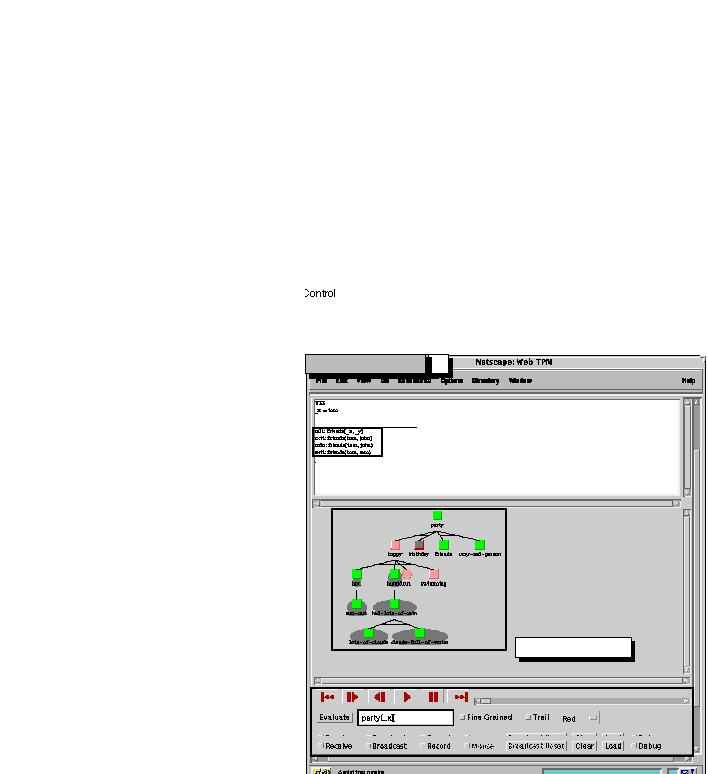
Figure 2. The ISVL Prolog client.
Bill is writing a sorting program called qsort, which sorts a number of unsorted elements, based on the quicksort algorithm. The quicksort algorithm works by splitting a list around an element into a list of lower numbers and a list of higher numbers which are then recursively sorted. The program should take an unsorted list and return a sorted list. Bill's current version is buggy and try as he might he can not find the root cause. Bill starts recording a movie by selecting the "Record" button in the control panel. He then carries out the following steps:
1. He clicks on the topmost qsort node which causes the fine-grained
informationcall: qsort((4, 1, 2, 3),
_ans)
exit: qsort((4, 1, 2, 3), (3, 1, 2, 4))
to appear in the fine-grained view window.
2. He then rings the top node in red with the mouse and inserts the top annotation "help! should be exit: qsort([4, 1, 2, 3], [1, 2, 3, 4])".
3. He then rings the lower qsort nodes in green and blue and adds the annotations "seems OK" and "seems ok too". The state of his screen at this stage is shown in figure 3 below.
4. He ends the recording session by selecting the "Record" button and when prompted names his movie can-anyone-help-with-a-buggy-quicksort.
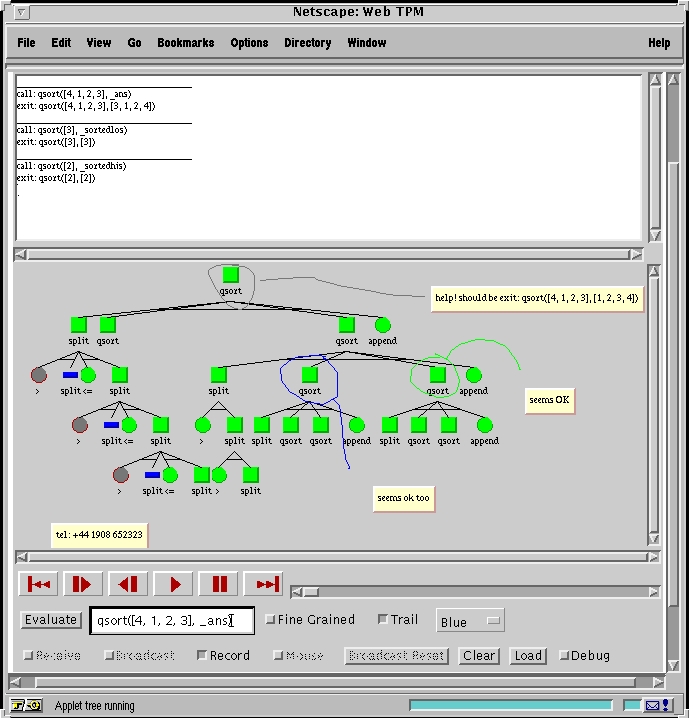
Figure 3. A snapshot from the movie left by Bill.
Some time later Ingrid looks up the Prolog movie database shown in figure 4 below, retrieves Bill's movie and plays through it. The interface for playing a movie is almost exactly the same for viewing visualizations except that the 'visualization steps' are primitive user actions (e.g. circling or labelling a node, clicking on a node) rather than steps within the program execution. She plays through the movie checking the fine-grained views of the three split nodes in the subtree to the left of the qsort node circled in blue (containing three generations and five nodes). Whilst checking these split nodes she finds the bug. Instead of leaving a movie for Bill she calls his number and they agree to start a synchronous collaborative session.
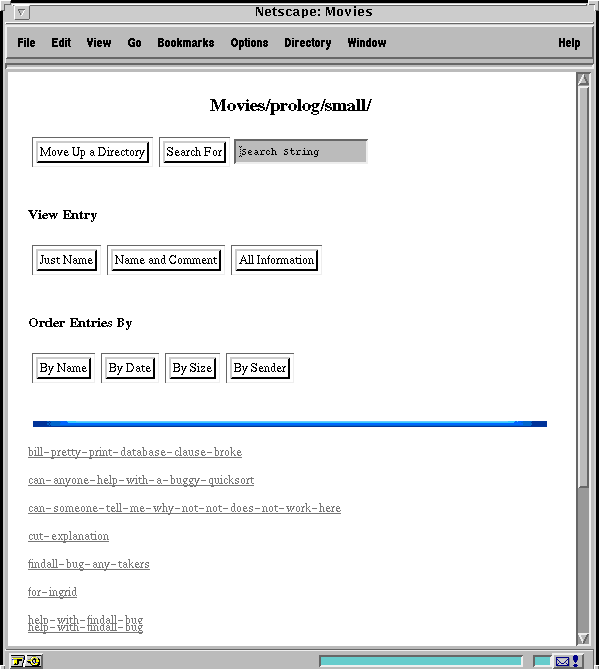
Figure 4. The ISVL movie database web page.
Bill puts his client into receive mode by selecting the "Receive" button in the control panel. Ingrid puts her client into broadcast mode by selecting the "Broadcast" button in the control panel. She loads Bill's code and runs it by typing the query into the query window and selecting evaluate. She then carries out the following steps to put her interface into the state shown in figure 5 below.
1. She hits the  button until the tree is
as below and then stops using the
button until the tree is
as below and then stops using the  button.
button.
2. She rings and annotates parts of the tree in the order of blue, red, yellow and white. Each time she does this she also brings up a fine-grained view, shown in the top window, of an appropriate split node.
Each interface action is replicated on Bill's client. After the session Bill fixes his bug and checks the new code on the server.
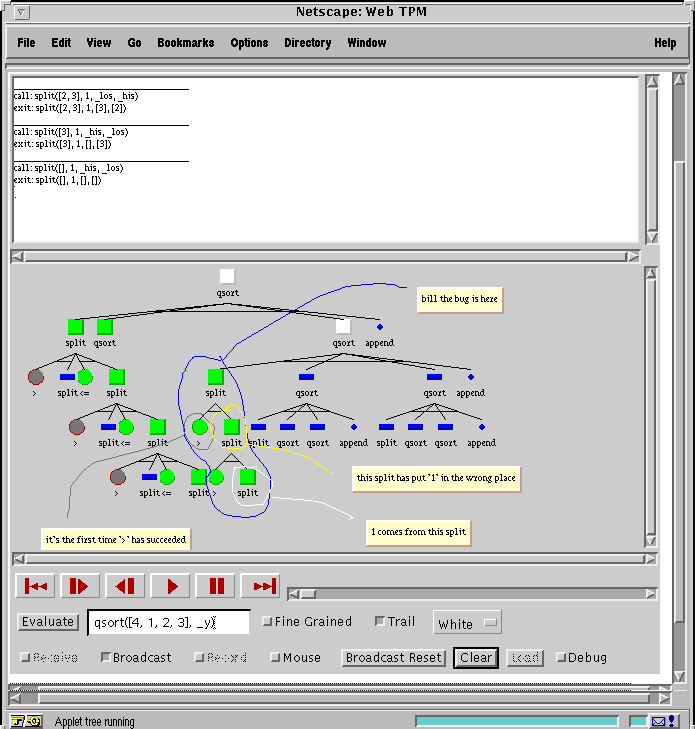
Figure 5. Ingrid's ISVL client after a collaborative
session with Bill.
Because ISVL uses Java based clients it gains all the benefits which Java brings to an application, namely:
the ability to run on multiple platforms,
the ability to run on low cost platforms (with the potential one day to run on set-top boxes and hand held devices),
radically lowering the effort of delivery, maintenance, version control and update shipment.
In addition to the above there are other design features which we have incorporated into ISVL to facilitate ease of use:
minimising bandwidth requirements - visualizations and broadcasts are encoded as plain ASCII,
minimising connect time - once a visualization has been delivered to a client all interactions are local, the only time a connection is left open is when a client is either in broadcast or receive mode,
minimising the use of the server - movies are plain HTML files with accompanying Java code and therefore do not require the ISVL server,
maximising control - movies are not just watch and see, as well as controlling speed of replay a programmer can obtain fine-grained views of nodes which weren't in the original movie.
As we stated earlier in this paper we are currently testing ISVL on an internet version of a master's programming course which has students within the US and Canada and a tutor situated in England. It is too early to draw any conclusions from this experiment, but we have expectations based on earlier experiments on internet teaching [12], as well as empirical studies of novice programmers using a variety of SV systems [9].
We believe that any programming community spread over distance or time will benefit from our approach. Exactly how the framework is used will depend on the community type. Currently, we believe that the dimensions which will determine use include:
openness - is membership of the community available to all programmers? are the activities of the community available for inspection? Two examples of communities which differ greatly on this dimension are academia and the military (in this case a secure intranet would be required),
size - obviously, the size of the community will shape use,
homogeneity - a community may be made of distinct subcommunities, each with its own agenda. The relationships between the subcommunities will be of importance. For example, software providers have a special relationship with their customers. Alternatively, a community may have a strong internal structure, for example a strictly hierarchical corporation, which influences communication.
The benefits for an individual programmer will depend on her role within a community. We expect programmers who are particularly isolated (e.g. a consultant working at a remote client site) or who are at the bottom of a learning curve (e.g. a new member of a software team) to benefit most.
Recent work within the Algorithm Animation community has lead to the creation of a number systems which allow pre-written animations to be viewed remotely. These systems primarily concentrate on delivering animations synchronously as part of a classroom style tutorial.
John Stasko has provided a facility (at http://www.cc.gatech.edu/stasko/cgi-bin/xtangoanim) where XTANGO [11] animations can be run on remotely. Although useful for quickly getting an overview of XTANGO's look and feel, which is the purpose of the facility, the system is restricted to X-Window systems and has scaling problems as all the work is carried out on a central server.
The Collaborative Active Textbooks (CAT) of Brown and Najork [4], is a web-based environment, which allows the same animation to be run simultaneously on a number of machines. Intended for classroom style teaching the view and speed of the animation can be controlled remotely by the tutor. This form of synchronous demonstration of programs is possible within ISVL, though within ISVL the animations are not canned, being created on the fly, from the program submitted.
The client-server architecture of ISVL is similar to that of Baker's Mocha system [1] whereby the bulk of the work is done on the server and the interface is created by a Java client. Like CAT Mocha is primarily designed for the synchronous delivery of algorithm animations.
What about voice I hear you ask? Programmers with ethernet links and a telephone can of course currently use voice with ISVL in a synchronous fashion and it is also possible to add links to .au files to within movies. We feel however that this has limitations as some programmers use a dial up modem (especially when at home) and .au files are large and not handled well on all platforms. In addition non-local phone calls are expensive! We are therefore planning to use the streaming audio system currently being constructed as part of the KMi Stadium [8]. KMi Stadium is a Java based application that explores the use of large-scale teleprescence focused on the broadcasting of realtime audio.
In his debugging environment for MRE Mike Brayshaw [2] described how a subpart of a visualization could be parameterised and stored away as a 'symptomatic agent' which could then be used to search within the execution space of future programs. We plan to enable programmers to use direct manipulation to capture parts their current visualization and to ask "has anyone else had a problem like this?" at which point an agent would search known movie databases for matching visualizations.
In addition to investigating other languages, such as Java, we are using the framework in a wider context to support collaborative case based engineering design and collaborative ontology browsing and editing.
The authors would like to thank Enrico Motta and Simon Buckingham Shum for providing valuable feedback on various drafts of this paper.
1. Baker, J. E., Cruz, I. F., Liotta, G. and Tamassia, R. Algorithm animation over the World Wide Web. In Proceedings of the International Workshop on Advanced Visual Interfaces, ACM Press, 1996.
2. Brayshaw, M. Information Management and Visualization for Debugging Logic Programs. Ph.D. Thesis, Human Cognition Research Laboratory, The Open University, Walton Hall, Milton Keynes, UK, 1994.
3. Brown, M.H. Algorithm Animation. ACM Distinguished Dissertations, MIT Press, New York, 1988.
4. Brown, M. H. and Najork, M. A. Collaborative Active Textbooks: A web-based algorithm animation system for an electronic classroom. SRC Research Report 142, Digital, 1996.
5. Domingue, J., Price, B. and Eisenstadt, M. Viz: a framework for describing and implementing software visualization systems. In Gilmore D. and Winder R. (eds) User-Centred Requirements for Software Engineering Environments, Springer-Verlag, 1992. pp. 197-212.
6. Eisenstadt, M. and Brayshaw, M. The Transparent Prolog Machine (TPM): an execution model and graphical debugger for logic programming. Journal of Logic Programming, 5,4 1988, 277-342.
7. Eisenstadt, M., Dixon, M. and Kriwaczek, F. Intensive Prolog. Milton Keynes, UK: Academic Press, 1988.
8. Eisenstadt, M., Buckingham Shum, S. and Freeman, A. KMi Stadium: Web-base Audio/Visual Interaction as Reusable Organisational Expertise. In proceedings of Workshop on Knowledge Media for Improving Organisational Expertise, 1st International Conference on Practical Aspects of Knowledge Management, Basel, Switzerland, 30-31 October, 1996. (Also available as Knowledge Media Institute Technical Report No. 31 http://kmi.open.ac.uk/techreports/kmi-tr-list.html. See also http://kmi.open.ac.uk/stadium).
9. Mulholland, P. A Principled Approach to the Evaluation of SV:
a case-study
in Prolog. In Software Visualization: Programming as a Multi-Media
Experience, Stasko, J., Domingue, J., Brown, M., and Price, B.
(eds) MIT Press, in press.
10. Riva, A. and Ramoni, M. LispWeb: a Specialised HTTP Server for Distributed AI Applications. Computer Networks and ISDN Systems, 28,7-11 (1996), 953-961.
11. Stasko, J. T. (1990) The Path-Transition Paradigm: A Practical Methodology for Adding Animations to Program Interfaces. Journal of Visual Languages and Computing, 1,3 (Sept. 1990) 213-236.
12. Watt, S. N. K. 1995 Teaching Through Electronic Mail, Knowledge
Media Institute Technical Report No. 15 http://kmi.open.ac.uk/techreports/kmi-tr-list.html.
September, 1995.
John Domingue has been working on software developement
environments for both novice and expert programmers for just over
a dozen years. Now working within the Knowledge Media Institute
at the Open University he is exploring ways in which Web technology
can aid in distance education and in the collaborative design
of complex artifacts. Email address: J.B.Domingue@open.ac.uk.
Web: http://kmi.open.ac.uk/~john/. Postal: Knowledge Media Institute,
The Open University, Walton Hall, Milton Keynes, MK7 6AA, UK.
Paul Mulholland has been working on the evaluation and
implementation of programming support tools for the past five
years, with particular emphasis on Software Visualization environments.
He is now working in the Knowledge Media Institute at the Open
University, on how the internet and various media can be used
to enhance the student learning experience. Email address: P.Mulholland@open.ac.uk.
Web: http://kmi.open.ac.uk/~paulm/. Postal: Knowledge Media Institute,
The Open University, Walton Hall, Milton Keynes, MK7 6AA, UK.